
はじめに
今回はAIイラストの追加学習の手法を比較をまとめます。
2023年03月前期の情報です。
この記事は、自分が「どれを使えばいい…?」 と調べた際、
ネットの情報が散らかりすぎてるのでまとめた記事です。
私が、全てを完全に理解+検証してるわけではないので注意。
図解について
本記事では、分かりやすさ優先でこちらの図に変更を加えたものを使います。
…が、この図は厳密な処理とは少し異なるので注意。
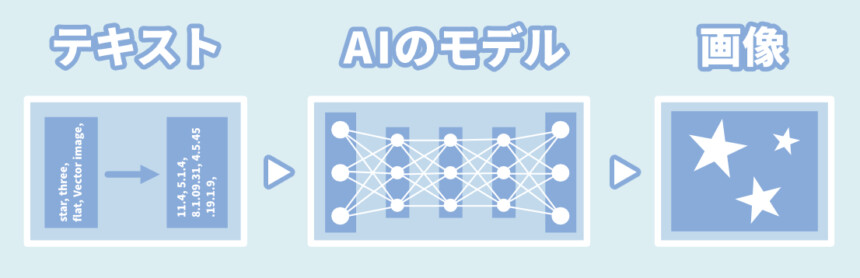
図的に正しく表記すると、こちらになります。
図はあくまで「イメージ」するためのものとしてお使いください。
キャラ学習の手法
2023年3月での学習手法は主に8つ。
・Dreambooth
・Textual Inversion
・LoRA
・LoCon
・LoHA
・HyperNetworks
・DreamArtist
・Aesthetic Gradients
こちらを紹介します。
結論:現状どれが良いの?
2023年3月時点では…
・最良はDreambooth。だが重すぎて一般向けじゃない。
・一般向けで普及しつつあるのがLoRA
・LoRAの進化系のLoConやLoHAに期待
・他も悪くはないが、ツールなどの対応問題があるのでポピュラーなものを使うのが無難
ただ、どの手法も研究中。
状況はいつでも変わる可能性があります。
どれを使うか…
宗教化してる所がある。
高負荷・高性能系
Dreambooth
最も効果的な方法。
モデルが新しい概念を理解するまで内部構造を更新する。
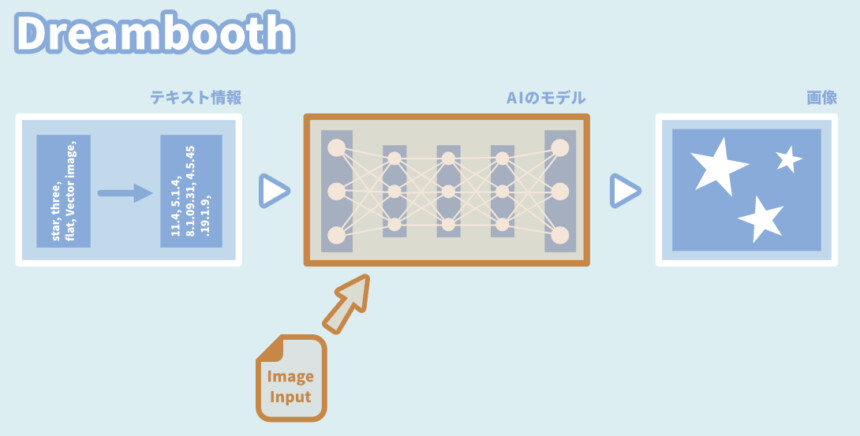
◆メリット
・精度が高い
◆デメリット
・高いスペックのグラボが必要(VRAM 12G以上必須、簡単にやるなら24G)
・学習時間がかかる
・学習結果の容量が大きい
・精度の高さゆえに、似た構図や同じ服装になりやすい
◆備考
Google Colabで動かせるらしいが、センシティブ制限が強すぎるのでおすすめできない。
最近は、技術の進歩でスペックが低いグラボでも動くようになってきた。
VRAM24GB以上のグラボがある方は、こちらを見て実行してみてください。

VRAM 12Gで済む方法もあるみたいですが、
こちらでも、私のPCではスペック不足なので…
解説はできません><
低負荷系
LoRA
軽く、最も一般向けな方法。
モデルの中にある層に新しい層を差し込み変化を加える。
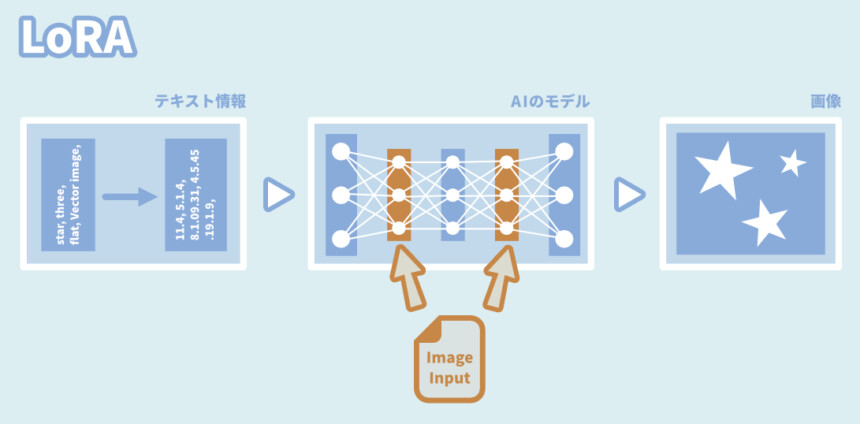
◆メリット
・学習時間が短い
・グラボのスペックが低めでも実行可能(VRAM 6G以上で動くと言われている)
・学習結果の容量も少ない
◆デメリット
・Dreamboothより精度が劣ると言われている
◆備考
一般人でも買えるレベルのグラボで動くという情報が出て、
プチブームのような状態になってる。
LoRAの使い方はこちらで解説しました。
LoRA_Easy_Training_Scriptsを使用すると、LoCon,LoHAも作れるようです。

Locon
LoRAの改良版。
ほぼ全ての層に影響を与えれる。
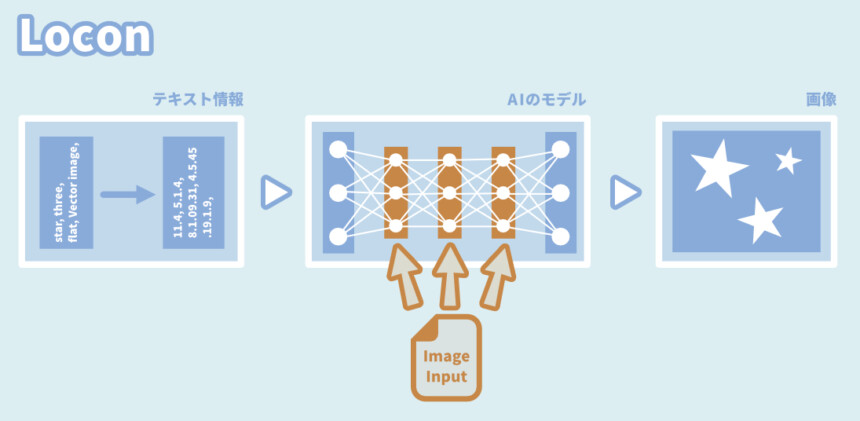
◆メリット
・再現度がLoRAより高い
・学習時間が短い
・グラボのスペックが低めでも実行可能
・学習結果の容量も少ない
◆デメリット
・LoRAより情報が少ない
・Dreamboothより精度が劣ると言われている
◆備考
最近出たばかりなので、情報は少ないです。
LoHA
LoRAの進化系。
軽くてより詳細が学習できる。
◆メリット
・再現度がLoRAより高い
・LoRAより軽い
・学習時間が短い
・グラボのスペックが低めでも実行可能
・学習結果の容量も少ない
◆デメリット
・LoRAやLoConより情報が少ない
・Dreamboothより精度が劣ると言われている
◆備考
もし本当なら、LoRAの上位互換ですが…。
現状、情報は少なくかなりの情強じゃないと動かせない。
(たぶん、英語の論文とGit Hubしかない)
HyperNetworks
少し回り道をしたLoRA。
「Network」という箱のようなものを作り、それ経由で層に影響を与える。
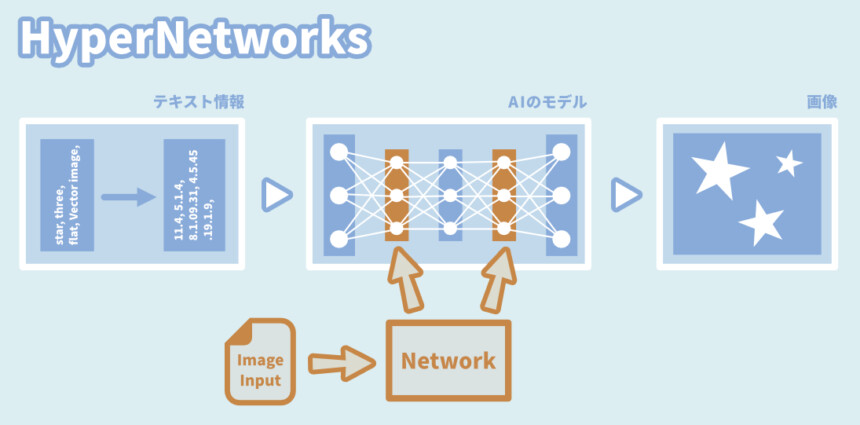
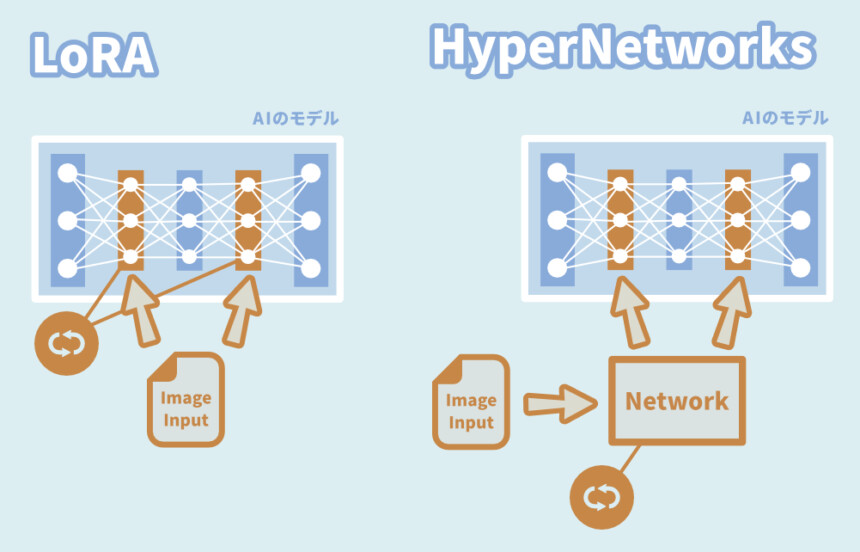
LoRAとの違いは更新される場所のようです。
・LoRA → “層”が何度も更新される
・HyperNetworks → “Network”が何度も更新される
◆メリット
・LoRAより再現度が高いと言う人も居る
◆デメリット
・DreamboothやLoRAよりマイナー
・情報が少ない
◆備考
普通に考えると、少し効率が悪く感じますが…
LoRAより良い画像ができると言う人も居る。
正直、謎の技術。
LoRAやDreamboothを普通に動かせるぜ!
という人が新天地を目指すのに良いかもしれませんが…
1番手にやる事では無いという印象。
その他
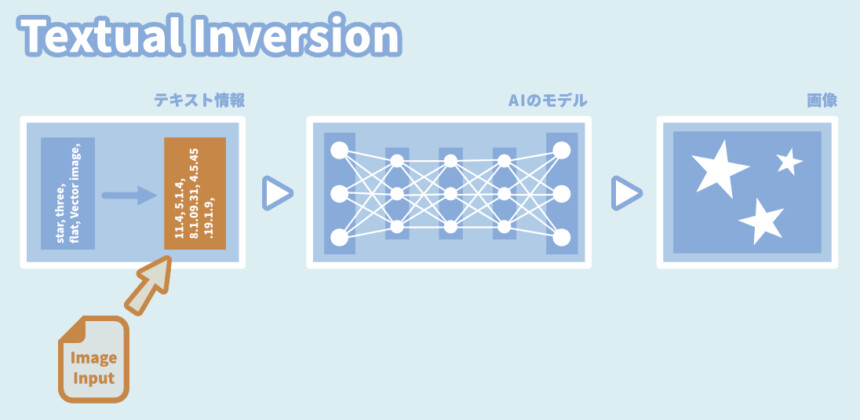
Textual Inversion
テキスト入力を数字化した場所に影響を与えていく方法。
モデルの更新は一切行われない。
◆メリット
・学習結果の容量が最も小さい(10~50KB)
◆デメリット
・DreamboothやLoRAよりマイナー
・LoRAよりは指定する力が弱い
・情報が少ない
◆備考
学習結果の容量が最も小さく共有に便利だが…
LoRAやHyperNetworksの容量が50~200MB。
今の時代なら10~50KBにするメリットを感じない。
これもLoRAやDreamboothを普通に動かせるぜ!
という人が新天地を目指すのに良いかもしれませんが…
1番手にやる事では無いという印象。
DreamArtist
進化版「Textual Inversion」のようです。
ネガティブプロンプトもチューニングが入る。
◆メリット
・ネガティブプロンプトが使える
(○○-neg,という形で書く)
◆デメリット
・情報が少なめ
・知名度も低い
・ユーザーが少ない
Aesthetic Gradients
初期の頃に出てきた手法。
現時点では、基本は使われず、無かった事にされがち。
◆メリット
・手軽
◆デメリット
・精度が高くない
・制御困難
この拡張機能を入れるだけで実行可能。
昔、画像のプロンプトとして使われていた様子。
今はControl Netで代用可能という扱いを受けている。

流行ったのは、2022年10月頃の初期
MidjourneyやNovel AIが全盛期だった頃
基本、いい結果にならないので使わない。
実際に使ってみる
AUTOMATIC1111(Web UI)を使うとこれらの機能を試せます。
Civitaiという、AIの追加学習モデルを配布してるサイトがあります。
こちらで「DreamArtist」以外、既存の配布モデルで試せます。

また、LoRAの学習モデルを自作する方法はこちらで解説。
LoRAの派生形のLoCon / LoHAもこの方法で生成できます。
まとめ
今回は、8つのキャラを学習させる方法の違いを紹介しました。
・強いグラボを持っており、時間がかかっても良い方は「Dream Booth」
・一般的なグラボで、素早く学習させたい方は「LoRA」
・上級者で新天地を開拓したい方は、LoRA派生形やHyperNetworksやDreamArtist
・ツールの対応や参照できる情報量の問題があるのでポピュラーなものを使うのが無難
また、他にもAIイラストについてまとめてます。


ぜひ、こちらもご覧ください。
今回の参考文献
情報を集めることすら苦労する業界なので、情報元置いておきます。
↓英語版、4つの学習モデルの違い。
ネタバラシらしすると、今回の記事はほぼこの動画の翻訳にいろいろ情報を加えたもの。
17:06~は4つの学習モデルで使ったVRAMや生成物の容量が見れる
↓動画内で出てきた生成の違いイメージ
この記事で出した図解の詳細版。
↓LoRAとLoConの違い図
↓LoRA周りの情報参考

↓DreamBoothについて

↓Textual InversionとDreamArtistについて。

↓いろいろ載ってる。海外の情報助かる。

↓Discordサーバー「AI 絵作り研究会」
一部の追加学習関係の会話を参考にしました。
↓いろいろ情報

コメント