
はじめに
今回は、AIイラストの追加学習を行う方法を紹介します。
この記事では「LoRA_Easy_Training_Scripts」を使います。
こういう事ができます。(左:VRoid、右:生成)

グラボは1660Ti / VRAM 6Gを使用。
(PC環境の詳細はこちら)
下準備
LoRA_Easy_Training_Scriptsを使うための下準備をします。
こちらのページにアクセス。
必要なものを確認。
Python 3.10.6とGitが必要な事が分かりました。
こちらを入れていきます。
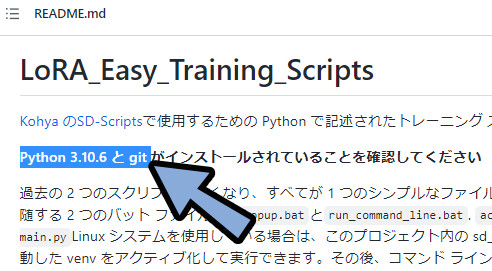
※Pythonのバージョンは変わってる可能性があるので、
各自で確認してください。
Pythonの導入
こちらのページにアクセス。

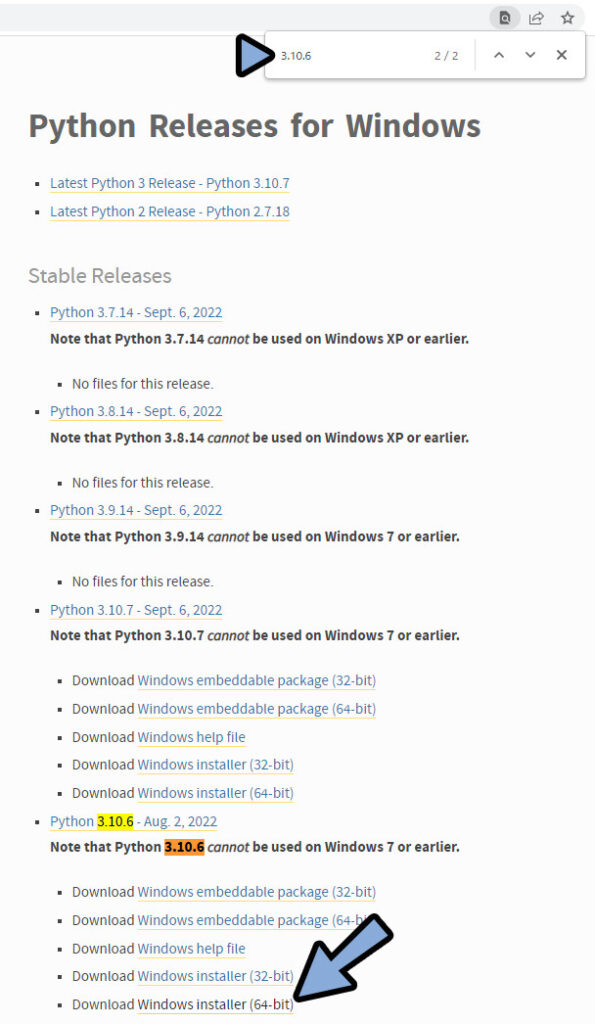
必要なバージョンを検索。
インストーラー版をDL。
.exeを実行。
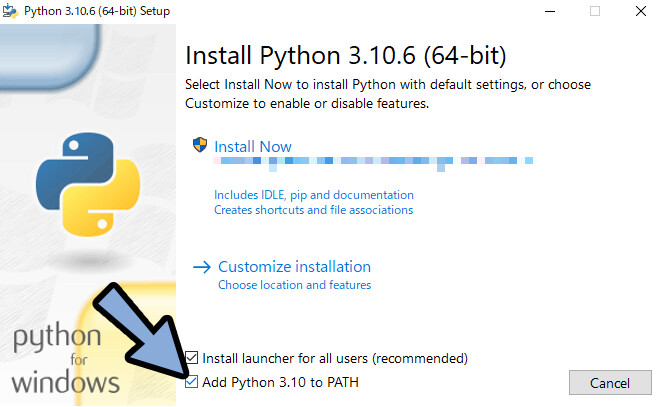
Add Python 3.10 to PATHにチェック。
あとは、任意の方法でインストールすれば導入完了です。
Gitの導入
こちらのページにアクセス。
GitをDL。(多分、Standalone版で大丈夫です)
.exeを実行。
指示に従ってインストールすればGitの導入が完了です。
以上で下準備が完了です。
LoRA_Easy_Training_Scriptsの導入
こちらのページにアクセス。
最新版の「install_sd_scripts_.bat」をクリックしてDL。
LoRAを置きたい場所に「install_sd_scripts_.bat」を配置。
ファイルの大きさが20GB以上になるので注意。
後から動かすとエラーの原因になるようです。
場所は慎重に選んでください。
「install_sd_scripts_.bat」をクリックして実行。
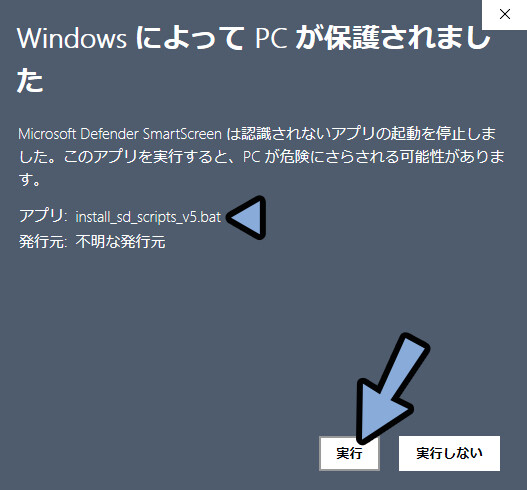
PCが保護された場合は「詳細情報」をクリック。

アプリが「install_sd_scripts_.bat」になってる事を確認。
実行をクリック。
しばらく、黒い画面を眺めます。
気になる方は、LoConやLoHAなどの派生形も読み込まれることを確認。
「続けるには何かのキーを押してください…」が出ましたら×ボタンで閉じます。
これで「LoRA_Easy_Training_Scripts」を入手が完了です。
場所は「install_sd_scripts_.bat」の横に生成されます。
LoRA_Easy_Training_Scriptsフォルダの中に入ります。
これで、基本的な導入が完了です。
16系グラボ用の改造
16系グラボ=1660Tiや1660などの、名前の初めに16ついたグラボ。
16系(1660Ti)の固有のエラーがここでも出るようです。
なので、こちらを修正します。
↓エラー詳細+参考記事

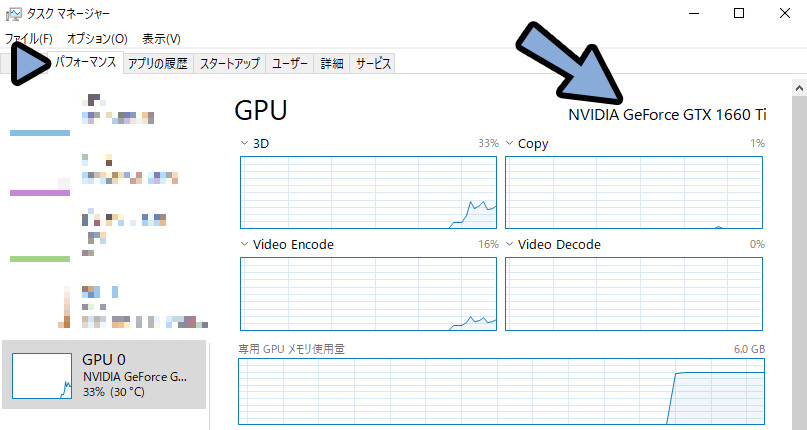
使ってるグラボの確認はWindowsキー+X → Tキーでタスクマネージャーを起動。
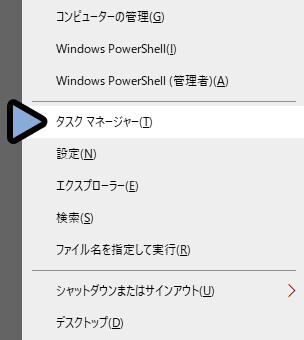
タスクマネージャー → パフォーマンス → GPUの所で確認できます。
私は、1660Tiなので、「16系グラボ用の改造」を行います。
それ以外の方は読み飛ばしてください。
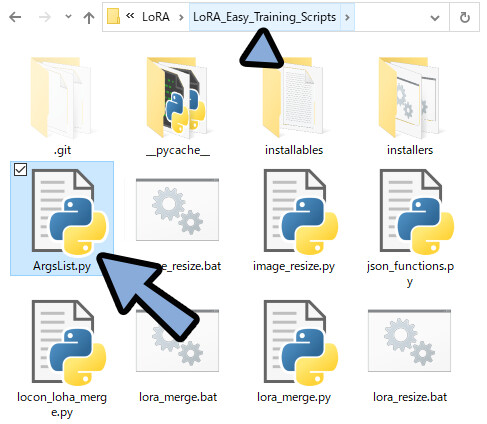
LoRA_Easy_Training_Scriptsの中に「ArgsList.py」がある事を確認。
こちらを、メモ帳などのテキストエディターにドラッグ&ドロップ。
(私はSublime Textを使います)
「self.mixed_precision: str = “fp16″」を探します。
※Sublime Textなら、Ctrl+Fで検索できます。
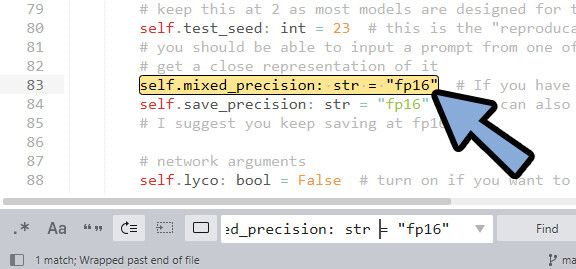
こちらの「“fp16”」を「“no”」に書き換え。
上書き保存。
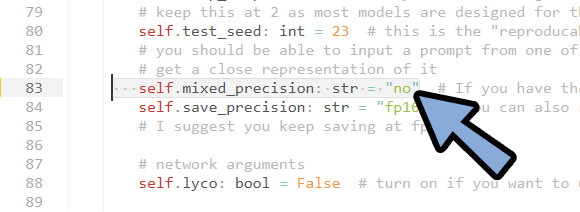
これで、16系グラボ用の改造が完了です。
LoRAの動作確認
LoRA_Easy_Training_Scriptsが動くかを確認します。
「run_popup.bat」をダブルクリックして実行。
Do you want to run multiple tranings?などのポップアップが表示されれば成功です。
動作確認ができましたら、黒い画面にある×ボタンで閉じます。
表示されない場合はWindows+Tabキーで画面の裏に出て無いか確認。
よく、黒い画面の裏に潜り込むので注意。
これで、LoRAの動作確認が完了です。
学習データの用意
学習用の絵を入れるフォルダを作ります。
場所と名前は「日本語のテキスト」が無ければ何処でも大丈夫です。
私は、LoRA_Easy_Training_Scriptsの中に「Data」というフォルダを作りました。
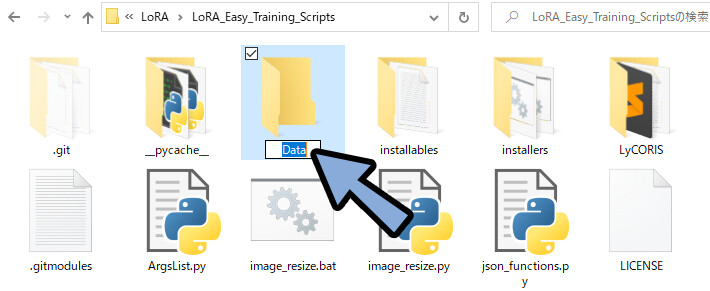
日本語や特殊文字のファイル名は、
プログラム界ではエラーの原因になります。
なるべく避けてください。
「Data」の中にもう1つフォルダを作成。
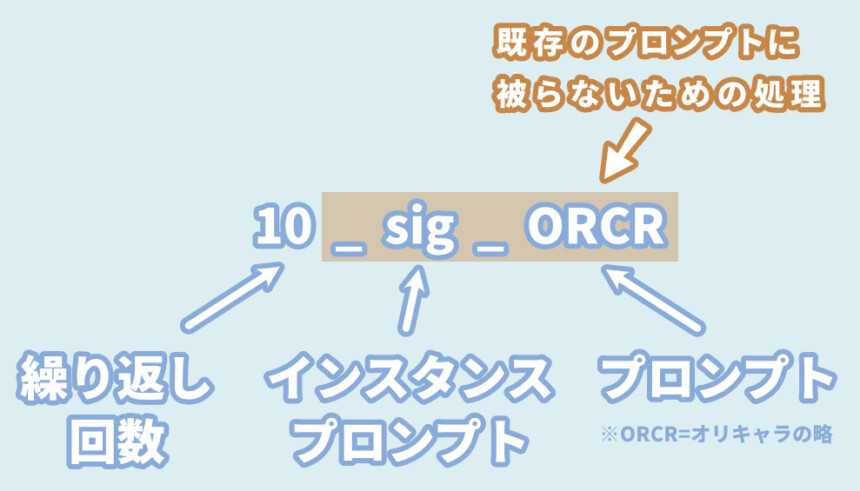
「10_sig ORCR」という名前に設定。
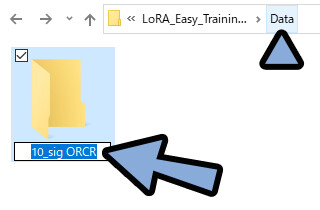
この名前が重要です。
・最初の数字 = 学習の繰り返し回数
・インスタンスプロンプト = 被り防止用の3文字ぐらいの意味のない文字列
・プロンプト = 学習内容を使うためのプロンプト重要なのはプロンプトも、できるだけ意味のない文字列にする事です。
プロンプトでcatやdogなどを使うと、後で正則化画像を使って調節するなど面倒事になります。
繰り返し回数は、何が良いかよくわかってませんが、
私が見た情報では10だったので10に設定。
(この数は、後ほどepochs数に影響を与える)
WEB UIで使う場合、プロンプトは1クリックで勝手に入るので超適当でOK。
インスタンスプロンプトはsig以外でも、
cicやusuやnenのような適当な文字列でok。
とにかく被らなそうな文字列を入れてください。
つぎに、学習用のデータ用意します。
理想は「512×512px」のデータ。
これは、LoRA_Easy_Training_Scriptsのデフォルトで使わる大きさです。
私は… 知らなかったので600×800pxで作りました。
2000×2000のような大きさでない限り、そのまま入れて大丈夫です。

ちなみに、私はVRoidで制作 → 書き出しました。
VRoidを使って学習データを作りたい方は、こちらをご覧ください。

灰色の背景付きのpngを16枚ほど「10_sig ORCR」の中に作成。
名前は「001~016.png」のような形にしました。
これで、学習データの用意が完了です。
LoRAで学習させる
学習用のデータを用意したことを確認。
この状態で、run_popup.batをダブルクリックで起動。
すると… このようなポップアップが出てきます。
そして、地獄の質問攻めが始まります。
これに1つ1つ答えて、学習用の設定を作ります。
作った設定は「.json」というファイルで保存されます。
2回目以降はこれを読み込めば済むので安心してください。

設定は凄く長くなります。
なので「設定の詳細はここをクリック」で折り畳み式にまとめました。
私もこの設定は、分かってない事の方が多いです。
よくわからず設定した所は(よく分かってない)と表記してます。
とにかく、よくわからないけど動いたからヨシ!
というスタンスで「まず動かす」ことを目標にしてみてください。
細かな所は動いて、慣れてきてから。
↓↓run_popup.batを起動し、こちらを見ながら質問に答えていきます。
【設定の詳細はここをクリック】
全ての文章を入れると、長くなりすぎるので、前の1行だけで紹介します。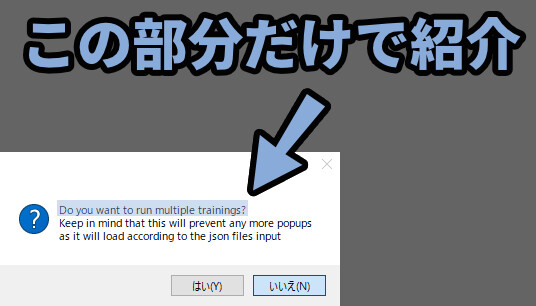
・Do you want to run multiple tranings?
→ 「いいえ」を選択。
・Do you want to load a json file?
→ 1回目は「いいえ」を選択。
・Do you want to save of your congiguration?
→ 「はい」を選択。 (これで.jsonファイルが保存される)
・Select the folder to save json files to
→ OK → 任意の保存先を指定。
・What name do you want to set the json file?
→ 任意のファイル名を入力。
(実際のファイル名は 「”config-なぞの数字-設定した名前”」になる)
・Do you want to save a json file and not train?
→ 「いいえ」を選択。
「はい」すると学習を行わず、.jsonファイルの作成のみ行える
・Select your base model
→ OK → 任意のAIイラスト学習モデルを指定。
(ACertainThing.ckptなど)
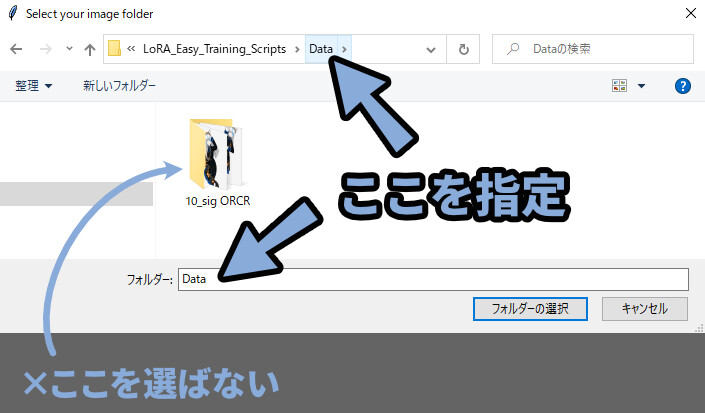
・Select your image folder
→ OK → 学習用の画像があるフォルダを選択。
※この記事の例なら、「Data」の所でフォルダー選択を押す。
10_sig ORCRの中に入るとエラーが出る。
・Select your output folder
→ OK → 任意の学習済みLoRA出力先を指定。
・Do you want to change the name of output checpoints?
→ 「いいえ」を選択。
(はいを選択すると、生成した画像のメタデータにある”生成モデル表示名”を変えれる)
・Do you want to save a text file that contains a list of all tags that you have used in your traning data?
→ 「いいえ」を選択。(よく分かってない)
・Are you traning on a SD2.x based model?
→ 使用する学習モデルを確認。
stable diffusion2.0などの2系モデルなら「はい」。
・Are you traning on an realistic model?
→ 学習させる画像が、写真のような表現なら「はい」。
・Are you traning on an realistic model?
→ 学習させる画像が、写真のような表現なら「はい」。
→ イラスト的であれば「いいえ」。
・Do you want to use regulatization image?
→ 「いいえ」 (もし、正則化画像をつかうなら「はい」。)
・Which Optimaizer do you want?
→ 「AdaFactor」を選択。(よく分かってない)
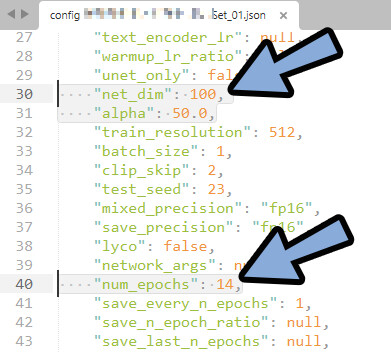
・What is the dim size you want to use?
→ 一旦、「100」に設定。
上げると精度が上がるが、過学習になりやすい。
のちほど、学習させる内容の複雑さに合わせて、1~128の範囲で調整。
・Alpha is the scalar of the traning,~~~~
→ 「Cancel」を選択。
・Which type of model do you want to tranin?
→ 初心者の方は「LoRA」を選択。
まずLoRAを動かして、慣れてきたら「LoRCon」や「LoHA」に挑戦。
・What learning rate do you want to use?
→ 「Cancel」を選択。(よく分かってない)
・What unet_lr do you want to use?
→ 「Cancel」を選択。(よく分かってない)
・What text_encoder_lr do you want to use?
→ 「Cancel」を選択。(よく分かってない)
・Which scheduler do you want?
→ 「cosine_with_restarts」を選択。(よく分かってない)
・How many time do you want cosine to restart?
→ 「Cancel」を選択。(よく分かってない)
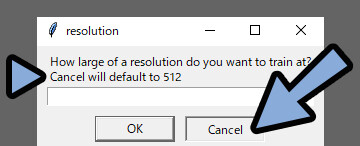
・How large of resolution do you want to train at? → 学習させる画像をリサイズする大きさ。
まず、「Cancel」で512に設定。
のちほど、動かなければ下げる。
・The number of images that get processed at one time, ~~~~
→ 「Cancel」を選択。(よく分かってない)
・Which way do you want to manage steps?
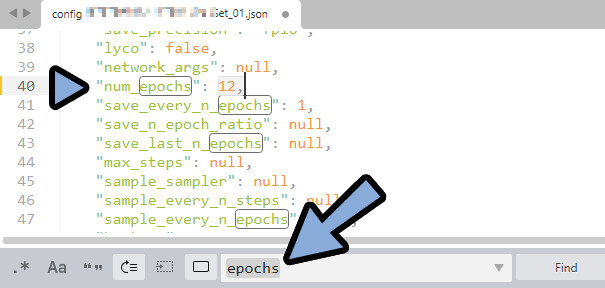
→ 「epochs」を選択。(学習回数の”単位”を指定)
epochs数 = 用意した画像の枚数×フォルダ名で指定した学習回数(ここでは10)
・How many epochs do you want?
→ 「14」ぐらいに指定。
これは、どのぐらい学習させるかの指定。
用意した学習元の画像に合わせて数を入力
epochsは1~14までファイル分けして出力されるので多めに指定。
・Do you want to save epochs as it trains?
→ 「はい」を選択。(これで、1~14のepochsが保存される)
・Do you want to save epochs as it trains?
→ 「Cancel」を選択。(epochsの保存間隔、Cancelで”1″を指定)
・Do you want to have a warmup ratio?
→ 「いいえ」を選択。(よく分かってない)
・Do you want shuffles captions?
→ 「はい」を選択。(よく分かってない)
・Do you want to keep some tokens at the front of your captions?
→ 「いいえ」を選択。(よく分かってない)
・Select what elements you want to train.
→ 「both」を選択。(よく分かってない)
・Do you want to flip all of images?.
→ 基本「いいえ」を選択。
学習させる画像を左右反転して、情報量を増やそうとしている。
左右非対称の要素が崩れるので、いいえを選択。
画風などを学ばせたい場合は「はい」
・Do you want to set a comment that gets put into the metadata?
→ 「Cancel」を選択。(適当な文字を入れれば、メタデータに自分のキャプションを残せる)
・Do you want to prevent upscaling images?
→ 「はい」を選択。(よく分かってない)
・What Mixed precision do you want?
→ 「fp16」を選択。(よく分かってない)
・What save precision do you want?
→ 「fp16」を選択。(よく分かってない)
Which of random crop or cache late do you want? ~~
→ 「cache latents」を選択。(よく分かってない)
Do you want to generate test images as you train?
→ 「いいえ」を選択。
※学習中に実験で画像を生成するかどうかの項目。
プロンプトの入力には専用の.txtファイルの用意が必要。
用意が出来なければ、最初からやりなおしになる。
以上で設定が完了です。
質問の内容は、バージョン差によって設問が変わる事があります。
この場合は下記の「設定で迷った時に役立つ情報」を見ながら、自分で答えてください。
設定で迷った時に役立つ情報
スマホアプリのGoogle翻訳を入れます。
すると、「カメラ入力」が使えます。
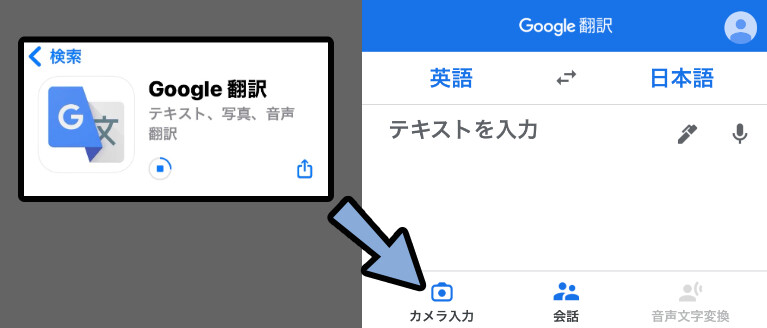
これを使えば、画面に出ている英単語を翻訳できます。
非常に便利です。
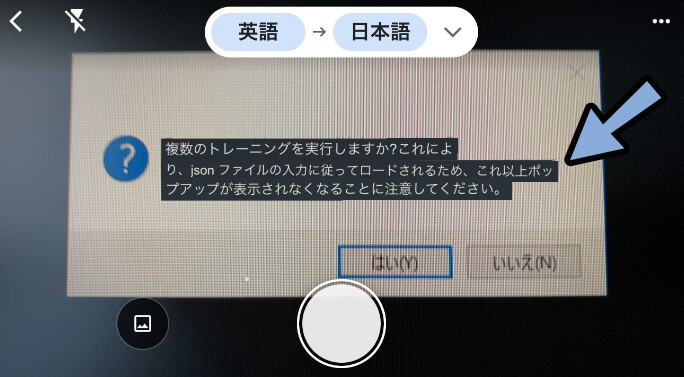
質問はCancelを押すとデフォルトの値が入る物があります。
「Cancel」の表示があり、よくわからないものはデフォルトを信じて使います。
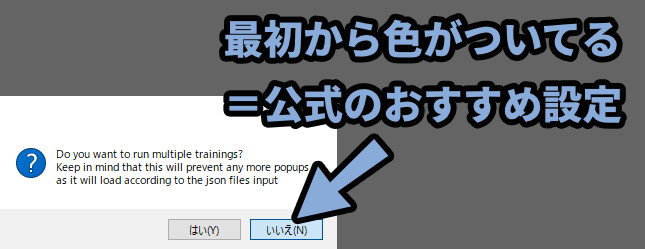
「はい / いいえ」に色がついてる場合、色がある方が公式のデフォルト設定です。
こちらも、よくわからないものはデフォルトを信じて使います。
また、細かなパラメーターは下記の参考資料で調べてください。
「原神LoRA作成メモ・検証」や「こちらのWikiの参考資料」をWEBで開く。
Ctrl+Fで、分からないパラメータを検索してください。(「dim」など)
※広告規約のセンシティブ関係で直接リンク張れないです。
申し訳ないですが、各自で検索してください。
以上が、設定で迷った時に役立つ情報です。
設定が終わった後の挙動
一番最後の質問に答えます。
すると、黒い画面が出てきて学習が始まります。
※エラーが出た場合は「設定を変えて再学習する方法」まで読み飛ばしてください。
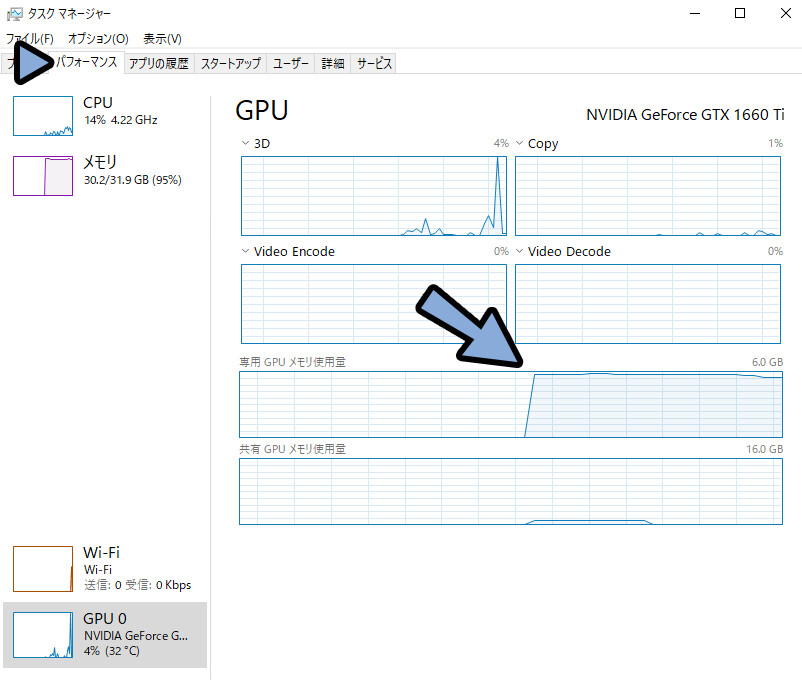
Windowsキー+X → Tキーでタスクマネージャーを起動。
パフォーマンスで負荷を確認。
GPUのメモリ使用量が、爆上がりしていれば成功です。
「続行するには何かキーを押してください…」が出るまで待ちます。
この表示が出たらEnterキーなどを入力し、閉じます。
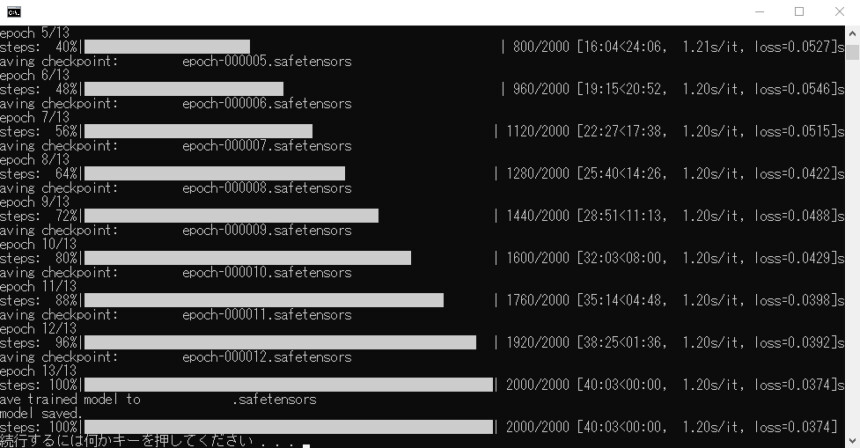
出力先に指定したフォルダを確認。
すると、「epoch-000001~.safetensors」というファイルができてます。
これが、追加学習したLoRAのモデルです。
以上でLoRAでの学習が完了です。
設定を変えて再度学習する方法
パスの場所指定をミスしたり、グラボのスペックが足りないとエラーが出ます。
エラーが出るたび、この設定をやり直すのは地獄です。
そこで、.josnファイルを使います。
こちらで設定を書き換え → 読み込ませることでも学習を開始できます。
「.josnファイル」をメモ帳などのテキストエディターにドラッグ&ドロップ。
(私はSublime Textを使います)

この文字列が、先ほどの質問の答えです。
出たエラーに合わせて、これを書き換え上書き保存します。
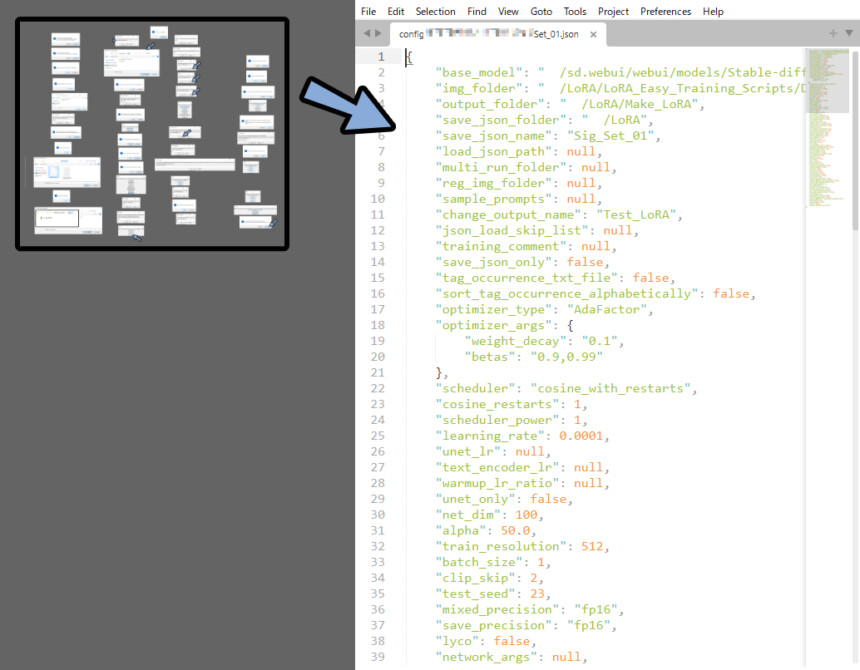
Sublime Textの場合は、Ctrl+Fで変えたいパラメーターを検索できます。
これらを駆使して.josnファイルを書き換えてください。
LoRA CUDA out of memoryエラー対策
LoRA CUDA out of memoryはグラボのスペック不足によるエラーです。
これは、グラボにかける負荷を減らすと回避でいkます。
グラボの負荷を変える、主要な要素は下記の3つ
・net_dim
・alpha
・train_resolution
この3つを下げると動きます。
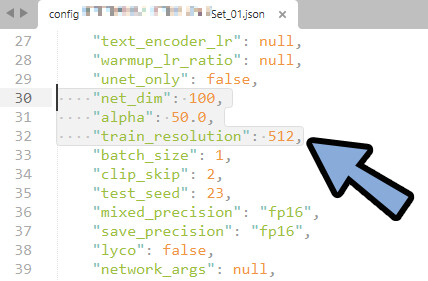
◆3つのパラメーターの調整方法について。
・「alpha」は「net_dim」の半分の値に設定してください。
・「net_dim」は学習の精度に関わるパラメーターのようです。
設定は慎重してください。
(net_dimの詳細は「より良くするために → パラメーターについて」で解説)
・net_dimをこれ以上下げれない場合は、「train_resolution」の値を下げてください。以上が、LoRA CUDA out of memoryエラー対策です。
.josnファイルを読み込み動かす
.josnファイルの用意を済ませます。
この状態で「run_popup.bat」を起動。
・Do you want to run multiple tranings?
→ 「いいえ」を選択
・Do you want to load a json file?
→ 「はい」を選択。
Slect the json file you want to load
→ 「OK」を選択。
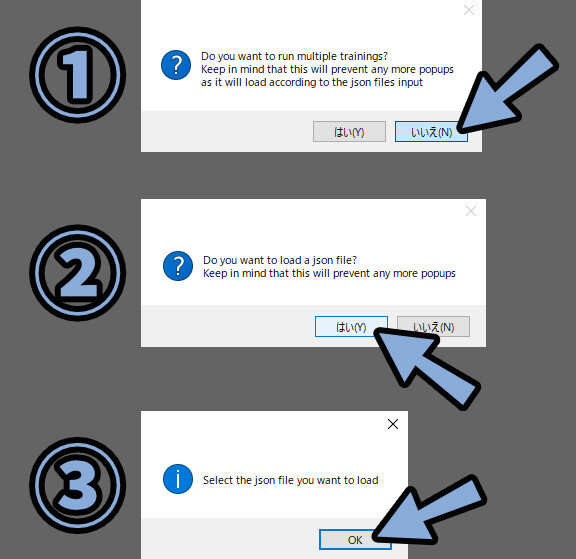
.josnファイルを選択 → 開くをクリック。
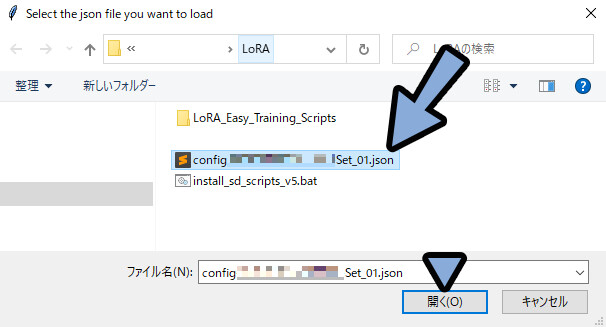
これで学習が始まります。
あとは、エラーとの闘いや試行錯誤の世界です。
以上が、設定を変えて再度学習する方法です。
Web UIでLoRAを使う
こちらを見ながらWEB UIを導入。
まず、WEB UIのアップデートをします。
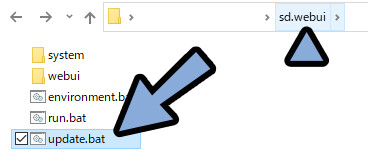
次に、制作したLoRAの学習モデルを下記の場所に配置。
「sd.webui → webui → models → “Lora“」
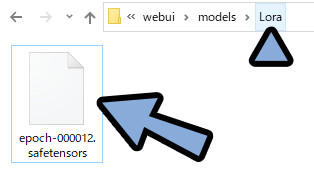
配置後に、WEB UIを起動。
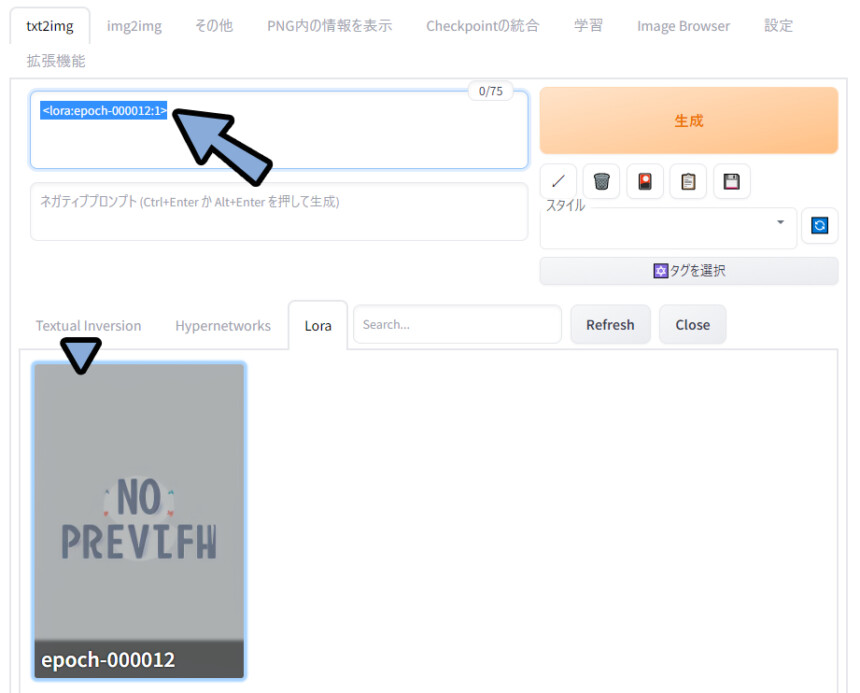
生成したの「🎴」マークをクリック。
Loraを選択。
Refreshをクリック。
中に「epoch-00****.safetensors」と表示が出たら成功です。
「epoch-00****.safetensors」をクリック。
すると、LoRAを使うためのプロンプトが入ります。
この上から、適当なプロンプトを入力。
生成をクリック。
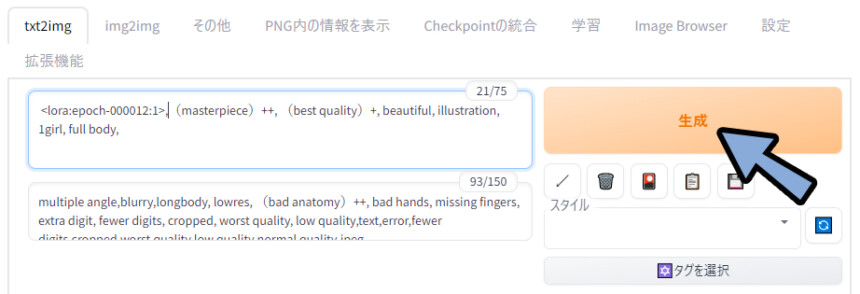
入れたプロンプトはこちら。
◆プロンプト
<Loraのモデルプロンプト>,(((masterpiece))),((best quality)),beautiful ,((illustration)), 1girl, full body,
◆ネガティブプロンプト
multiple angle,blurry,longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality,text,error,fewer digits,cropped,worst quality,low quality,normal quality,jpeg artifacts,signature,watermark,username,blurry,missing fingers,bad hands,missing arms,head_out_of_frame,2koma,panel layout,
※図で、()++形式でプロンプトを強調してるのは単純にミスすると、このような絵が生成されました。
LoRAの学習の影響を受けてることが分かります。
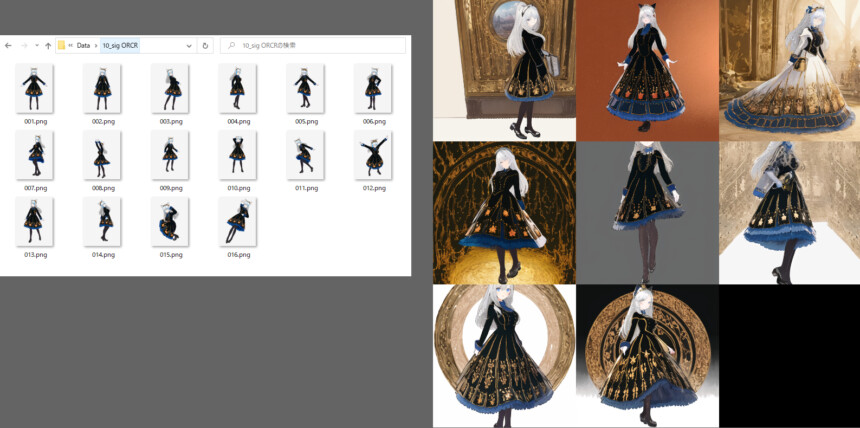
学習元との比較。
若干、模様が違ったり、青い髪が消えるのは…仕方ないようです。
以上が、Web UIでLoRAを使う方法です。
より良い追加学習のために
私もまだまだ研究中ですが、
触ってみて感じた事、分かった事などをまとめます。
プロンプトの強調
<lora:epoch-00**** :1>は (( )))では強調出来ません。
そこで…
<lora:epoch-00**** :1>の :1の数字を変えて強調します。
・<lora:epoch-00**** :0.5> = 弱くする
・<lora:epoch-00**** :1.0> = 通常
・<lora:epoch-00**** :1.6> = 強くするプロンプトの強調が、一番簡単なクォリティ調整です。
まずここから、試してみてください。
パラメーターについて
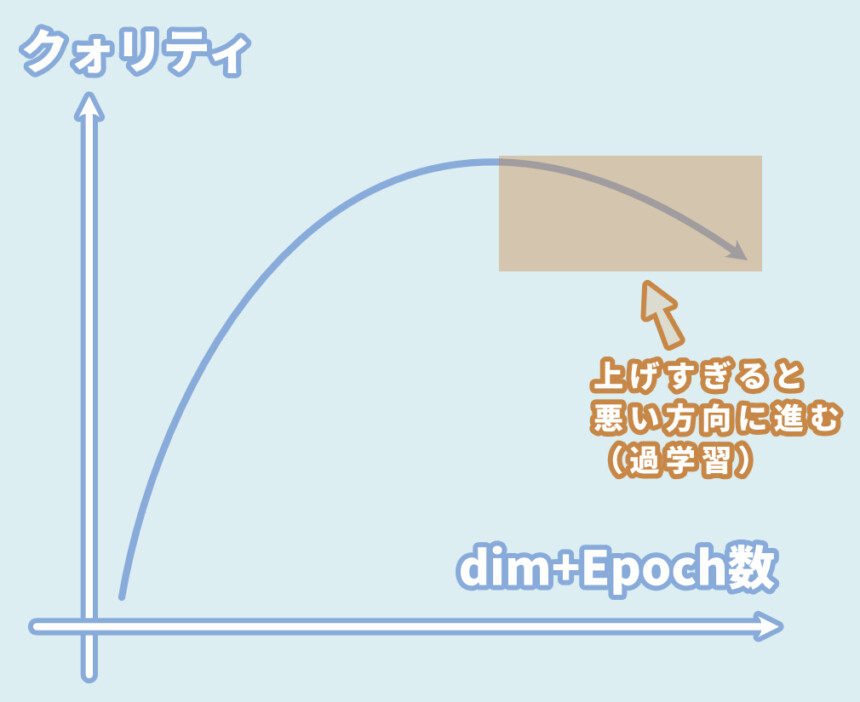
学習の結果を左右する主要なパラメーターは「net_dim」「alpha」「num_epochs」と思います。
alphaは「net_dim」の半分の値なので…。
実質、パラメーターで結果を左右するのは「net_dim」と「num_epochs」の2つ。
dim50、epoch -6で生成したモノ。
精度はやや下がるが、綺麗な絵ができやすい。

dim110、epochs -12や -8で生成したモノ。
精度は上がるが、綺麗な絵にはなりにくい。

マシだった画像を拡大。
キャラ似せの精度は上がったが、絵の仕上がりは残念になったことが分かります。

これは、過学習という問題と考えられます。
人工知能は学習を重ねると、精度は上がるが自由度が下がります。
その結果、融通が利きにくくなり、クォリティが微妙な画像ができてしまう現象。
また、一部だけ青い髪の毛のような、尖った特徴は学習しないようです。
dimやepochを上げて制度を上げればできるかもしれませんが…
より過学習の問題が悪化するのでNG。
VRoidの素材を、dimとepochs強めに学習させると…
“VRoid感”まで学んでしまいした…というオチ。
これは、精度と自由度の難しい問題です。
細かい所はまだまだ、人力で加筆する必要がありそうです。

あとは…「原神LoRA作成メモ・検証」や「こちらのWikiの参考資料」で、
他の方の事例を見ながら研究してください。(私も研究中です)
原神の方、dim128を使ってたので、高めにしました。
が、dim 128が許されたのは学習元が”絵”だったからなのか…?
VRoidを使うと、VRoid感を学習してしまう。
なので、低めに設定するのがよさそう…?
→ 低Dim + epoch × 強めのプロンプト強調…?
プロンプトについて
同じdim / epoch数でも、プロンプトで絵が大きく変わります。
例えば、全身を意味する「full body」の有無で比較。

full bodyが無くなると、絵の良さが少し上がりました。

プロンプトを入れ過ぎると、その特徴が出にくくなる。(濁る)
特定の特徴を出したいなら、他のプロンプトを減らす。
キャラを可愛く描画させるなら、画面当たりの面積を増やす。
=full bodyのようなプロンプトを使わない。
…といった、コツが必要なようです。
まだまだ私のも試行錯誤中の段階です。
教師画像 / 正則化画像について
多くのLoRA記事では、必要とされている正則化画像。
軽く解説すると下記。
・正則化画像=プロンプトの概念が変わらないようにするための学習用画像
・正則化画像の用意。プロンプトだけで生成した画像を大量に用意する
・プロンプトの概念は変って良いなら用意しなくていいなので… 今回はプロンプトに被りを避けた「意味のない英語の文字列」を入れれば問題ないと考え、私は入れませんでした。
もし入れると結果が変わるかもしれませんが…。
それよりも、土台となる「学習元の画像」を増やしたりクォリティが上げた方が良いという意見もあります。
正規化画像や、質のいい学習元の画像を用意すると結果が変わるかもしれません。
このあたりも、研究中。
LoCon / LoHAについて
「LoConとLoHA」は進化版のLoRAです。
詳しい違いはこちらで解説。

現状、エラーが起こって動かない可能性が高いです。
導入は少し待って、整備されてからをおすすめします。(2023年3月16日、時点)
ーーーーー
LoConやLoHAの使用は「Which type of model do you want to tranin?」の設問で選べます。
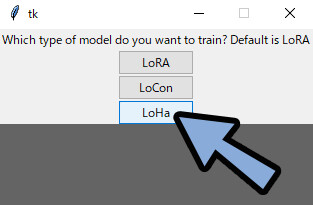
※LoConやLoHAを選択すると、LoConやLoHA用のdimとAlphaの数を追加で聞かれます。
デフォルトではLoConとLoHAのdimとAlphaは、同じになるよう設定されてます。
.jsonでLoCon/LoHAを設定を確認
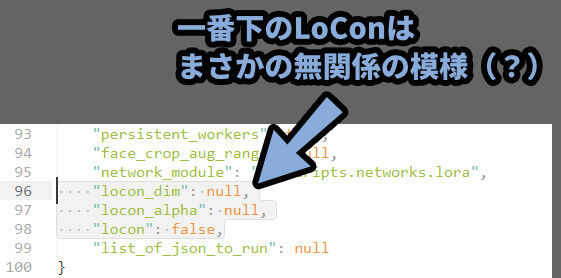
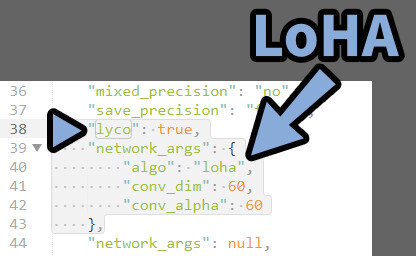
.jsonの「LoCon/LoHA」は“lyco”:~~~~ で設定されます。
今のバージョンでは38行目。
“lyco”: falseなら =LoRA

「”lyco”:ture」で中に「”algo”:lora」があれば、LoCon。
下にあるのは、LoConのdimとAlpha数。
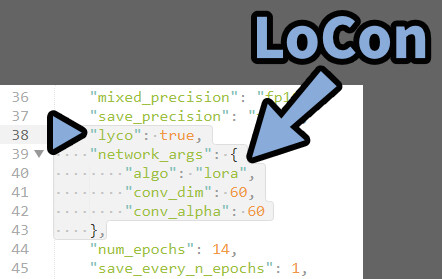
一番下にある”locon”~~~~系は、まさかの無関係の模様。
おそらく… 開発中の名残? 近いうちに消えると思われる。
(LoCon書き出し設定した所、ここは何も変化しませんでした。)
「“lyco”:ture」で、中に「”algo”:loha」があれば、LoHA。
その下にあるのは、LoHaのdimとAlpha数。
以上が、.jsonでLoCon/LoHAを設定する方法です。
LoCon/LoHAをWEB UIで使う
LoCon/LoHAの利用はWEB UIで、このプラグインでできます。
CivitaiのLoConとLoHAモデルで動作確認済み。

※ただし、動くものと、動かないものがありました。
現在のLoCon/LoHA拡張機能の説明に書かれてる
「cp 分解を伴う LoHa と LoCon はまだサポートされていません」
https://github.com/KohakuBlueleaf/a1111-sd-webui-locon (2023年3月16日時点、Google翻訳を使用)
これが原因と考えられます。
…しばらく待った方が良さそうです。
LoCon/LoHAの現状
現状、開発中の先進的な機能でエラーが起こりやすいです。
導入は、しばらく待ってからがおすすめ。
WEB UIで使うための拡張機能すらサポートしきれてない状態。
(2023年3月16日時点)
私は、現在の「LoRA_Easy_Training_Scripts」でLoCon、LoHAは動かせませんでした。
初心者には、おすすめしません。
LoConでepoch-1までは学習できたのですが…
epoch-2の7%。166step目で「Traceback (most recent call last):」エラー落ちしました。
設定を作り直しても同じ、166step目でエラー。
逆になぜ166Stepまで動いた??
私のグラボが1660Ti(VRAM6G)で16系の問題で相性が悪いのか…
LoRA_Easy_Training_Scripts側に問題があるのか…?
※dim60 / LoConのdimも60で作ったepoch-1は一応、動作しました。
が、黒い服が多めに出るな…ぐらいで影響が正しく出てるか分からないレベル。
LoHAはStep 1すら動かず、「Traceback (most recent call last):」エラー。
いま、これを試すのは、茨の道です。
もう少し待って整備されてからがおすすめ。
LoCon/LoHAは工事中です。
が、LoRA入れるだけでも苦労し、
情報が不足してると感じたので公開しました。
私が解説できるのは、ここまでです。
動いた方が居ましたら、教えてください。
まとめ
今回は、AIイラストのLoRAで追加学習モデルを作る方法を紹介しました。
・LoRAは「LoRA_Easy_Training_Scripts」で動かせる
・LoConとLoHAも「LoRA_Easy_Training_Scripts」にセットで入ってる
・下準備にPythonとGitが必要。
・学習データはVRoidなどを使って用意
・背景はすべて白でも上手く行く
・dimとepoch数が結果に大きな影響を与える
・dimとepoch数を上げすぎると、精度が上がるが過学習で絵のクォリティは下がる
・強調は<****:n>の数字を変えて行う
また、他にもWEB UIを使用した、AIイラストについて解説してます。



ぜひ、こちらもご覧ください。


コメント
詳しい説明ありがとうございます。自分で好きな需要の少ないキャラのLoraを作りたいと思いますが、参考になりました、時間のある時にやってみます。
さきのコメントになぜかプロファイル画像がついてしまったため、削除してください、迷惑かけて申し訳ございませんでした。
ありがとうございます。
+1つ目の投稿(画像付きの投稿)について削除しました。
しぐにゃも様、返信ありがとうございます。昨日休みなので、試しにやってみましたら、成功できました。100枚以上の画像を使ったせいか、使用環境のグラフィック性能が低いせいか、3時間ほどが必要で、途中何回か止まってしまい、最後は一日かかってようやくできました。それで3つ疑問が浮かべました:
1.最高な再現度を実現するのに、lora学習に使う素材画像は何枚ほどあれば十分でしょうか。
2.途中で止まってしまった時に保存した「途中バージョン」のloraはどうすればその途中から学習を続行できますか。昨日は途中でパソコンがフリーズしたりして、最初から学習をやり直しましたが。
3.学習を終えて取得したloraを、より繊細で正確にするために、追加学習をする方法はありますか。
1,学習内容によって異なるので、具体的に何枚とは言えません。
→ 私は20~30枚ぐらいで学習させました。
2,現状は最初からやり直しになると思います。
3,loraを含めた追加学習は、精度を上げようとすると過学習で変になる。
過学習を避けると精度が上がらないという問題があります。
どのあたりがちょうどいいかは、模索しながら作るしかないです。
もし、精度を上げるなら、LoCon、LoHa、Dream Boothといった別の手法を取る事になると思います。
ただ、精度とか学習の関係は変らなそうですが…。