
はじめに
今回は画像から音を作る方法を紹介します。
The ARSSというツールを使います。
有料ならPhotosounderというソフトがおすすめ。(110$)
また、この処理はどうしても画像の細部が崩れたり、歪みます。
綺麗に作っても表示ソフト側の問題で歪みます。
細かな表現に向かないことを前提に進めてください。
下準備
こちらのページにアクセス。

使ってるOSを選択。(ここではWindows)
5秒待つとDLが始まります。
※The ARSS = Analysis-Resynthesis Sound Spectrographの略
zipを展開。
→ INSTALL.txtを確認。
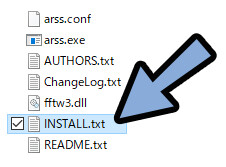
すると、「動かすにはCMakeが必要、こちらのURLよりダウンロード」と書かれてます。
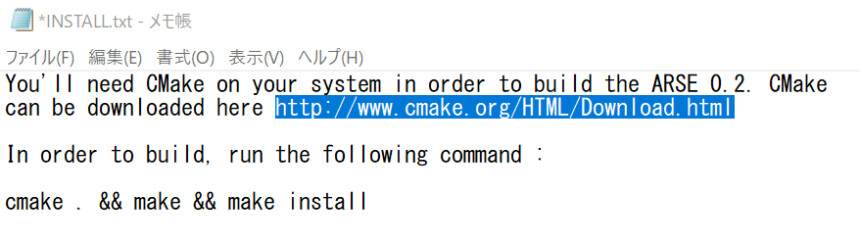
このページにアクセス。

使ってるOSに合わせたCMakeを選択してダウンロード → インストール。
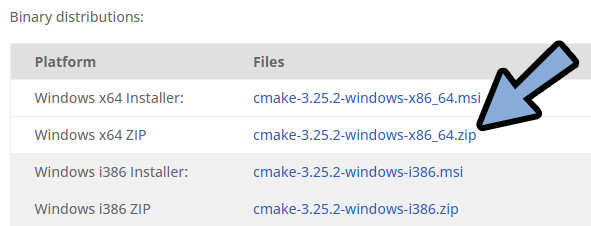
これで下準備が完了です。
利用規約の確認
先ほどDLしたページの名前をクリック。
もしくは、こちらのページにアクセス。

下の方を見ます。
すると、利用規約が書かれてます。
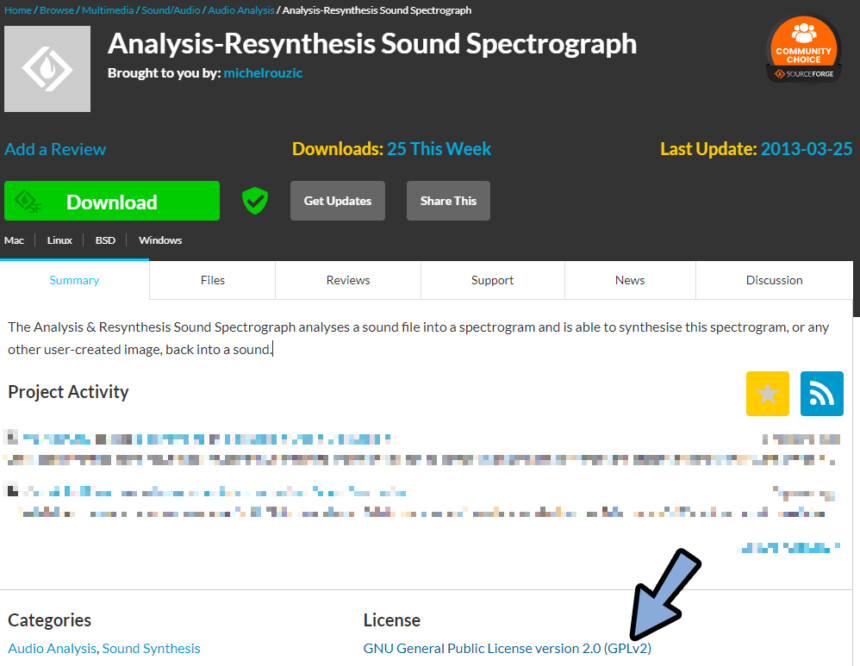
GPLv2は、無料で商業利用OK。
使用した素材の創作物などの制作、販売も可能。
3DCGツールで有名なBlenderと同じライセンスです。(GPL v2)
VRChat界隈を中心に、Blenderを使った商品が出回ってます。
それと同じような扱いができると思ってください。
詳細はこちらでまとめてます。

これで、利用規約の確認が完了です。
画像の用意
The ARSSは「.bmp」形式の画像しか使えません。
また、小さな画像を使う必要があります。(200px前後が理想)
後の設定で、1:1の200pxが重要になってきます。
慣れないうちは、全く同じサイズで作る事を推奨します。
ここでは、無料のKritaを使用して.bmp画像を作成します。
こちらのページよりDL。
できれば1:1の画像をドラッグ&ドロップで読み込み。
画像 → 画像を新しいサイズにスケールを選択。
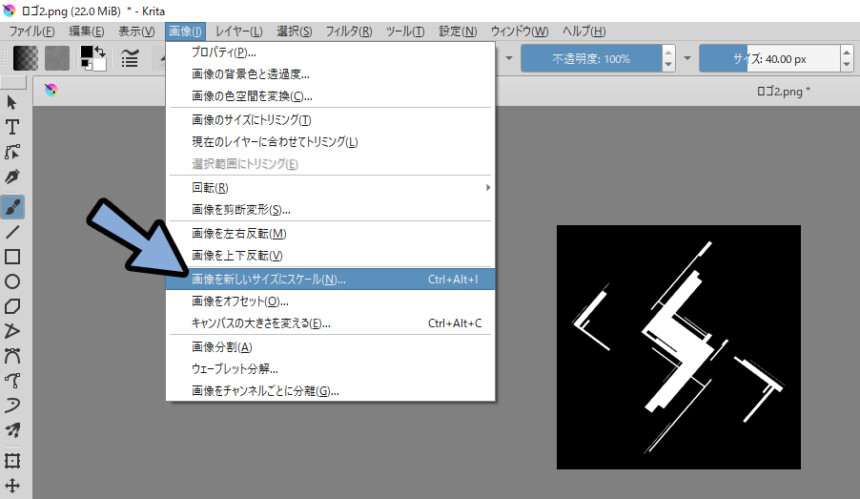
画像の大きさを200×200px
フィルタをバイリニアなどに設定。
OKで確定。
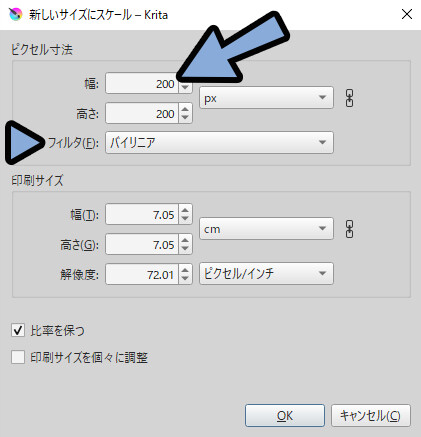
ファイル → エクスポートを選択。
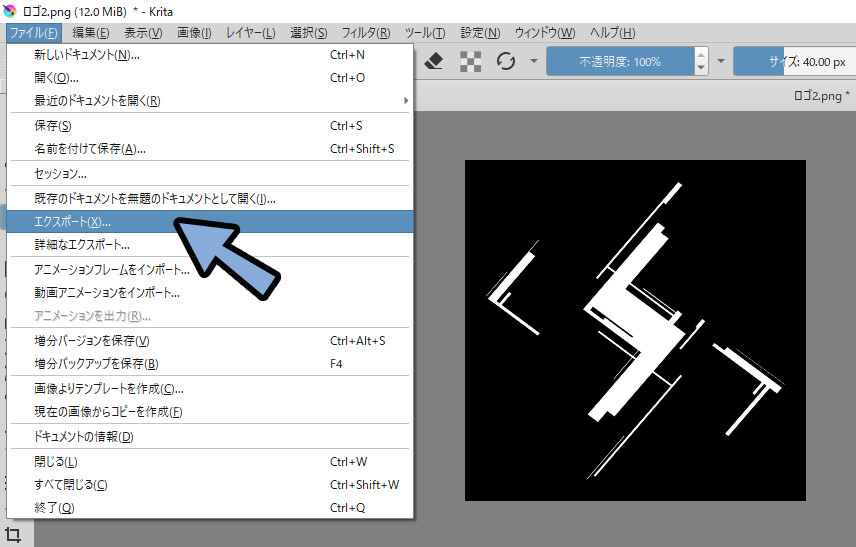
ファイルの種類を.bmpに設定。
任意のアルファベットだけで出来た名前を付けて保存。
日本語のファイル名はエラーの原因になる可能性があるので避けました。
これで、画像生成が完了です。
画像から音生成
先ほどThe ARSSをDLしたファイルを開きます。
arss.exeを実行。
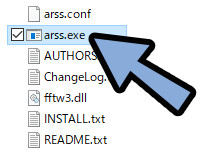
Input file:に使いたい画像をドラッグ&ドロップ。

パス名が出て来たら、エンターで確定。
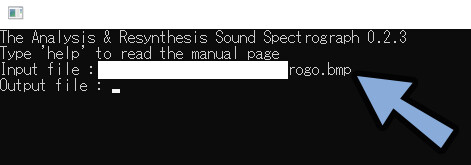
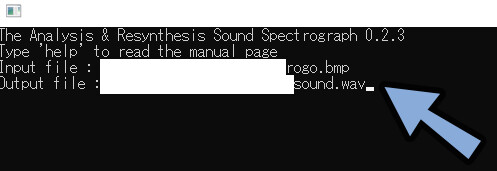
Output file : 「任意の出力先パス」と「\ファイル名.wav」を入力し、エンターで確定。
⚠.wavが最後に無いと動きません。
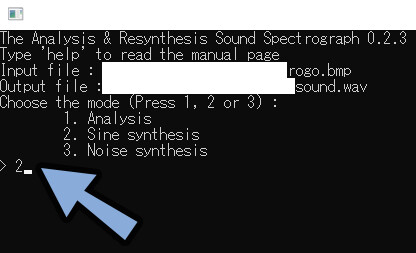
Modeの所で、数字の2を入力。
エンターで確定。
Bit/samleとSample rateを空白の状態でエンターで確定。
min. frequencyを100に設定 → エンターで確定。
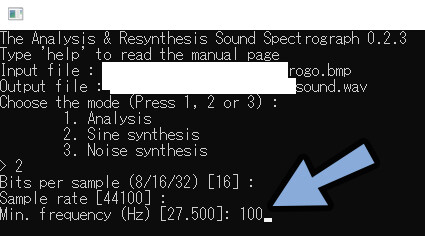
低音部分はスペクトログラムで表示エラーが起こりやすいです。
なのでmin. frequencyを100に設定しました。
Bands per octaveを26.25に設定 → エンターで確定。
すると、自動でMax. frequencyが設定されます。
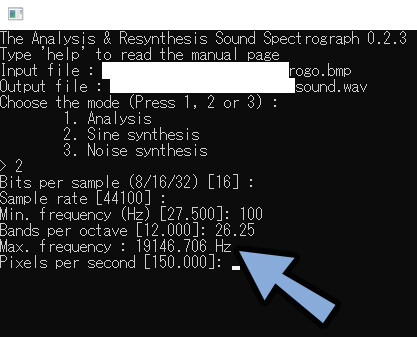
多くのスペクトログラムは20000が最大値です。
ここに収まるようにします。
Max. frequencyの計算は「Bands per octaveの値」と「ピクセル数」が影響してます。
が、具体的な数字の計算は…正直よくわからないです。
【 Max. frequencyを減らす処理 】
・Bands per octaveを大きくする
・ピクセル数を下げる
【 Max. frequencyを増やす処理 】
・ピクセル数を増やす
・Bands per octaveを小さくする試しに、1024×1024pxの画像を読み込ませました。
すると、とんでもない数値になりました。
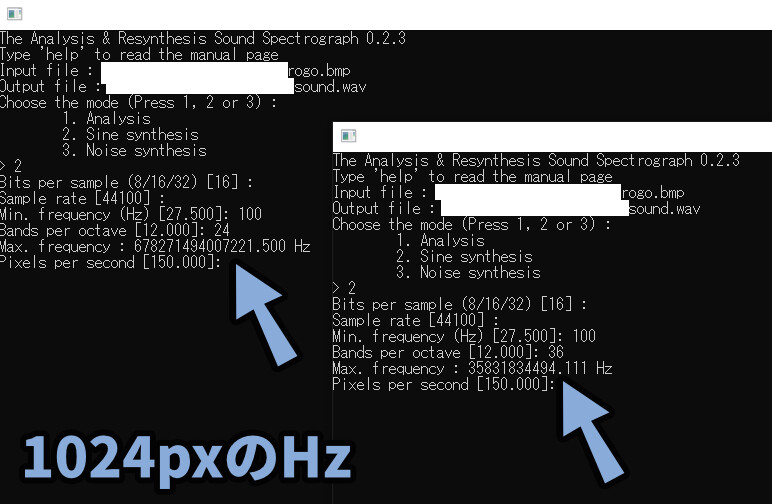
これが、画像を200×200pxにした理由です。
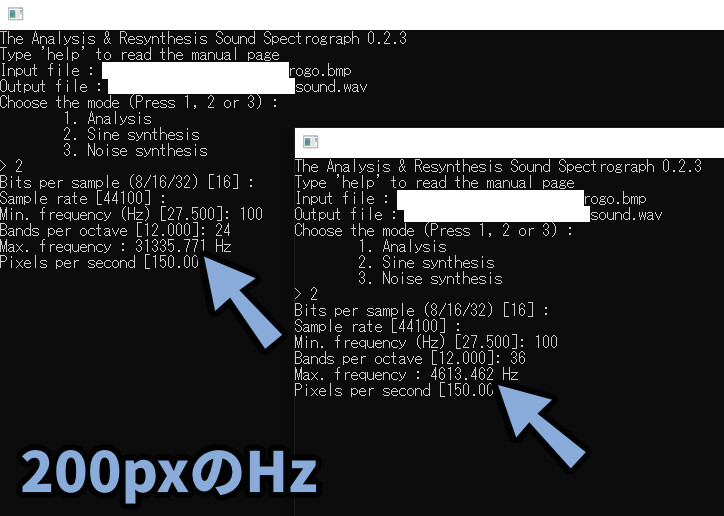
任意の画像を使いたい方や、細かく調整をしたい方は、毎回wavファイルを消して1から実行。
「Bands per octaveの値」と「ピクセル数」を変えてMax. frequencyを調整してください。
次に、Pixels per secondです。
これは「ピクセル数÷任意の値=秒」という計算式。
ここでは50に設定して、4秒の音を作ります。
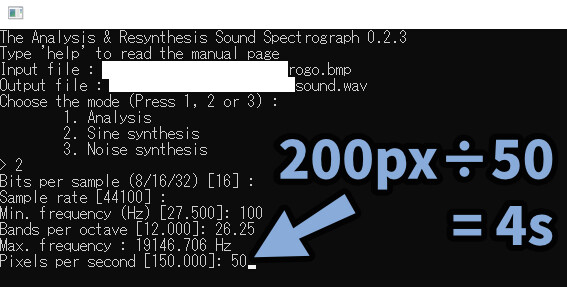
エンターで確定。
すると、サウンドファイルが生成されます。
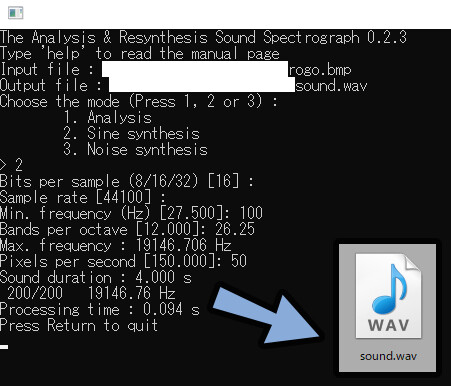
これで、画像から音生成が完了です。
ステレオグラムに表示させる
何でもいいので表示ソフトを用意します。
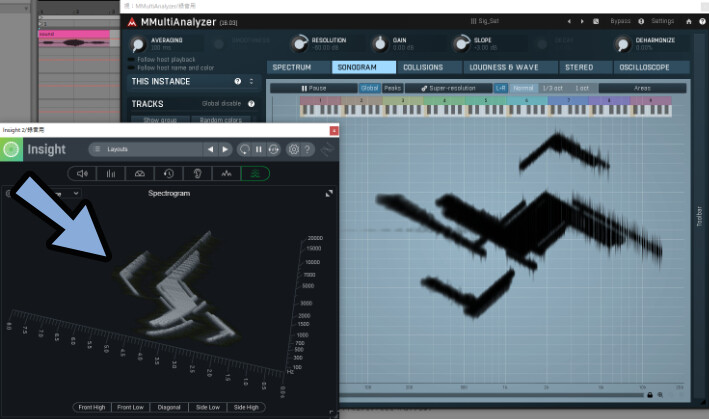
DAWに読み込ませて、有料ツールの「Insight 2」と「MMultiAnalyzer」で表示させました。
すると… ツールの違いで歪みます。(Hz幅の取り方、秒の刻み方、など)
こればかりは、仕方ないです。
無料で一番綺麗に表示できるソフトがAudacityです。(ただ、落ちやすいなどの問題あり)
こちらにサウンドファイルをドラッグ&ドロップ。
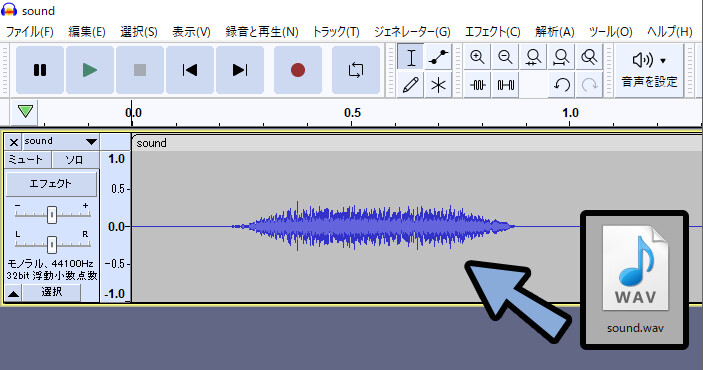
Soundの所 → スペクトログラム(S)を選択。
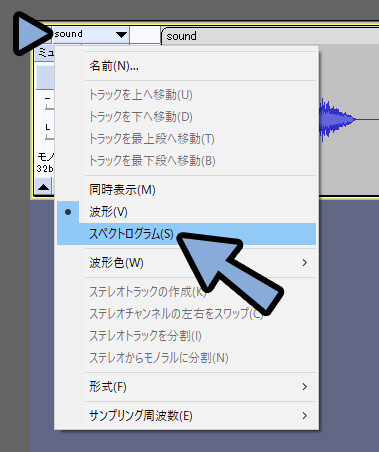
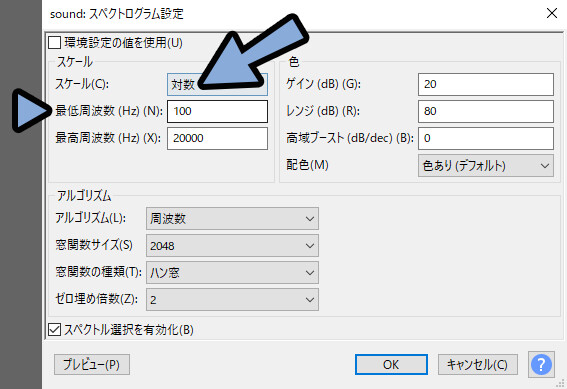
もう一度sound → スペクトログラム設定(P)を選択。
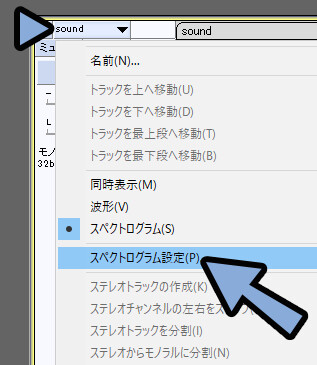
スケールを対数に設定。
最小周波数を100、最大周波数を20000に設定。
OKで確定。
表示する大きさなどを調整。
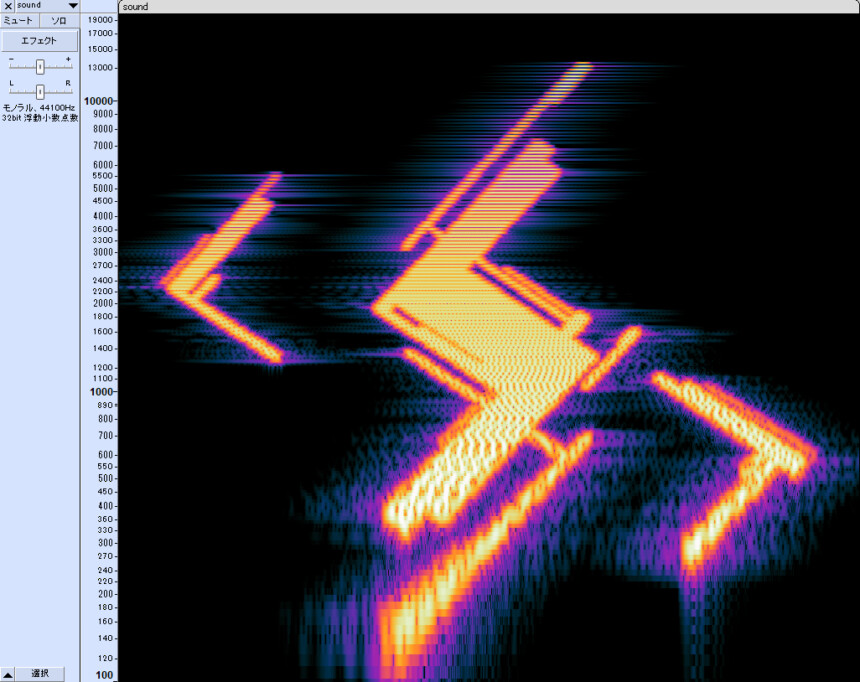
以上がステレオグラムに表示させる方法です。
歪みを減らすコツ
ツールによって歪むのは仕方ないです。
その上で出来る事、シンプルな図形の場合、なるべく低い周波数を使わない事。
つまり、画像で言うと下の余白を大きくとる事です。
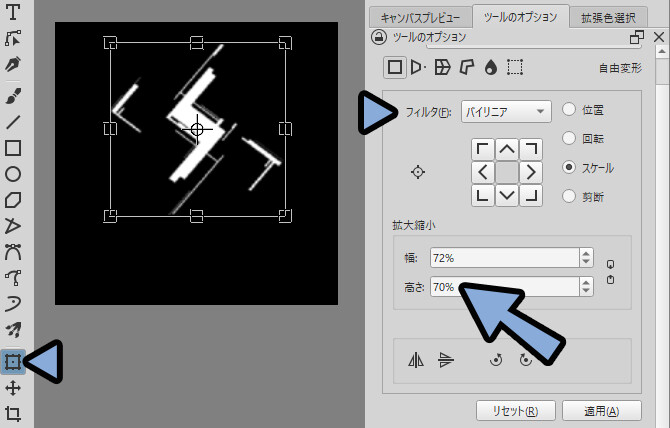
これで、Insight 2でもややマシな表示になりました。
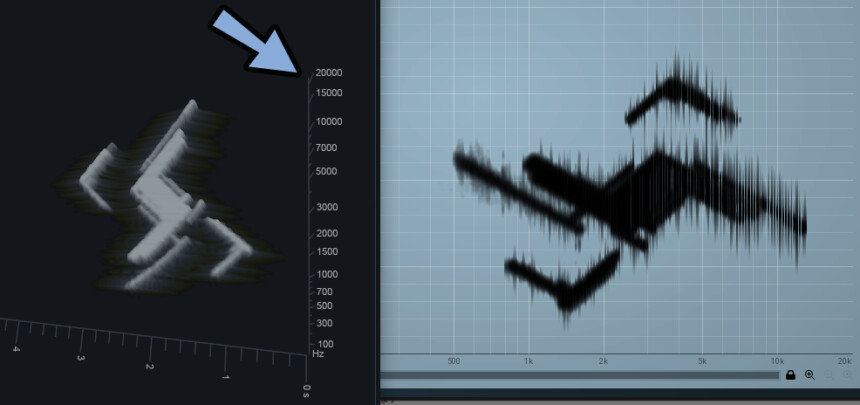
元の画像を比べるとこの通り。
キャライラストで音生成
AIで生成したキャラを表示させたのが下図。
この場合、なぜかInsight 2の方が綺麗に出てます。
MMultiAnalyzerでは、顔の部分で線が途切れ、胸しか映ってません。
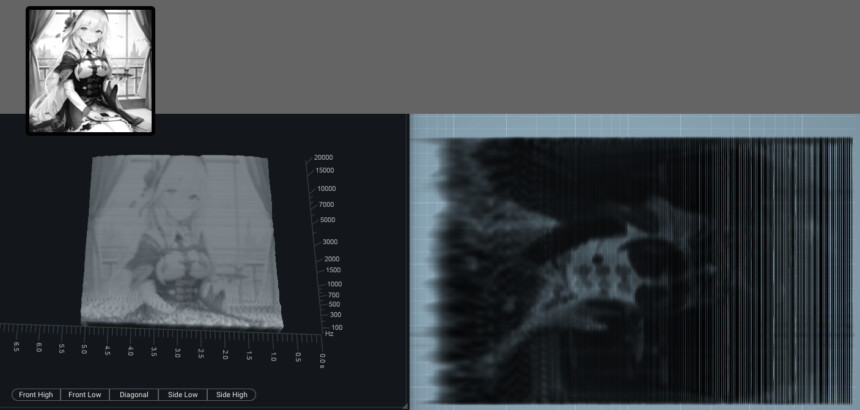
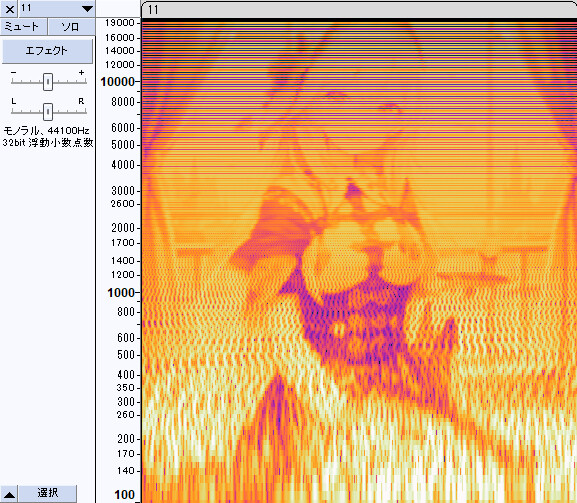
Audacityで表示させるとこのような感じでした。
こちらも、顔(5000Hz)より上で線が出てきてしまいます。
また400Hz以下もマシですが…ノイズが強い。
コツまとめ
以上より、考えられるコツは下記。
・綺麗に見せたい物はなるべく中央。
・上と下は使わない
・どうしても上下に跨ぐ場合はシンプルな図形なら下の方を空ける
・絵などは上の方を空ける
・そもそも歪みが気にならない図形を使う
・一部の表示ツールで歪むことを諦めるその他の画像 → 音生成方法
$110課金できるなら「Photosounder」を強くお勧めします。
このARSSのシステムを組み込んで拡張した1つのソフトです。
簡単に、画像から音が作れるようです。
また、曲の低音と高音を入れ替えたり、ボコーダー、ノイズ除去、コーラスなどができます。
前衛的な技法で、音楽を制作したいにおすすめ。
⚠vstプラグインではなく、スタンドアローンのソフトです。
また、他にも下記のような生成ツールがあります。
・Wolfram言語
・Image to Audio, Spectrogram Player
・ Coagula …など
が、下記のような問題があり解説を避けました。
・これ目的にWolfram言語に課金するならPhotosounderを買った方が良い
・フリーソフトは精度がやや低い
・利用規約が明確でないものがある …など
【おまけ:Wolfram言語での生成方法】
→ Wolfram cloudに登録
→ in1~3をコピペ
→ 任意の画像をドラッグ&ドロップで差し替えて
→ 動作させてOBSやオーディオインターフェースなどで録音。興味ある方は、こちらも試してみてください。
まとめ
今回は画像から音を作り、ステレオグラムに表示させる方法を紹介します。
また、先ほど紹介した音の表示ツールの使い方はこちらで解説。
ぜひ、こちらもご覧ください。


コメント
初めまして。
The ARSSのパラメーター「bands per octave」辺りの仕様について、以下が参考になるかもしれません。
このbands per octave というのは、「画像の1ピクセルを1メモリとする」という前提があるようです。
つまり、200pxの画像の場合、200目盛りであることがその時点で決定していて、
その1メモリで何を表すか、を使用者が設定することになります。
max周波数は、以下のようになっていそうです。
ーーーーーー
max = min×2^(P/B)
・B→bands per octave
オクターブ(周波数二倍)を何分割するか(対数で)
・P→ピクセル数-1
目盛りのmaxで、0からmax-1まで。px数個
・1目盛りが2^(1/B)になります。
ーーーーーー
画像の高さ1024px、min Hzが100とすれば、
max = 100 * 2^((1024-1)/36)
≒35831834494.1106…
と、この記事にある値の通りになりました。(画像では最後の桁で四捨五入されて、末尾は「.111」)
一応、maxを20000hzにおさめるために、画像の高さ(px)に対してbands per octaveをいくつにすればよいか、
計算式を置いておきます
ーーーーーー
B = P/log2(20000/min)
・B→bands per octave
オクターブ(周波数二倍)を何分割するか(対数で)
ーーーーーー
適当なパラメータを入れて確認してみます。
・画像の高さが1024px →Pが1023(= 画像の高さpx -1)
・minが100
B = 1023/log2(20000/100)
≒133.83
この値をbands per octaveに入力すると、
Max frequencyは20002.353Hzと、大方狙い通りの値になりました。
つまり、画像の高さpxが多いなら、目盛りを細かくすることができて、
より精密に音を再現できる、ということになります。
◇
調べものをしていて辿り着きましたこちらのページが、大変参考になりました。ありがとうございました。
もうこのソフトについて興味はないかもしれませんが、これが有用な情報となっていれば幸いです。
なるほど~ ありがとうございます。