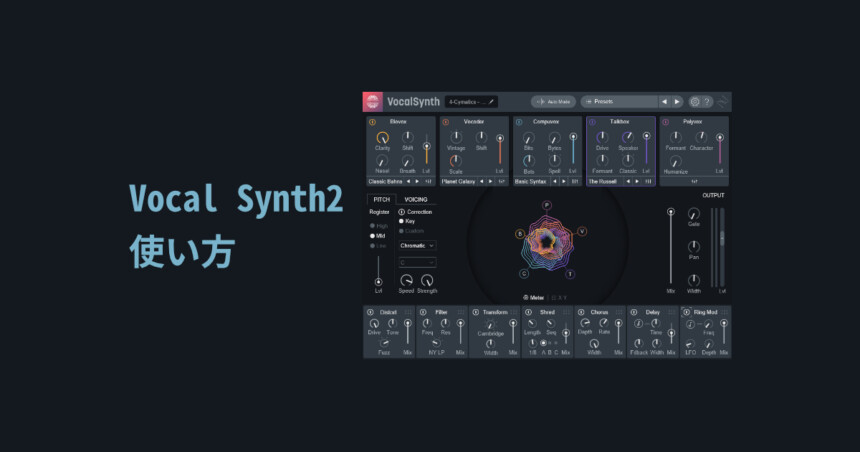
はじめに
今回は、Vocal Synth2の使い方を紹介します。
これはiZotope社が出してるいろんなエフェクト刺しまくりプラグインです。
エフェクトのプラグインです。
これ単体で音が出ないことに注意。
長い記事なので、Ctrl+Fキーで必要な部分を記事内検索しながら見てください。
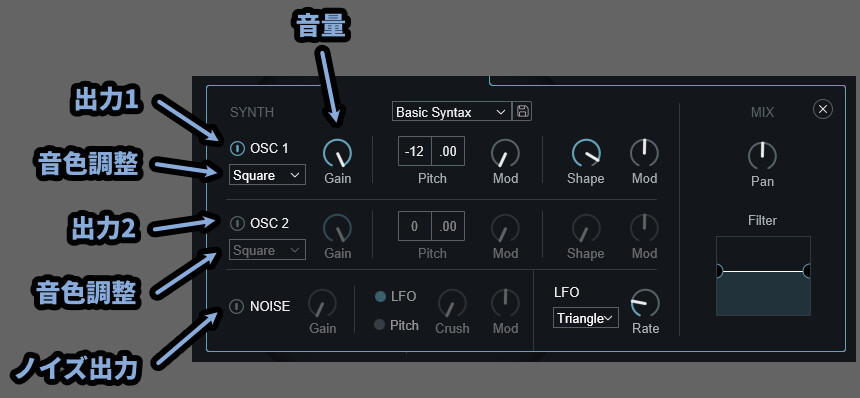
Vocal Synth2の基本操作
起動するとこのような画面が出てきます。
最初からボコーダーと言うエフェクトが入った状態になってます。
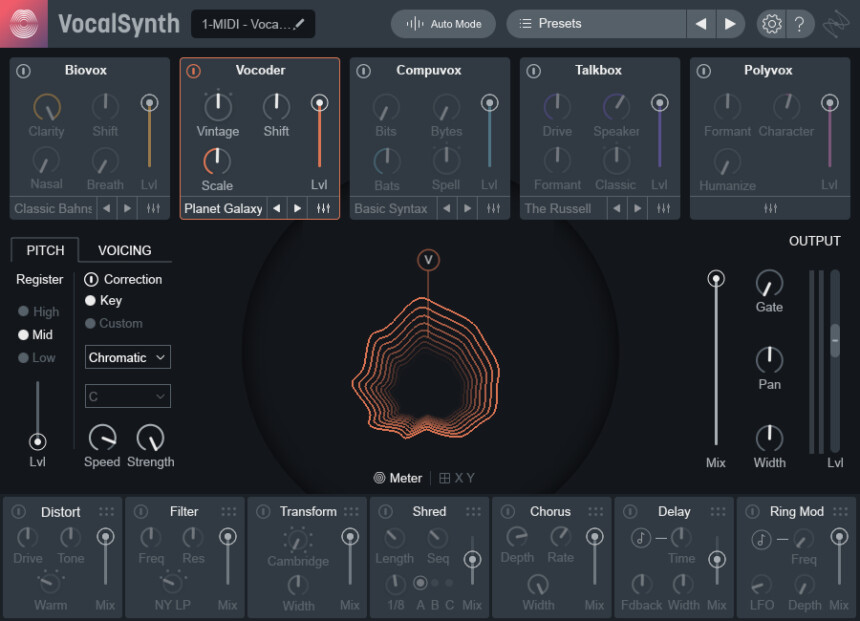
画面の大きさは変えれないようです。
画面上部がVocal Synth2固有のエフェクトで、画面下部がよくある標準エフェクトです。
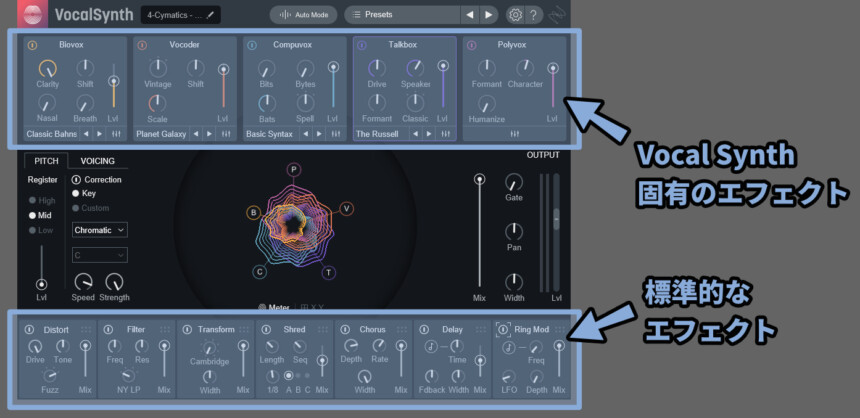
エフェクトは左上にある電源ボタンで有効化できます。
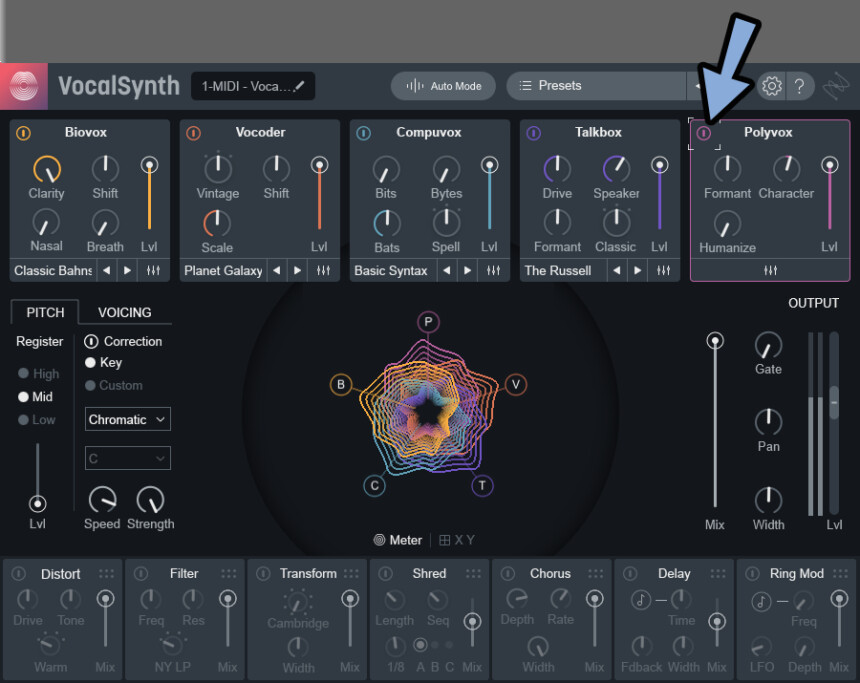
Lvlか、中央に表示されてる頭文字のところを操作。
適当に音を鳴らして、右側を確認。
すると、エフェクトの出力音量を操作できます。
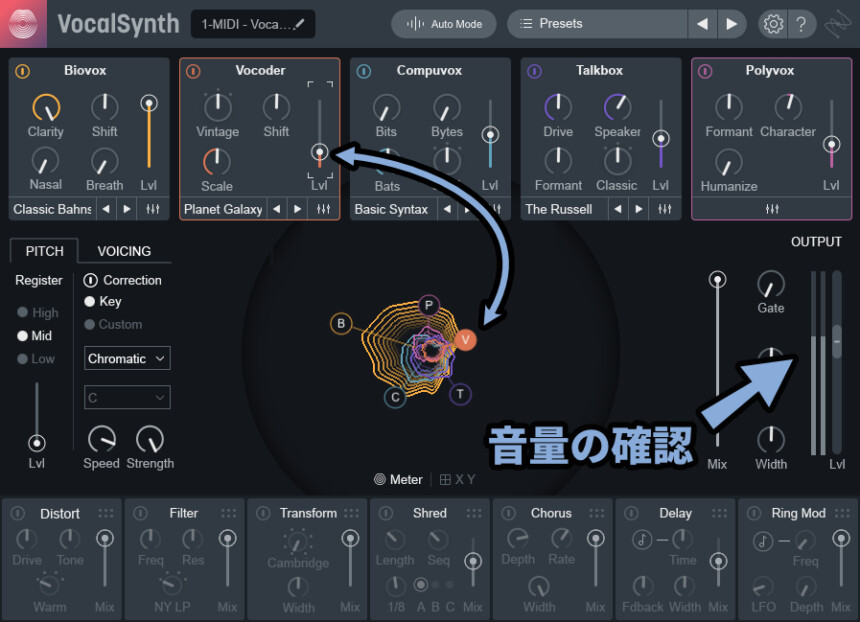
つまり、この真ん中の5つはミキサー的な働きになります。
下にある「X/Y」はのちほど解説。
(ほとんど使わないと思うので、最後の方で紹介してます)
Vocal Synth固有エフェクトはすべてオフにすると…
初期状態では音が出なくなります。
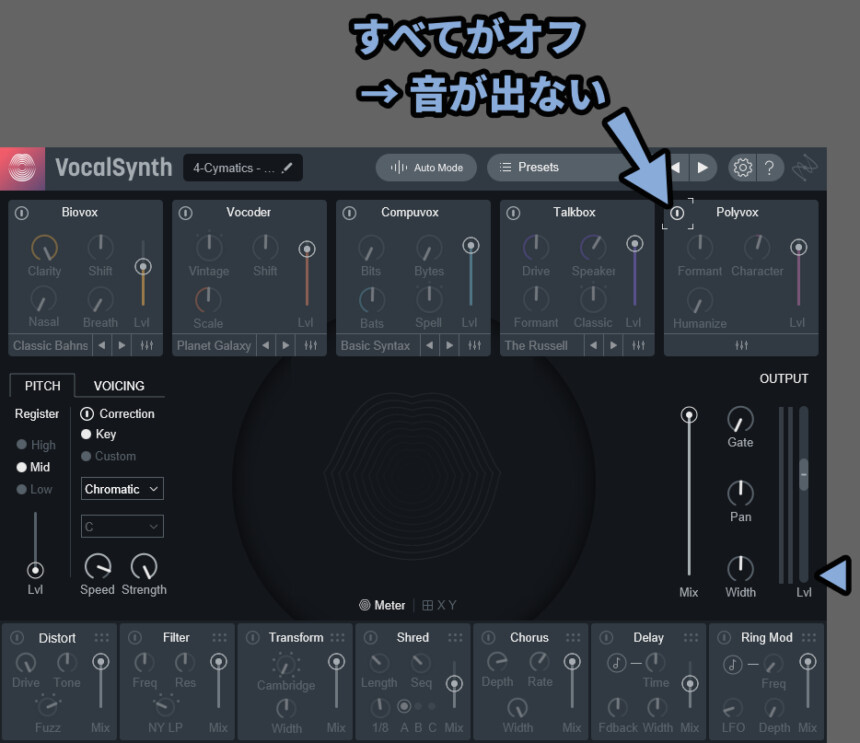
右側にある Mix が俗に言う「Dry / Wet」です。
なので、このMixを0にすると、元の音が表示されるのですべてオフでも音が出ます。
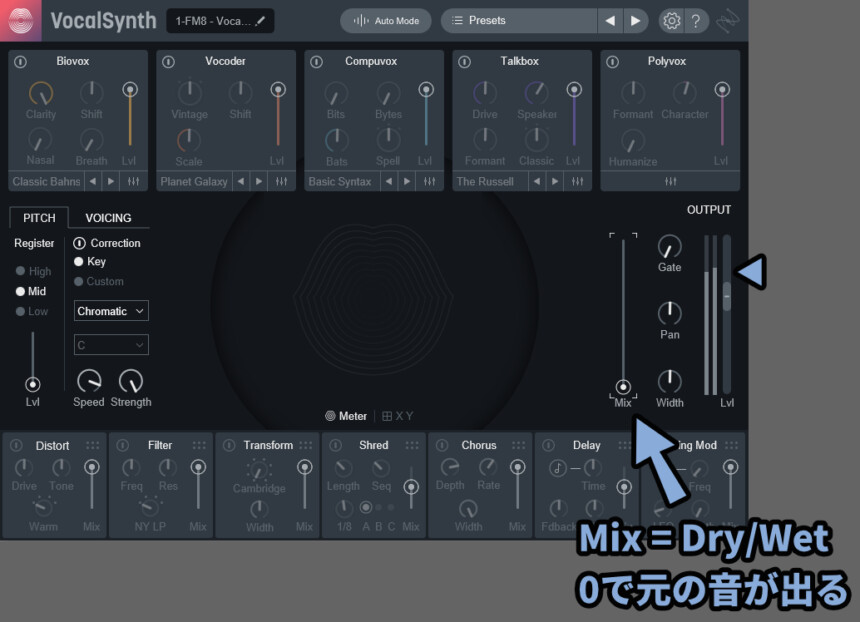
Dry/Wetは「エフェクト処理が入った音」と「処理前の音」が出力される度合いを調整する機能です。
・Mix最大 = Wet はエフェクトの処理が入った音だけ出ます
・Mix最小 = Dry はエフェクト処理が入る前の音が出ます
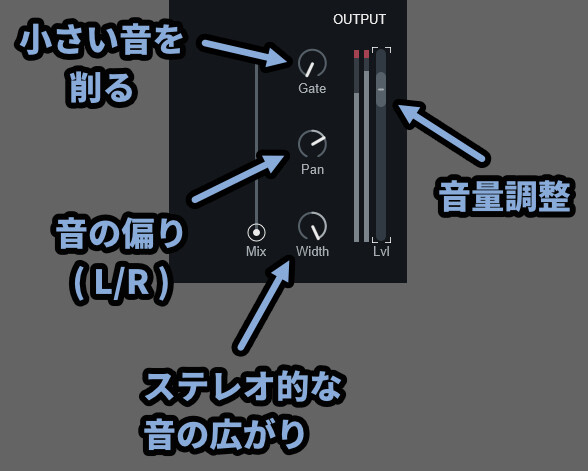
あと、右側の項目は下記の通り。
・Gate → 小さすぎる音を削る
・Pan → 左右に音を偏らせる
・Width → ステレオ的な音の広がりを作る
・Lvl → 音量調整(レベルの略)Gate以外は触ればすぐわかると思います。
Gateは、俗に言うノイズゲートです。
上げると小さい音を削ります。
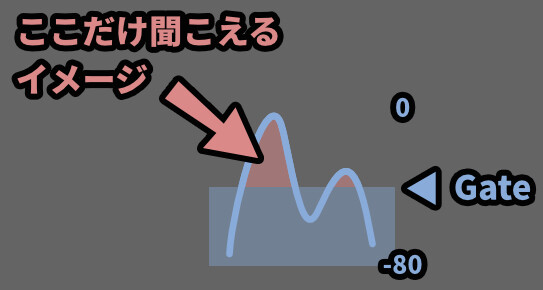
別の言い方をすると、大きな音が出てる所だけ聞こえるようにする機能です。
→ 録音の際に乗った小さなノイズの音を消すのに使えます。
以上が、Vocal Synth2の基本操作です。
マニュアルの確認
右上の「?」を押すとヘルプが表示できます。
ここで「日本語」表示のかなり細かいマニュアルが見れます。
ただし、このマニュアルは… ローカルデータのようです。
WEBサイトとしてデータが上がっておらず、PCの中にあるデータを表示してる形になります。
一応、WEBサイト版のマニュアルを探しましたが…
なぜかちょっとバージョンが違う+Google翻訳版のマニュアルしか見つけれませんでした。

これは、購入者限定特典…?
Vocal Synth2は処理負荷が高いので注意
Vocal Synth2は処理負荷が高めです。
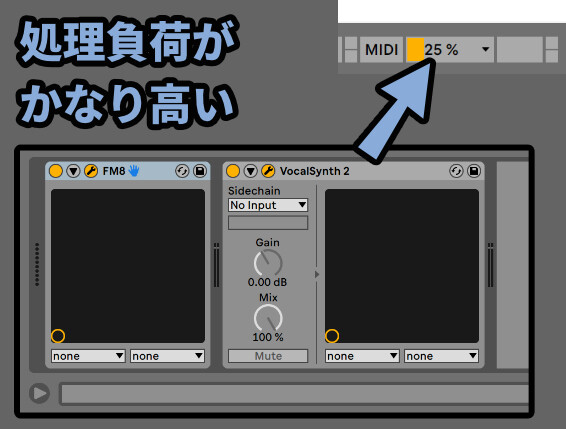
エフェクト無しでも、刺すだけで私のパソコンのCPU使用率が5%ぐらい行きます。
ちなみに、CPUはAMD Ryzen 7 3700X BOXを使用(2019-07-07)
その他のスペックは こちら をご覧ください。
ちょっと古いパソコンを使ってるので…
もっといいパソコンであれば、ここまで負荷が上がらないかもです。
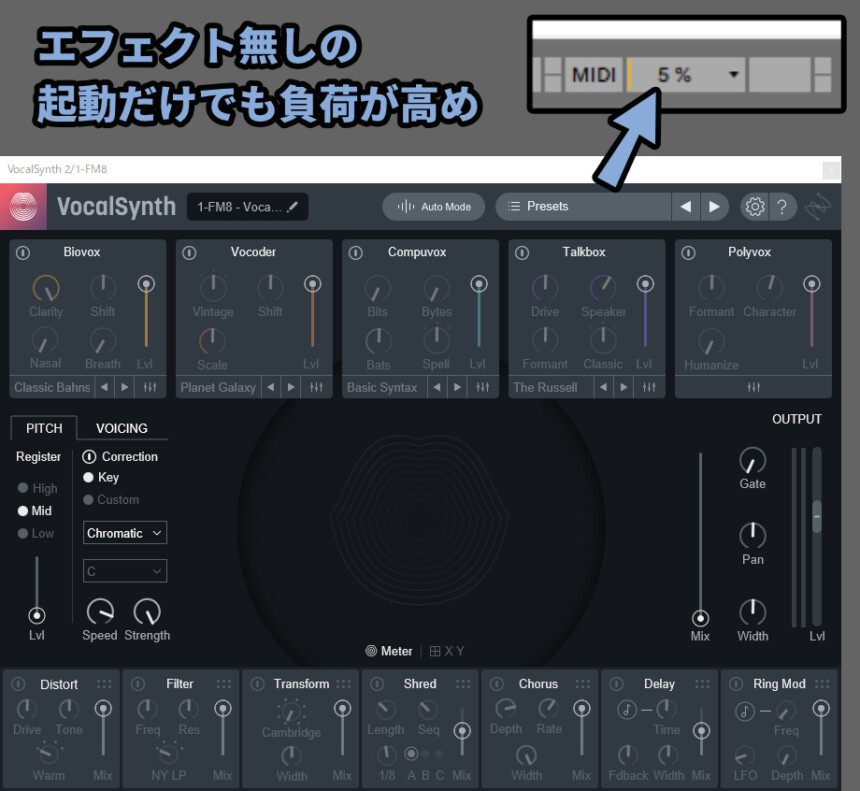
そして、エフェクトは何もせず “起動” しただけで負荷がかかります。
Vocal Synth2固有エフェクト5つを起動すると20%ぐらい負荷が行きます。
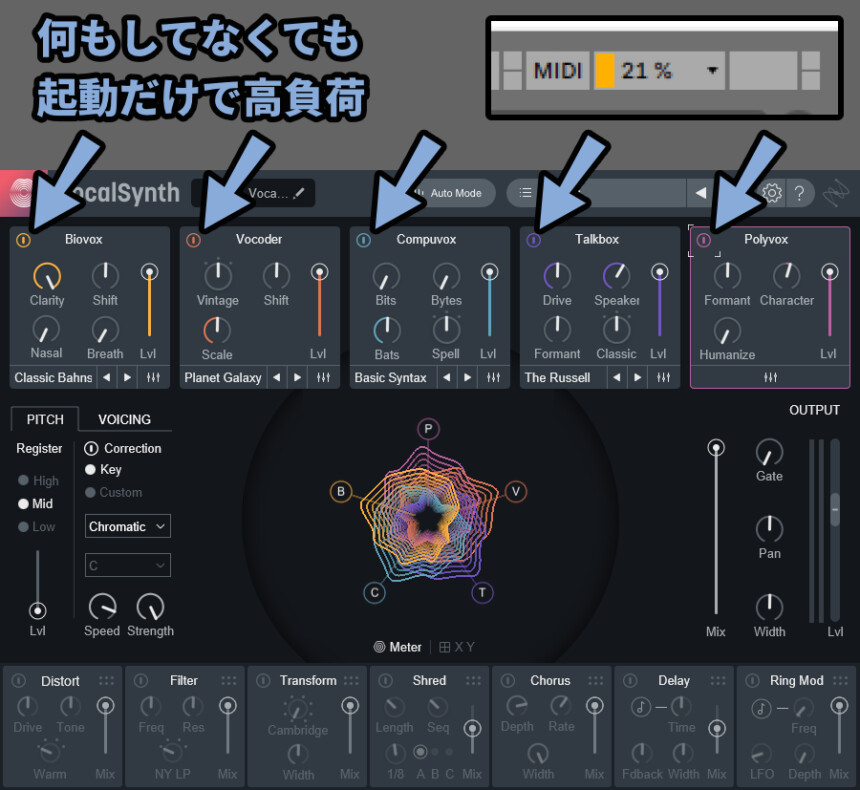
なので、Repro-5みたいな重いシンセに5エフェクト全部乗せを刺すのは…
難しいと考えてください。
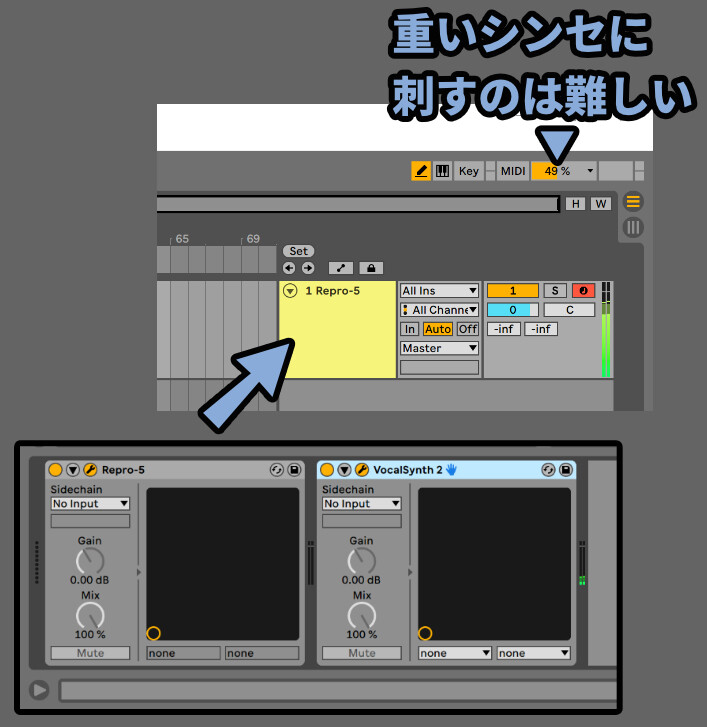
Vocal Synth2固有エフェクト2~3個使う。
それも音楽を形作る上で決定的な音源に対してだけ使う
みたいな工夫が必要になると思います。
以上が、Vocal Synth2は処理負荷が高い事の解説です。
プリセットを使う+保存する
プリセットは画面上部の「◀」か「▶」で選択できます。
だいたい1~3個、VovalSynth固有エフェクトが入ってる形です。
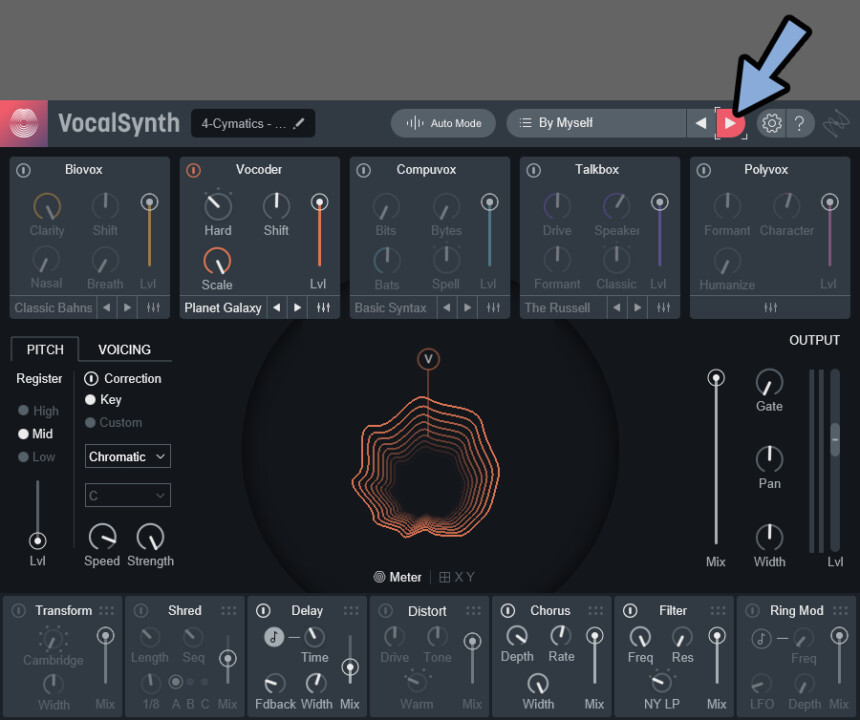
やっぱり、Vocal Synth2は重いらしく…
プリセットの多くは固有エフェクトが2~3個。
5個全部入ってるのはあまり無い
→ 想定されて無さそうな感じでした。
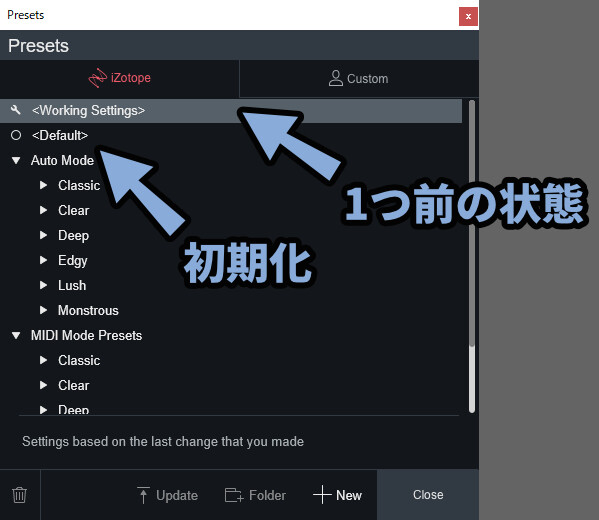
左側の「Presets」の文字を選択。
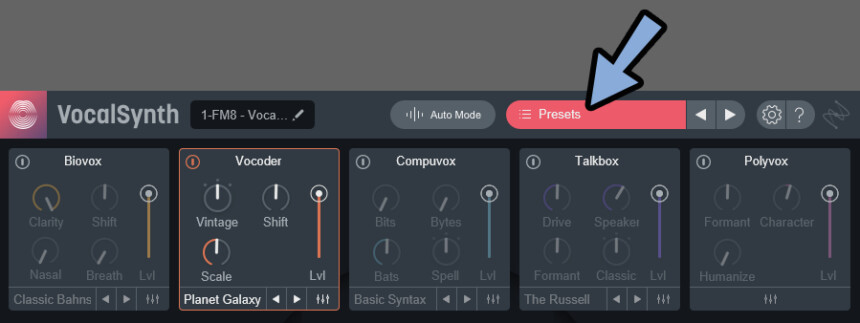
すると「Presets」画面が出せます。
ここでフォルダを開き、任意のプリセットを選ぶこともできます。
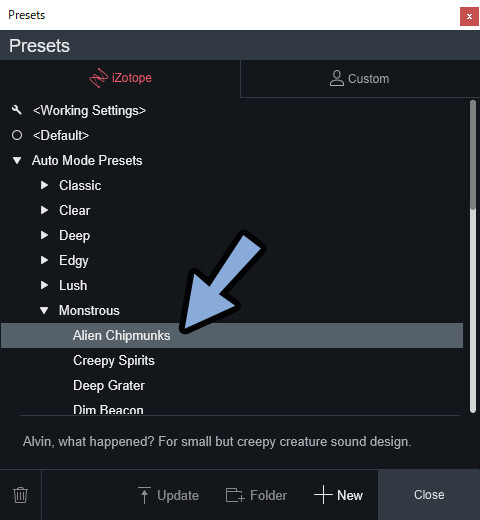
上にある2つは特別な設定です。
・Working Settings
→ 1つ前の状態に戻す(Prestes画面を開いた時の前の状態)
・Default
→ 初期状態に戻す(Vocoderが1つだけ刺さってる状態)↓ここで、操作できます。
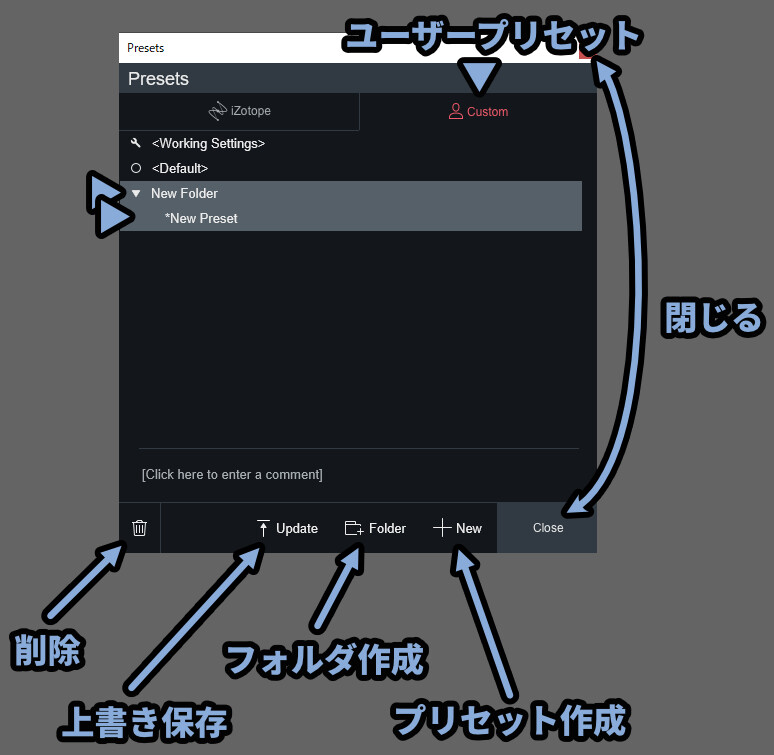
そして、右側の「Custom」を選択。
すると、プリセットを自作する際に役立つ画面を表示できます。
あと、iZotopeのプリセットは2つのフォルダに分かれてます。
・Auto Mode
・MIDI Mode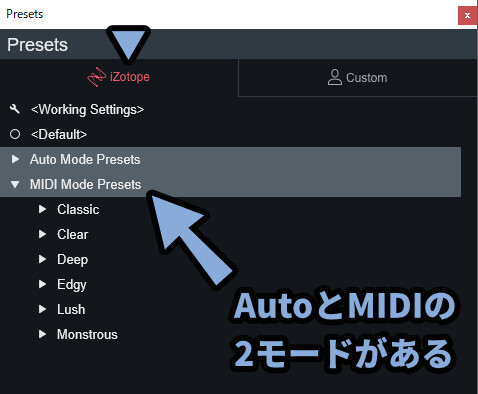
次は、この2つのモードの違いを理解するために必要な情報を紹介します。
Modeについて
Modeはプリセットの左側の所で設定できます。
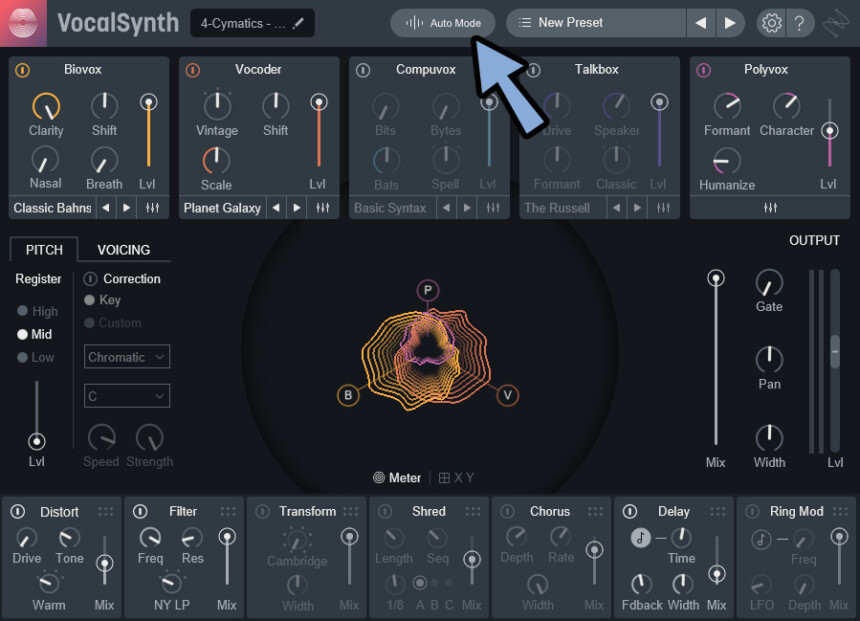
初期状態では「Auto Mode」になってます。
ここの左側で3つのモードが選べます。
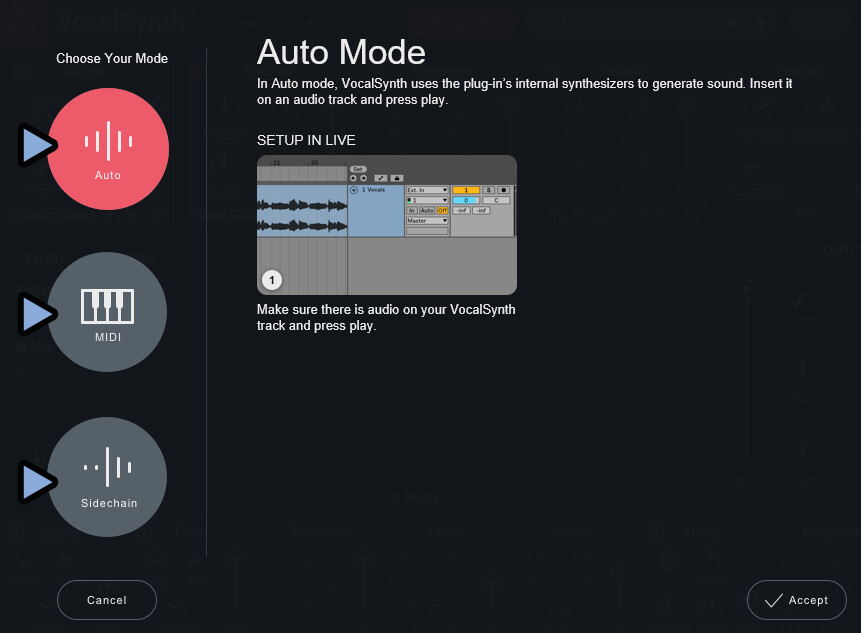
3つモードは下記の通り。
◆Auto Mode
・普通のモード
・音源に対して普通にエフェクトをかける
◆MIDI Mode
・別MIDIノートの入力による影響を受けるモード
・普通の音源に対してエフェクトをかけ、さらに別のMIDIノートの影響を受ける
・影響の受け方はVoicengで設定可能
◆Sidechain Mode
・別音源の入力による影響を受けるモード
・普通の音源に対してエフェクトをかけ、さらに別の音源の影響を受けるAuto Modeは普通のモードです。
特に何も考えずに使えます。
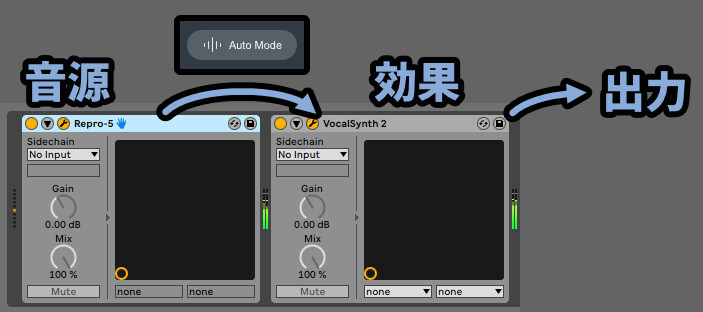
問題は「MIDI」と「Sidechain」です。
こちらを正しく動かすには別のMIDIや音源などのトラックが必要です。
選択すると、その設定方法が表示されます。
右下の「Accept」で決定。
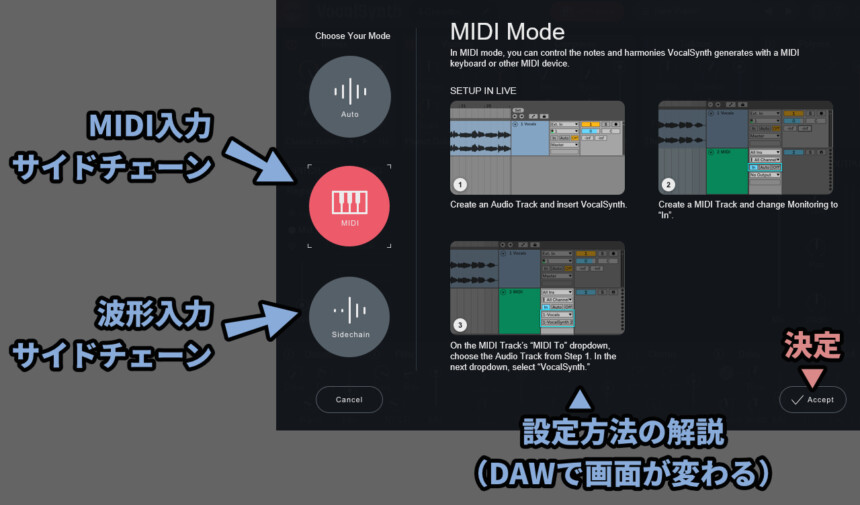
設定方法の表示は使用DAWによって変わるようです。
私はAbletonを使ってるので、Albetonの画面が表示されてます。
公式マニュアルの「DAWセットアップ」と内容とだいたい同じです。
↓つまり、こちらの図のDAWは説明表示が対応してると思います。(未検証)

「MIDI」も「Sidechain」まず、普通に音源を用意し、エフェクトとして刺します。
そして、別トラックを用意し対象を「トラック名」 で設定。
さらに「個別エフェクト(Vocal Synth2)」を指定という流れです。
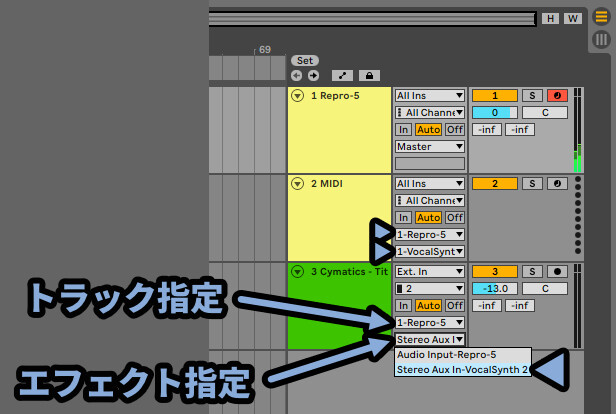
音は… 聞いた方が早いと思います。
↓こちらの動画で、設定の様子と出音は紹介。
あと、MIDI Modeの挙動はVoicingで制御できます。
以上が、Modeについての解説です。
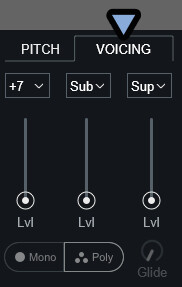
Voicingについて
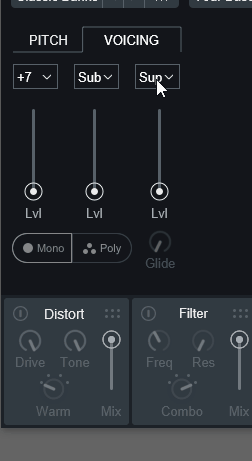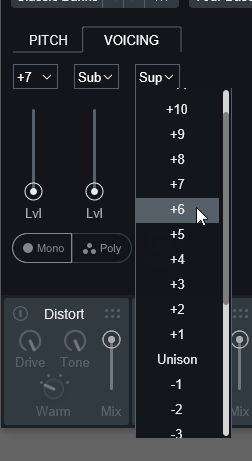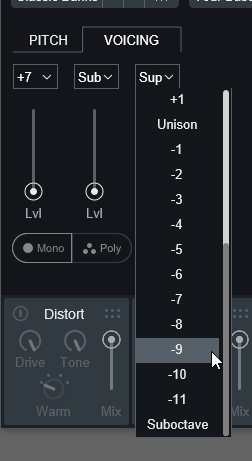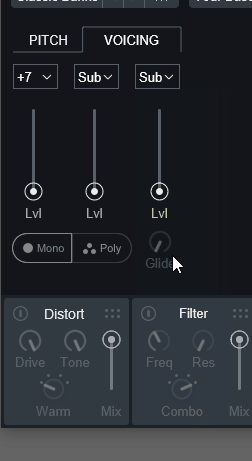
Voiceingはその音の出力にハーモニーとユニゾンを加えるものです。
・ハーモニー = 音程が違う音を重ねる(ハモリ)
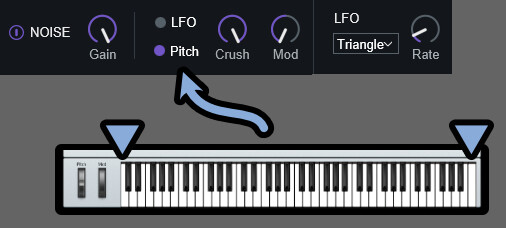
・ユニゾン = 同じ音程の音を重ねる(エフェクトのコーラス)これは、PITCH右側の「VOICING」を押すと表示できます。
そして、Modeによって挙動が異なります。
・Auto Mode → 入力した音からハーモニー/ユニゾンを作成
・MIDI Mode → MIDIノートを外部入力してハーモニー/ユニゾンを作成
・Side Chain → 動作なし↓そして、設定できる場所も変わります。
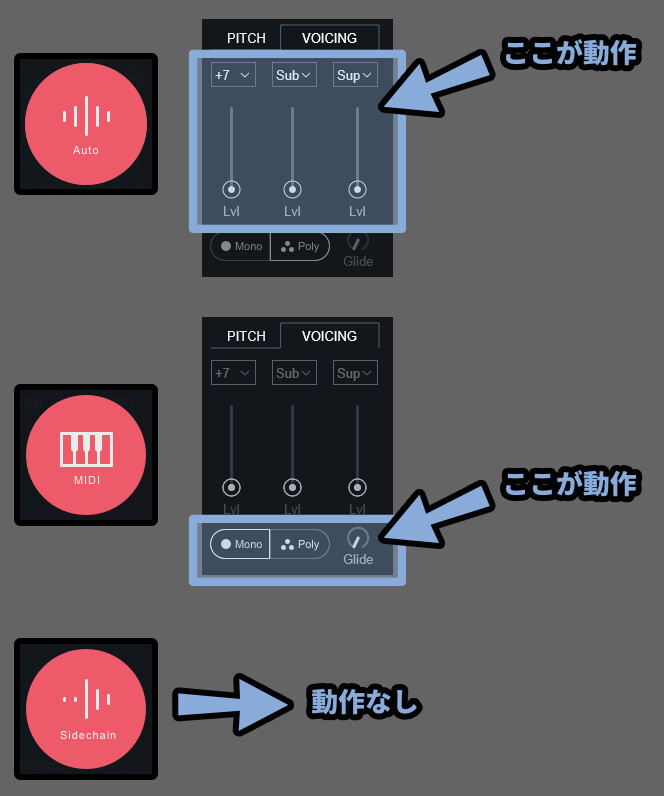
注意点は5つの固有エフェクトを使用した時しか動作しないことです。
(PITCH Lvlと下の7個のエフェクトでは動きません)
まず「Auto Mode」でのVoicingを見ていきます。
こちらは、ハーモニー/ユニゾンを最大3つまで追加できる機能になります。
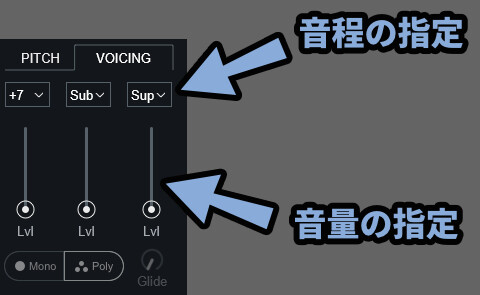
上の所で重ねる音の音程を設定します。
±12半音(±1オクターブ)まで設定可能。
Unisonに設定すれば、音程の差が無くなり音の厚みが増えます。
↓そして、こんな感じの音になります。
次に「MIDI Mode」での挙動を見ていきます。
こちらは、MIDIサイドチェーン入力のかかり方を変えれます。
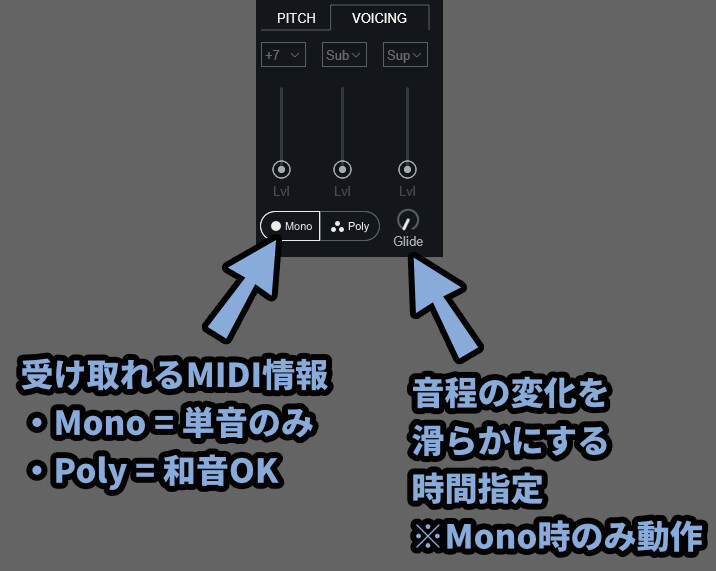
・Poly → 別MIDI入力の "和音" を受け取れる
・Mono → 別MIDI入力の "和音" を受け取れない(単音のみ)
・Glide → 2つの音程の変化を緩やかにする量(Mono時のみ設定可能)Glideは俗に言う、ポルタメント機能です。
↓こんな感じの音になります。
以上が、Voicingについての解説です。
ピッチ補正の調整
Vocal Synth2には入力した音を特定のピッチに合わせる処理があります。
こちらは画面中央左側にあります。(PITCHを選択で表示)
・Register [High / Mid / Low]
→ 指定した音程に対して処理を強く出す(要するに音色調整)
・Lvl
→ 入力した音の音量調整(表示するかどうかを調整する)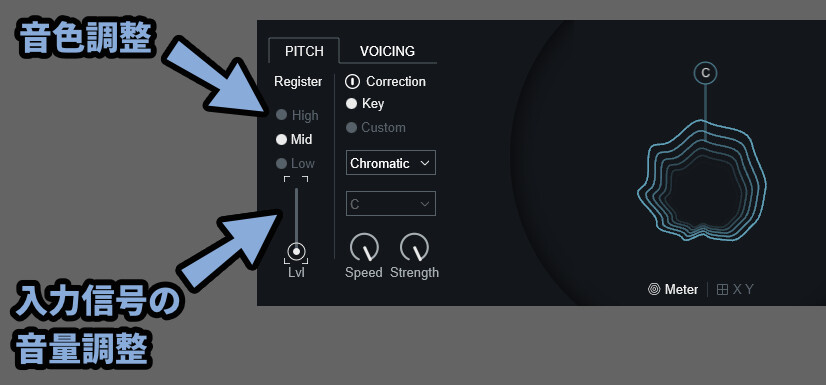
このPITCHにあるLvlは、右側のMixとは違い何かしらの処理はが入ってるようです。
なので、音的には少し劣化したモノになります。
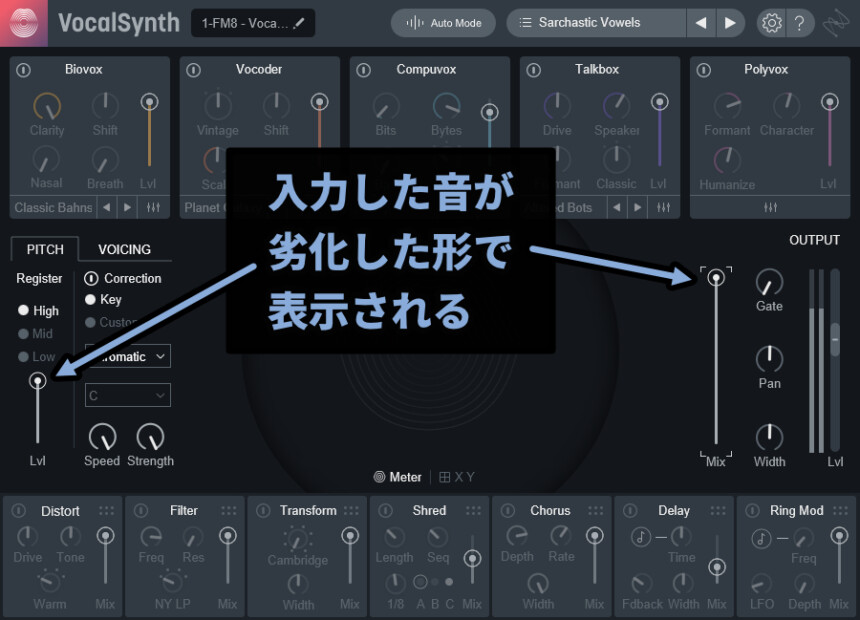
なので、入力前の音を入れたい場合は…
OUTPUTの「Mix」下げる形で操作してください。
Correctionはピッチ補正を入れるかどうかです。

では「Correction」を無効にしてLvlを上げると元の音が綺麗に聞こえるのでは…?
と思うかもしれませんが、何故かこの状態でも劣化して聞こえました。

劣化してるというより「ステレオ感」が完全に消える形になります。
↓詳細はこちら。
ちょっと詳細は謎ですが…
なぜか、音のステレオ感が削られて聞こえます。
Correctionをオンにすると、下にある項目を設定できます。
このピッチ補正は2通りの表示で内容を調整できます。
・Key表示
→ 標準的な12音階のスケールから補正対象のピッチを決める
・Custom表示
→ 人力で12音階から補正対象のピッチを決める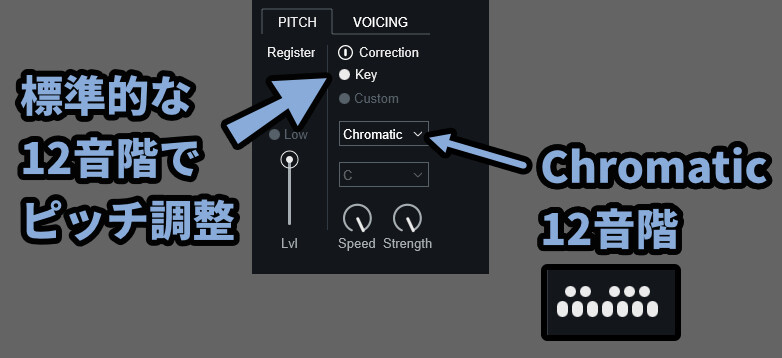
Keyで選べる内容は下記。
・Chromatic → 12音階全てに対して補正を有効
・Major → 下で指定した音階のメジャースケールで補正
・Minor → 下で指定した音階のマイナースケールで補正下の部分を選ぶと12種類の7音階で補正先を決めれます。
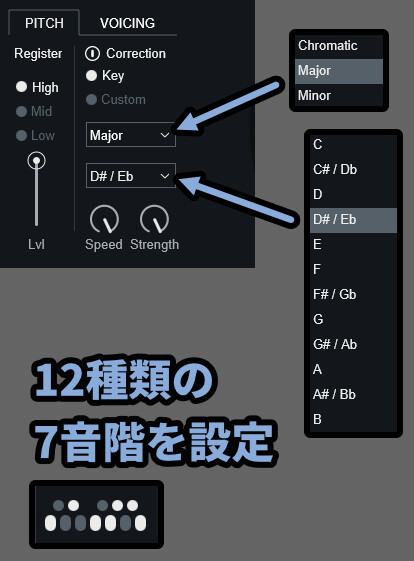
公式的に、よくわからないのであれば…
「Chromatic」でGo!みたいな感じでした。
↓メジャーやマイナースケールの7音階についてはこちらで解説

そしてCustomは12音階から自分で補正先を選ぶ形になります。

あと、補正具合は下の所で設定できます。
・Speed → 補正が入るまでの速さ
・Strength → 補正の強さ
以上が、ピッチ補正についての解説です。
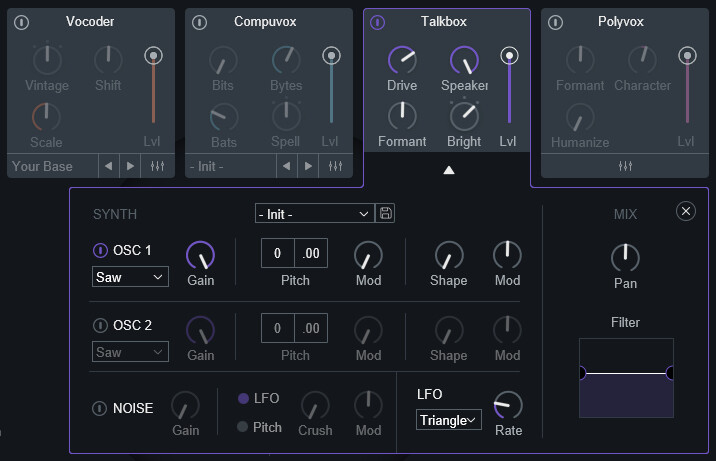
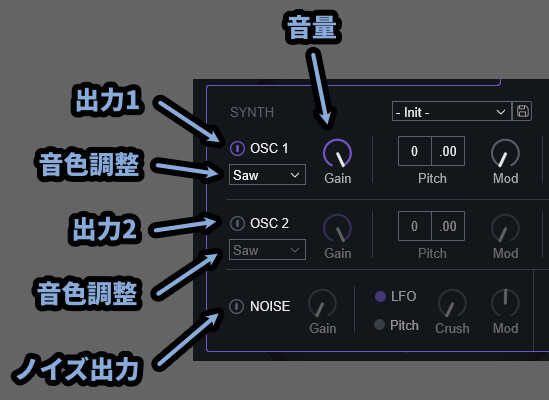
5つの固有エフェクトについて(上部)
左上の電源ボタンで5つのエフェクトをON/OFF切り替えれます。
ONにすると、画面中央に頭文字が表示されます。
それぞれのエフェクトの意味は下記。
・Biovox = 音に人の声っぽさが入る
(人間の体をベースにした、調音音声合成を使った音加工)
・Vocoder = ロボットボイスっぽくなる
(2つの音声を周波数帯分けて合成して音を作る処理)
・Compuvox = 粗くて強い音、ヘビーメタルやモンスターの声みたいな音になる
(声用に調整された線形予測符号化を使った音加工)
・Talkbox = おしゃれでエモい感じの音がなる
(トークボックスという機材の再現)
・Polybox = ボイスチェンジャーっぽい感じで声質が変わる
(フォルマントの調整)あと、固有エフェクトは音に変化を加えてるというよりも…
入力した音を再解釈し、内蔵されてるオシレーターで音が鳴らされてる。
みたいな感じの方がイメージに近い、分かりやすいと思います。
(「Biovox」や「Compuvox」など)
私も結構、理解するまで時間がかかりました。
(公式が出してるマニュアルは分かりやすい方だったので…
純粋にやってる事が難しいのだと思います)
固有エフェクトのプリセットについて
5つの固有エフェクトは詳細設定にプリセットを持てます。
試しにBiovoxの右下を選択。
すると、詳細設定を表示できます。
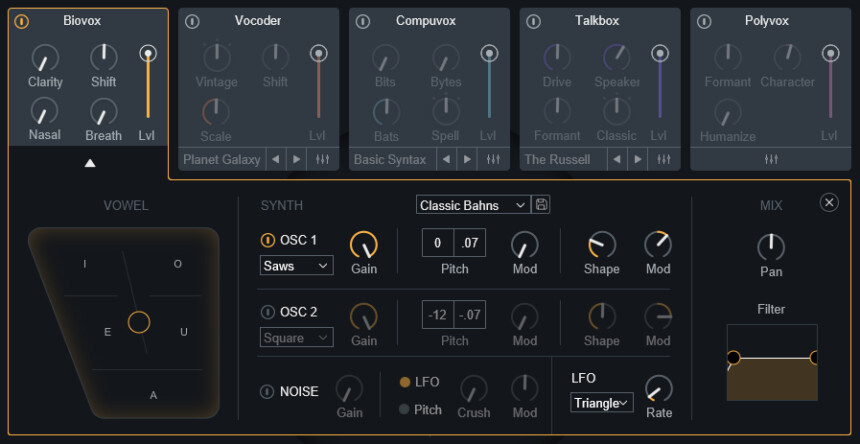
“Polyvox”以外の4つの固有エフェクトは…
同じ操作が行えます。
「▲」か「×」を押すと拡張表示を消した状態に戻せます。

そして、Vocal Synth2は、この拡張表示の部分だけプリセット化できます。
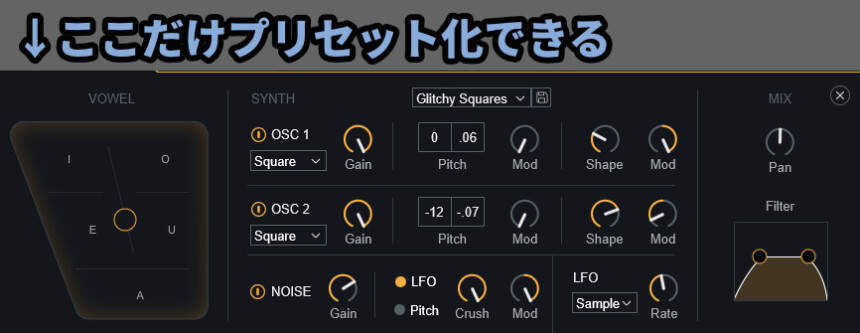
上部の文字でプリセットを読み込めます。
右側でプリセットを保存することも可能です。
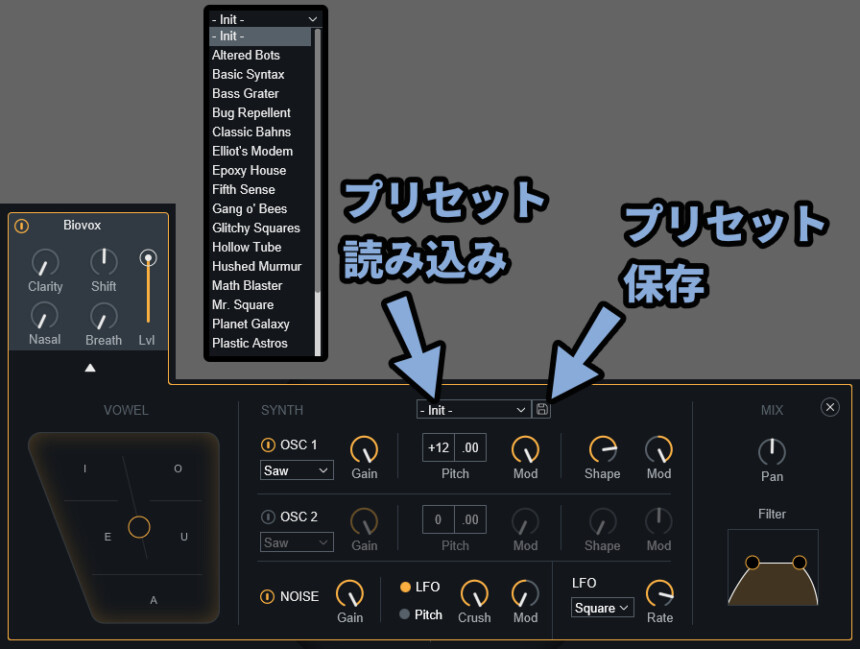
あと、縮小表示にすると「◀ / ▶」でプリセットを切り替えれます。
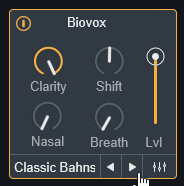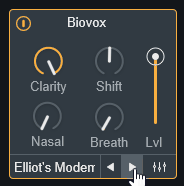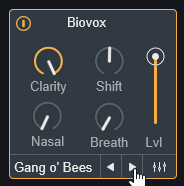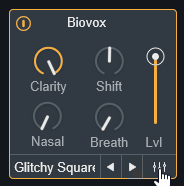
保存を押すと、名前を入力する場所が出ます。
ここで、既存プリセットと被らない名前を入れると保存できます。
既存プリセットと同じ名前を入れるとエラーが出ます。
上書きはできず、エラーで終わります。
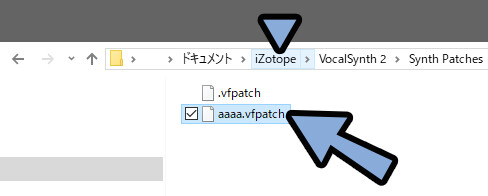
制作したプリセットは直接消す必要があります。
ドキュメント内などにある「iZotope」フォルダを開きます。
そしてVocalSynth 2 → Synth Patchesを開き「○○.vfpatch」を削除で消せます。
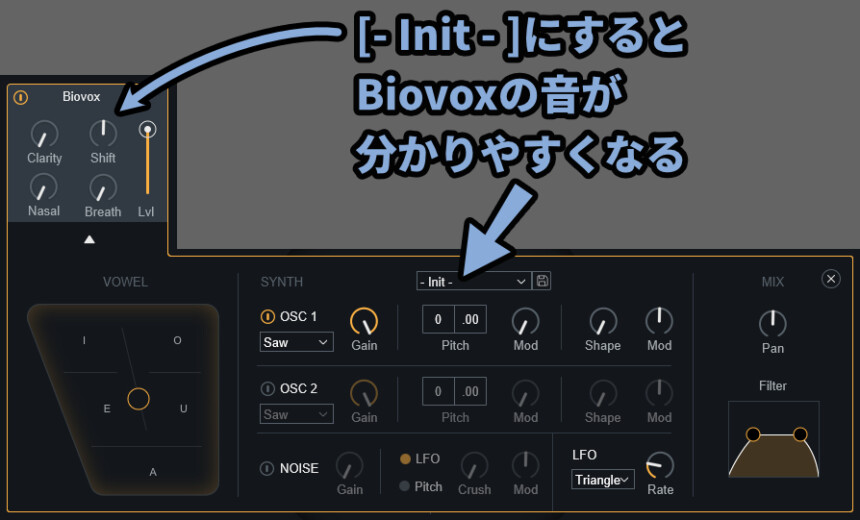
プリセットに関しては、学習段階では「- Init – 」がおすすめ。
一番シンプルな構造で、変化が分かりやすいと思います。
以上が、プリセット関係の解説です。
Biovox
Biovoxは、人間の体をベースにした音加工ができます。
より詳しく書くと下記。
【Biovox】
・調音音声合成を元にした音加工
・調音音声合成は声帯 → 声道 → 口までの流れを再現する
・鼻声、息遣い(気息音)、声道の長さなどが設定可能この人の体をベースにした音の考え方を調音音声合成と呼ぶようです。
調音音声合成(アーティキュレートリー・シンセシス)の詳細はこちら等に書かれてます。

これを使った音はこちら。
Biovoxの右下を選択。
すると、詳細設定を表示できます。
そして、大まかな処理を紹介するとこちら。
FMシンセ的な要領で、無理やり名前を付けると下図のような感じになります。
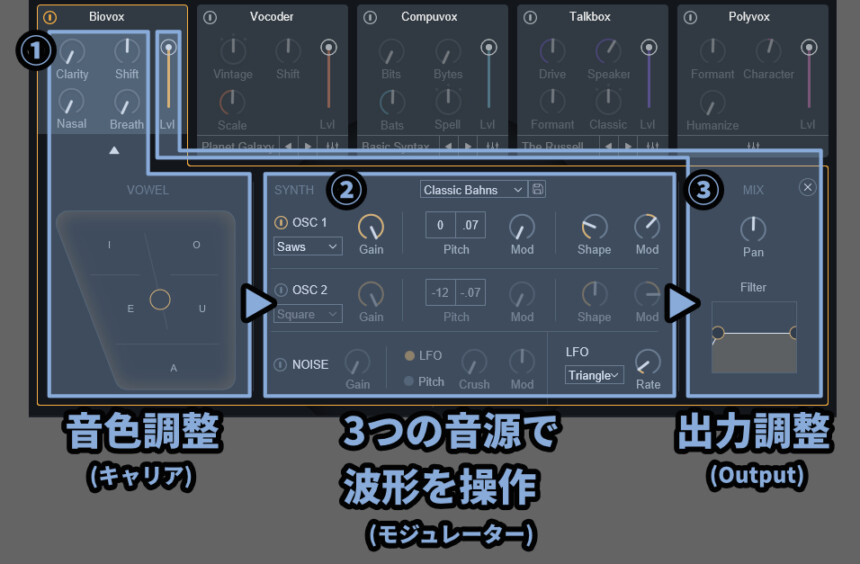
キャリア → 影響が与えられる前の波形
モジュレーター → 波形で波形に影響を与える部分
Biovoxの音は、②の所で作られた3つの波形の影響を受けて出力される。
(回避はできない)
公式の説明書では、ここのSYNTHは下記のように書かれてました。
【原文】
オシレーターとモジュレーションの設定をコントロールして、
Biovoxのシンセ・エンジンを通して再生された音(演奏されたノート) を
変化させることができます。
【要約と私の解釈】
②の部分を操作すると、
①で操作した音に
"変化"を加えれます。
→ なので、ここではこの3つのオシレーターは「モジュレーター」という表記にしました。そして注意点がSideChain Modeの場合、入力した波形が「モジュレーター」になる事です。
そして、3つの内蔵モジュレーターは無効化されます。
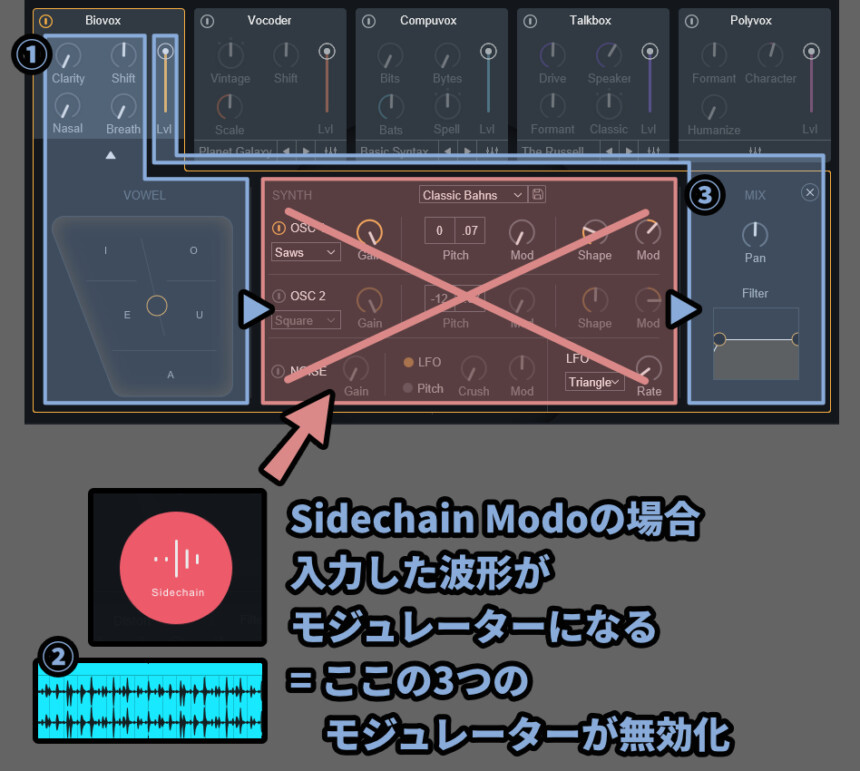
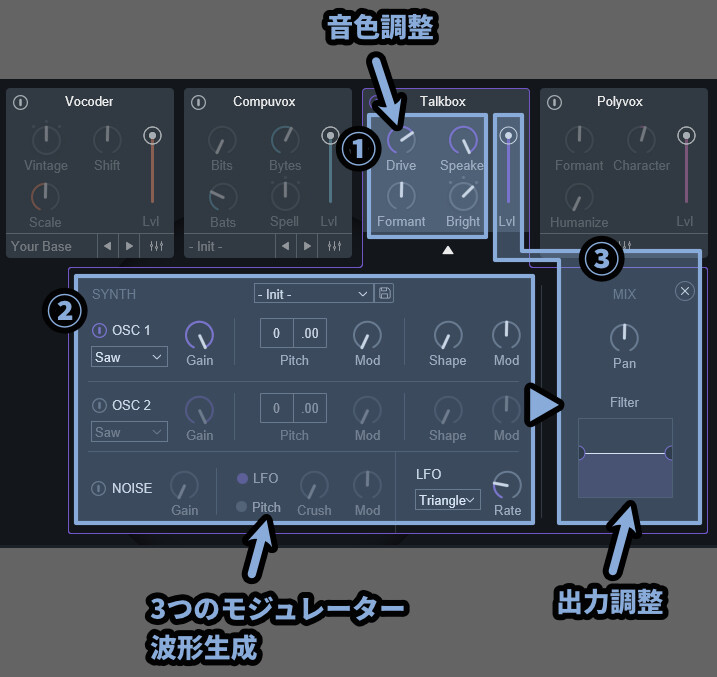
そしたら、最も簡単な「➂」だけ先に解説します。
➂の全体の出力調整で使える項目は下記。
・Lvl → Biovox全体の音量
・Pan → 音を左右に動かす(L/R)
・Filter → 低音/高音をカットするフィルター
あとは、ちょっと難易度が上がるので章を分けて解説していきます。
音作り系の要素
音作りの要素は下記の5つ。
・Clarity → 影響度を強くする
・Shift → 低音/高音の強調(声道の長さ)
・Nasal → 鼻声っぽさの調整
・Breath → ウィスパーボイス感の調整(息遣い、気息音)
・VOWEL → 母音発生時の下の位置を舌にした音色調整ここは、無理やりFMシンセ風の名前を付けるなら「キャリア」です。
ようするに、普通に波形を調整できます。
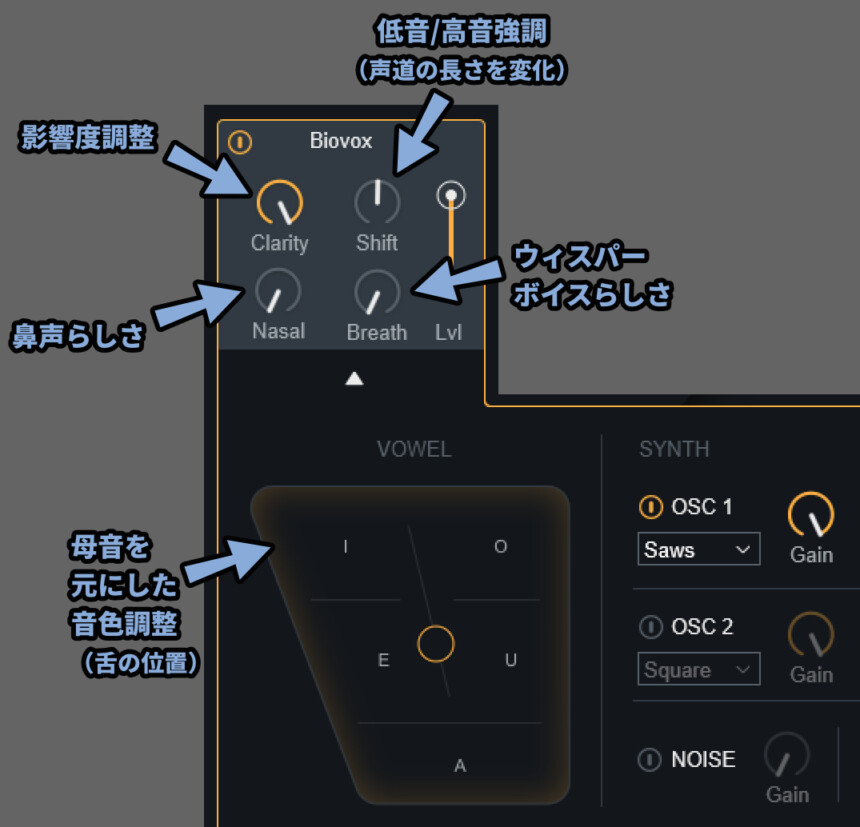
ShiftはBreathを上げると少し変化が分かりやすくなります。
Clarityを上げると、さらに変化が分かりやすくなります。
VOWELはこちらの「IPA:Vowels」を元にしたモノらしいですが…
正直、一般人はよくわからないので音色調整と思っておくぐらいが良いと思います。
Clatityは影響度のようなモノですが、0にしても音に変化が生まれます。
なので気持ち影響度が変わる感じと思ってください。
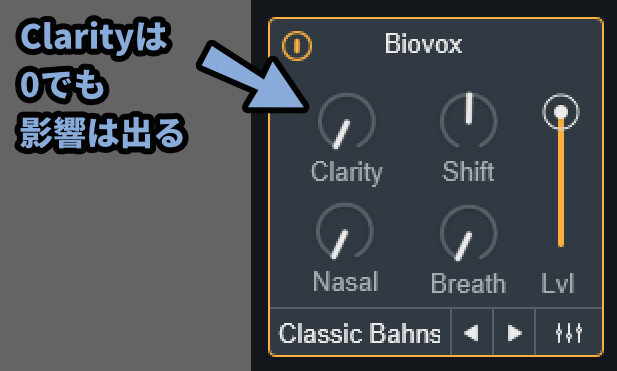
Clarityが0でも、SYNTHのところで特定の波形の影響を受けます。
この内蔵モジュレーターの影響を受けて音色は変わります。
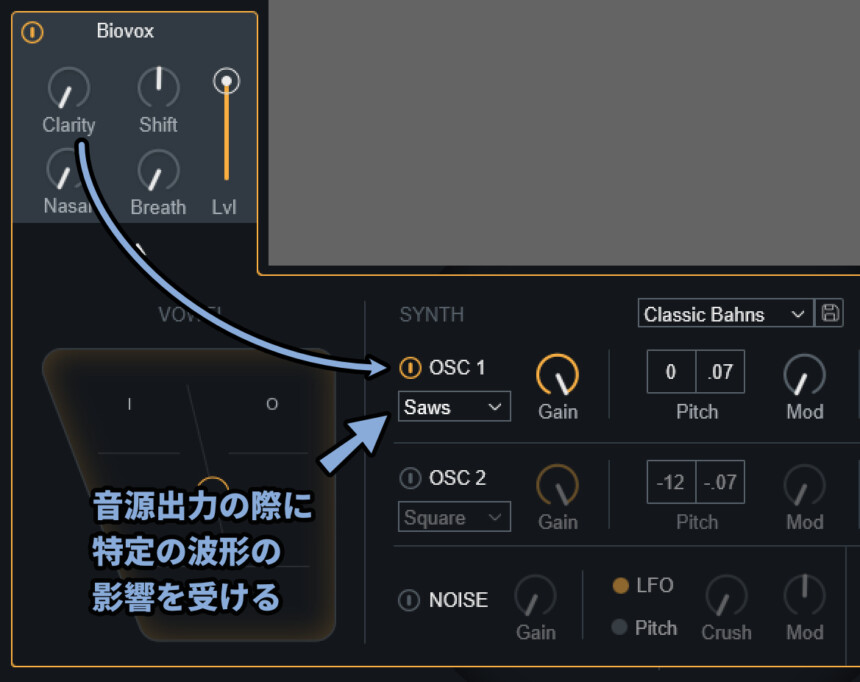
OSC1/2をオフにすると、音が消えます。
つまり、ClarityでBiovoxによる音の影響は完全に消せません。
以上が、音作り系要素の解説です。
3つのモジュレーターについて
次は「②」の3つのモジュレーターについて見ていきます。
※便宜上、FMシンセの名前を借りて「モジュレーター」と読んでますが…
Vocal Synth2の正式名称では無いので注意。
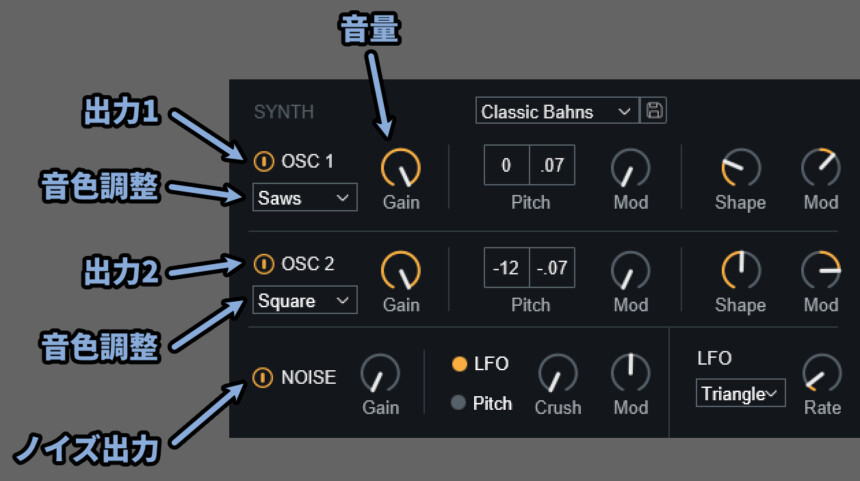
まず、左側部分は下記の通り。
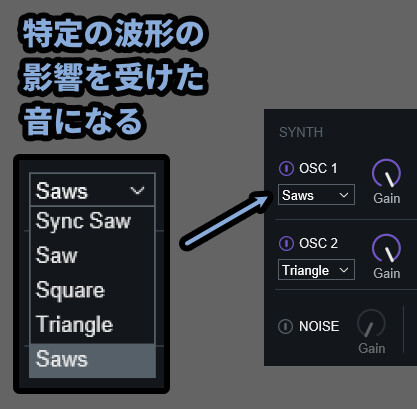
・OSC1/2 → 出力のオン/オフ
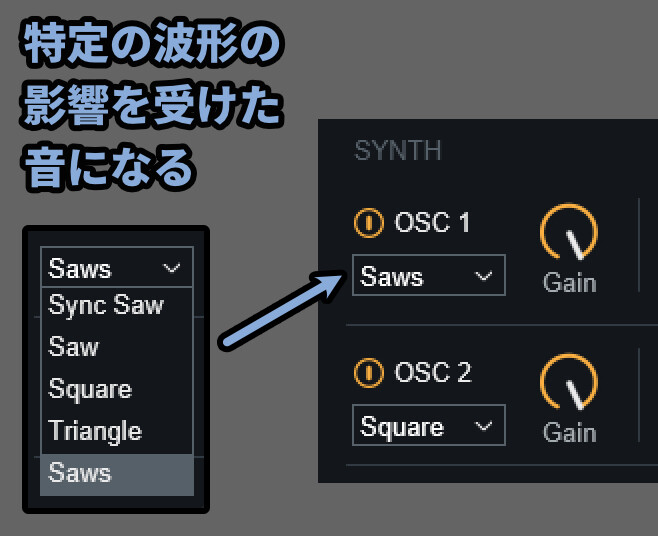
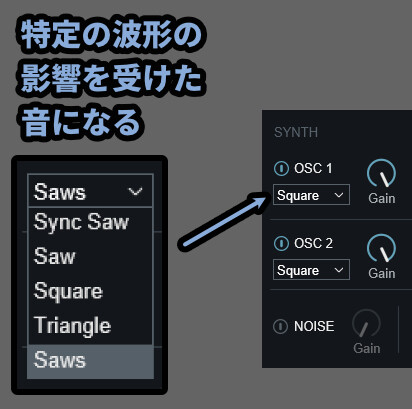
・OSC下にある波形名 → 入力した音を元に、特定の波形に変換して出力(音色調整)
・Noise → ノイズ出力のオン/オフ
・Gain → 音量SYNTHは最大3つの波形を新たに作り出せます。
(OSC1/2 + Noise)
そして、SYNTH部分は調整された音を受け取って、この3つの波形で音に変化を加えてます。
FMシンセで言う「モジュレーター」的な事をやってます。
→ つまり「元の波形(加工済み)」と「新たに生成した波形」の2で音を加工してます。
そして、この波形は1つでも入れてないと音が出ません。
つまり、モジュレーター的な働きで音に変化を加えてるというよりは…
入力した音を元に、SYNTHの波形を合成して
新しく音を作り直してる感じの事をやってるようです。
なので、ここの「波形」を変えるだけでも音色が大きく変わります。
OSC1/2の右側の項目は下記。
・Pitch左 → 半音単位で音程を操作(±24が上限(2オクターブ))
・Pitch右 → 半音以下の音程を操作(±50が上限)
・Pitch内のMod → PitchにLFOによる変化を与える度合い
・Shape → 音色調整(波形を操作)
・Shape右のMod → ShapeにLFOによる変化を与える度合い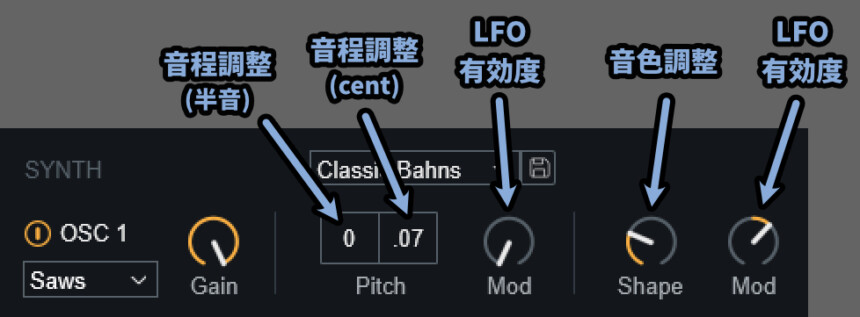
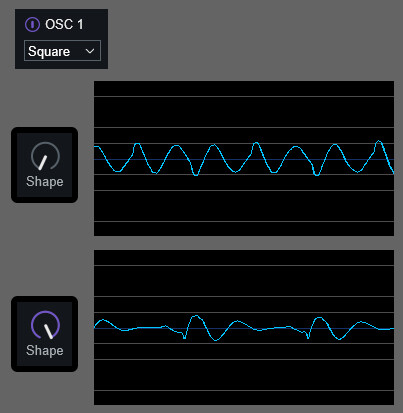
ShapeはSquareにかけると俗に言う「PWM」みたいな挙動になります。
波形の幅が変わります。
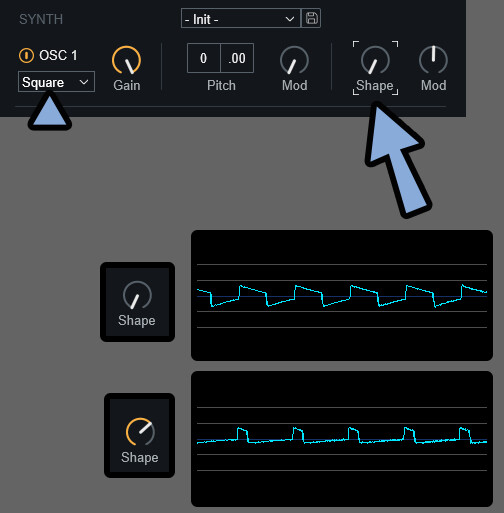
Sawなどにすると… 波形の形が大きく変わります。
大体の波形はこんな感じの挙動になります。
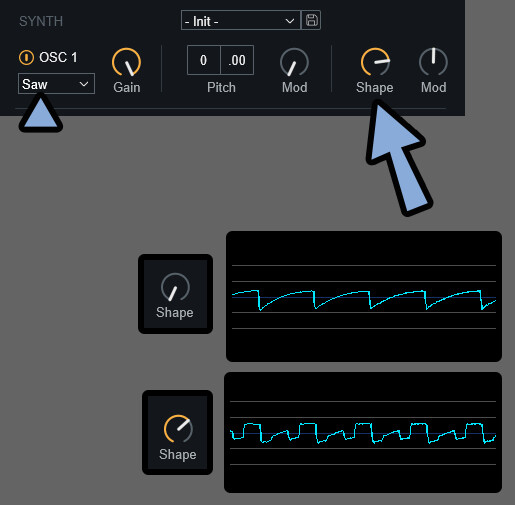
設定した波形によって挙動が少し変わるようです。
なので、Shapeに関しては波形を操作するところとしか言えいません。
右側のModはLFOの有効度です。
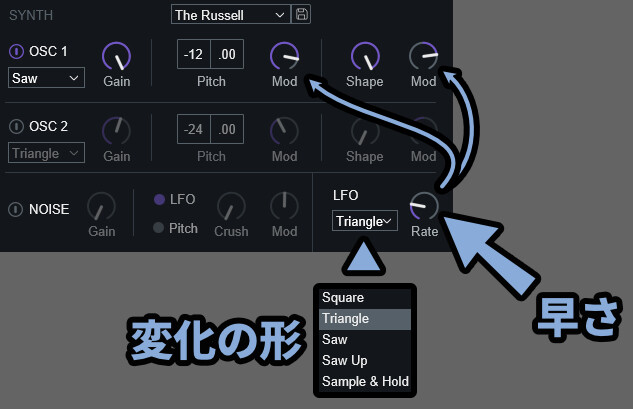
そしてLFOは右下の所で設定できます。
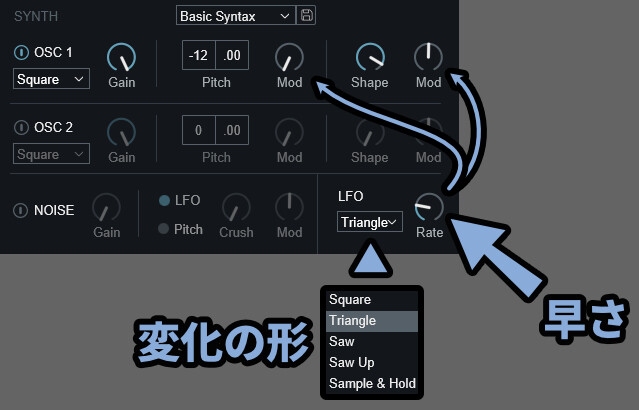
・LFO → 特定の波形を元にして音に変化を加える処理
・波形 → LFO左側の項目で操作
・Rate → LFO変化の速さ(波形の幅)だいたいは、他のシンセと同じなので分かると思います。
※分からなくても、触れば変化が分かります。
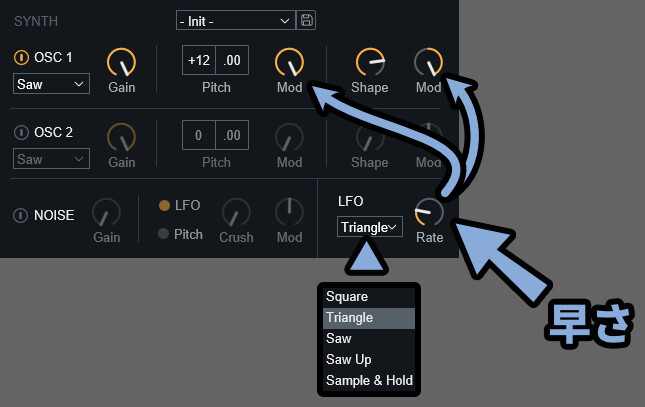
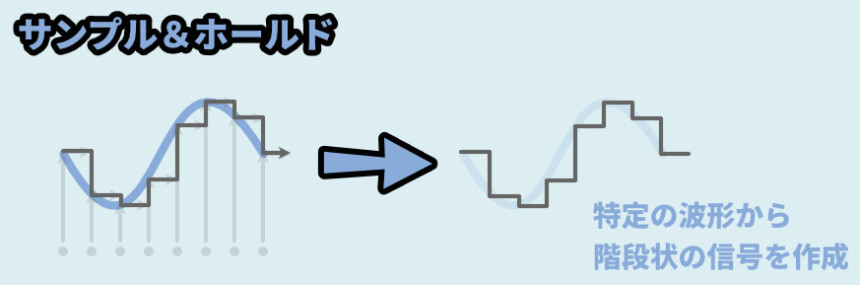
難しいポイントは「Sample & Hold」です。
まずサンプルはサンプリングの意味。
これは波形から適当な間隔でその高さを取る処理です。
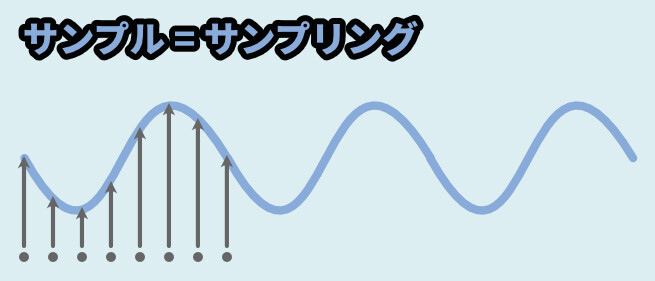
そして、ホールドは次のサンプリングまでその位置をキープする処理になります。

なので、入力した音から階段状の波形を作る処理です。
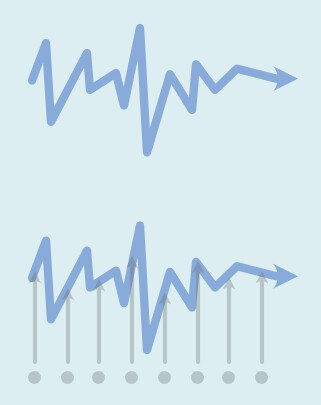
しかし、Voval Synth2の「Sample & Hold」には入力する波形がありません。
これはどうやら、ランダムの波形を見えないところで入力してる形になるようです。
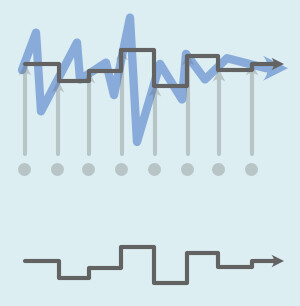
なので、ランダムな高さを一定時間で出力する処理になってます。
以上が「OSC1/2」と「LFO」関係の解説です。
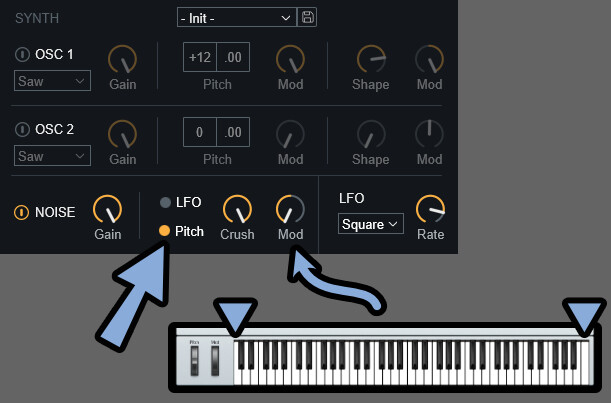
そしたら、次は「Noise」です。
・左側のボタン → Noiseのオン/オフ
・Gain → Noiseの音量
・LFO/Pitch → 変化のかけ方
・Crush → 音色調整(ホワイトノイズなど)
・Mod → LFO変化の影響度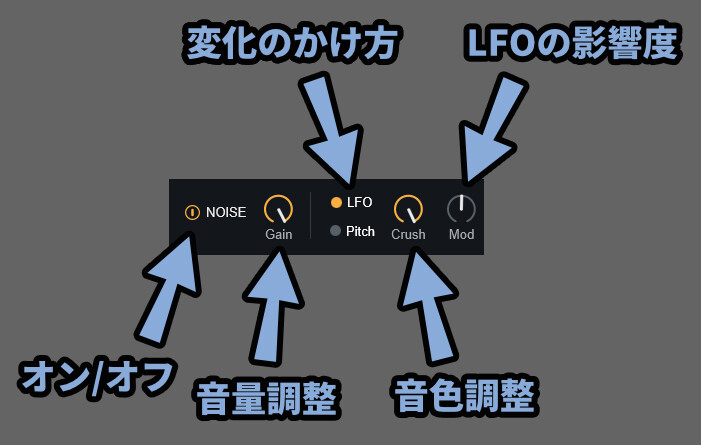
Modの値はマイナス値に設定できます。
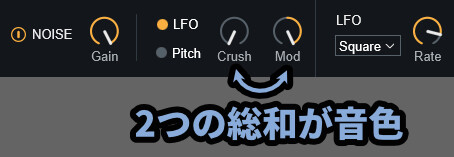
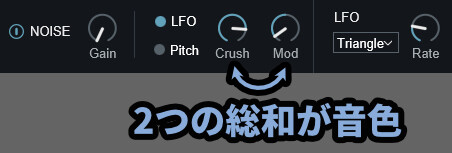
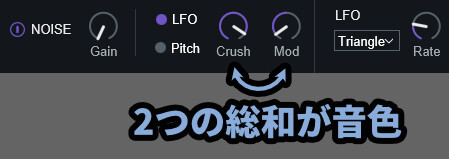
注意点は、変化量は「Crush」と「Mod」の2つの和によって決まります。
つまり、足し算です。
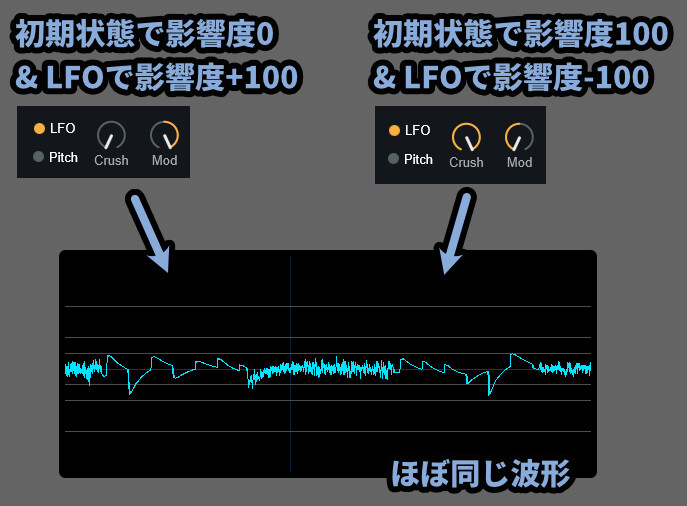
なので「Crush=0 / Mod=+100」と「Crush=100 / Mod=-100」はほぼ同じ波形になります。
あと変化のかけ方は「LFO」と「Pitch」の2通り選べます。
LFOは普通にLFOで変化量を操作する設定です。
Pitchは音程によって変化量を操作します。
以上が、Biovoxについての解説です。
Vocoder
Vocoderは、ロボットっぽい声を作るヤツです。
より詳しく書くと下記。
【Vocoder】
・2つの波形入力を使って新しい音を作る装置
・入力した波形は複数の周波数帯に区切られて処理が行われる
・動かすには "キャリア" と "モジュレーター" の2波形が必要
・これを使うと、ロボットぽい声が作れることで有名になったリアル機材だと、鍵盤にマイクが付いた形が多いです。
このように “楽器音” と “声” の2波形を取得して音を作るエフェクトになります。
一般に、楽器音(バイオリンなど)をキャリアに入力。
声(ボーカルなど)をモジュレーターに入れて使う形になります。
人間の体で例えるなら、キャリアが声帯、オシレーター的な部分、ただ震えてるだけの信号。
そしてモジュレーターが声道で、音の形を作る部分になります。
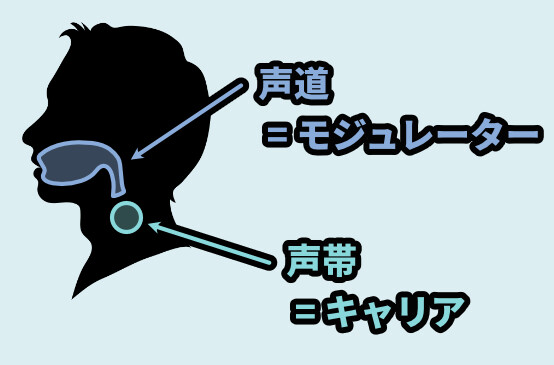
↓これの装置全体がモジュレーター。
3:06に出てる発信機的なパーツがキャリアだと考えてください。
FMシンセ的な間隔では、キャリア = 音の土台ですが…
Vocoderは “モジュレーター” が音の土台的な部分になります。
ここでの土台 = 音の印象を形作る主要な要素と考えてください。(音程など)
FMシンセなどを学んでると体感と反しますが…
Vocoderはモジュレーターが音を形作るの主要な部分。
キャリアが音色に変化を加える部分みたいな扱いになります。
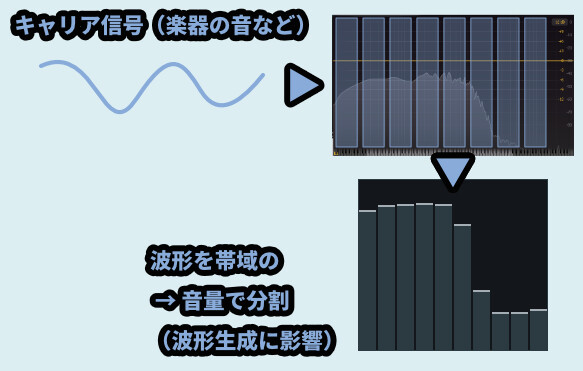
Vocoderの処理的な事を言うと… キャリア信号の音はEQの要領で分割されます。
そして分割された音の情報はモジュレーターに「音量」や「波形(音色)」として入力されます。
モジュレーターも同様に音をEQの要領で分割します。
そしてキャリアから受け取った “波形” を元に「音程、音色、音量」などを操作します。
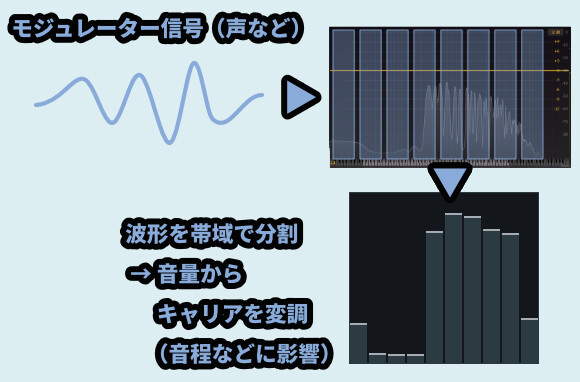
変調 → 音程などを操作する(波形を新たに作る)処理。
私の解釈が正しければ…
FMシンセのFM合成的な事を周波数で分けてやってます。
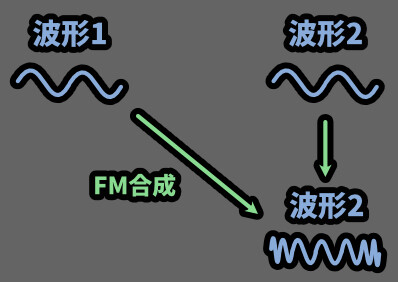
そして、複数の周波数帯に波形が生まれて…
複雑な波形が完成する。
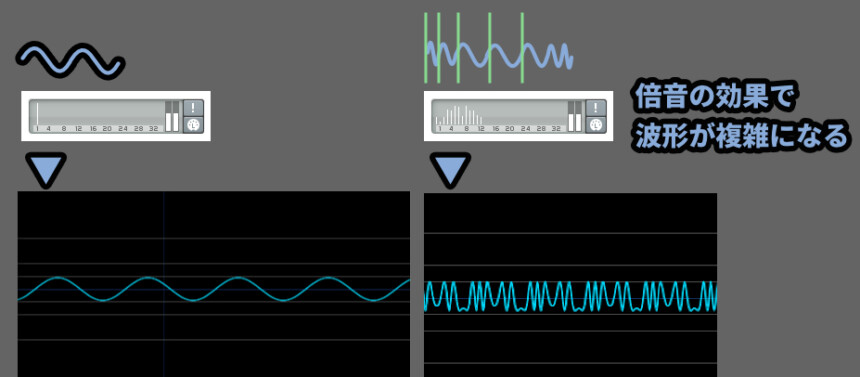
音は倍音の効果で重なるので、波形が複雑になる。
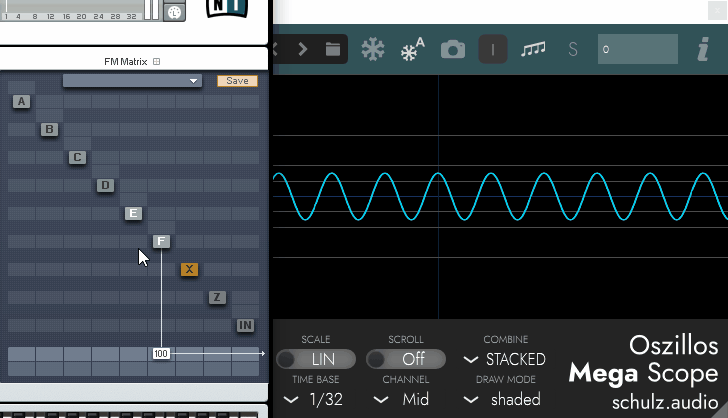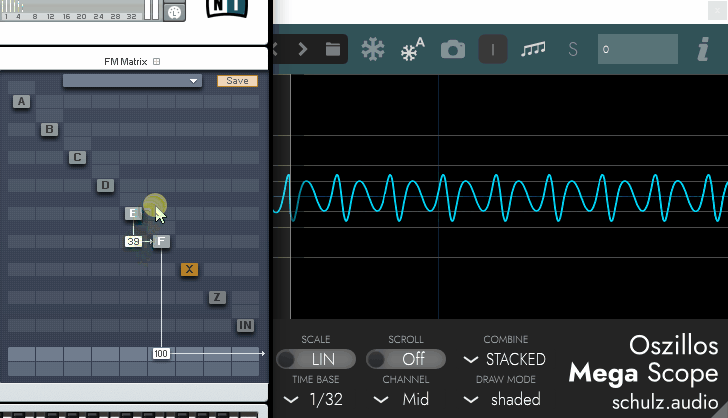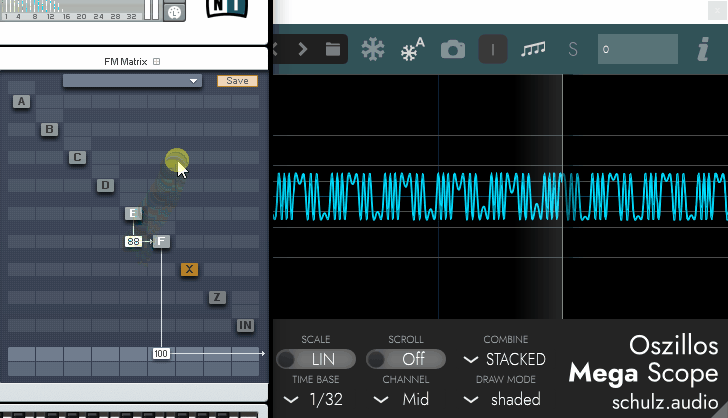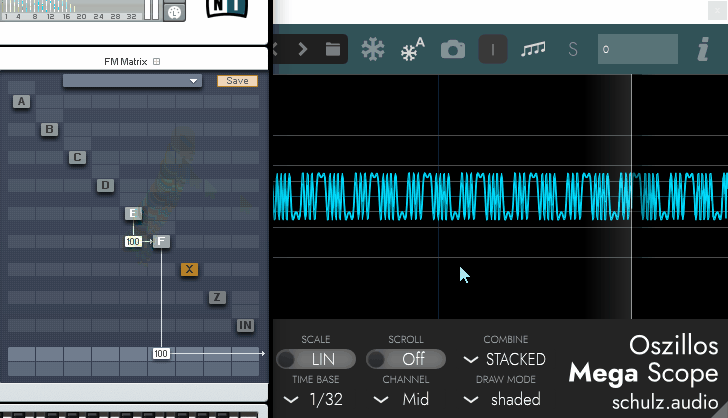
みたいなことを帯域で分けてそれぞれで処理してる恐ろしい子がVocoderだと思います。
帯域で分けて変調したら倍音が増えまくるので…
正直、制御は困難です。(私も使ってて扱いが難しいと思いました)
↓FM合成については、こちらのFM8の記事で解説してます。

あと、私も正直、謎なのですが…
この複雑すぎる処理の影響なのか…
高い音程を入力すると音程が崩れます。
厄介なのが、毎回崩れるのではなく “たまに” 崩れるんですよね…。
たぶん、VocalSynth 2内のキャリア波形に音を入れるタイミングの問題と思います。
→ 高音域では使わない方が無難。
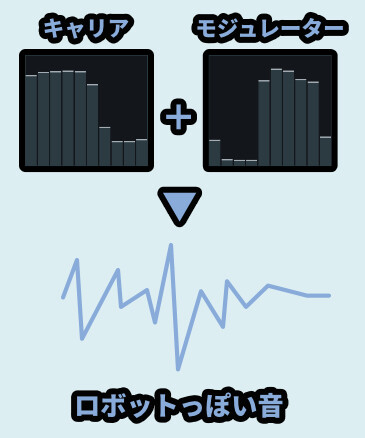
そして、声をモジュレーターに入れて、キャリアで適当な楽器を演奏すると…
ロボットっぽい音になったようです。
そして、処理は難しすぎるので…
「ロボットっぽい声を作るヤツ」みたいな認識になったエフェクトみたいです。
頭で考えるとかなり難しいと思います。
私も正直、よく分かって無いと言いますか…
仕組みを考えてもどうにもならないタイプなので
音作りは “ガチャ” 的な感じでパラメーターを回して音を覚えた方が早いと思います。
このVocoder右下部分を選択して開きます。
すると、詳細設定を表示できます。
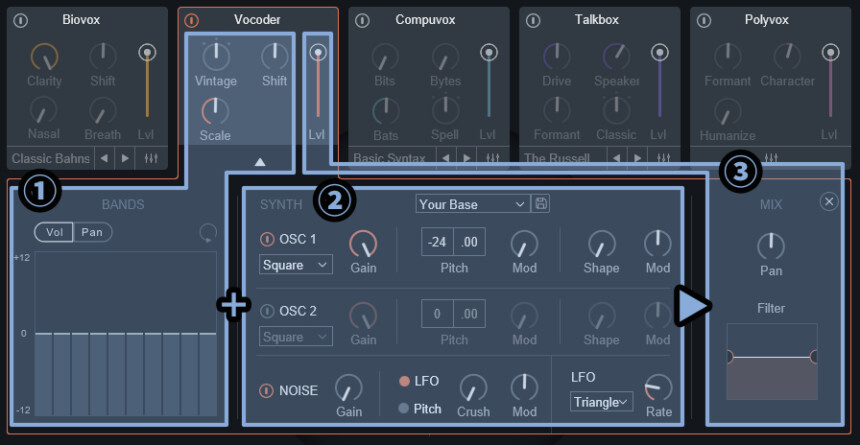
「▲」か「×」を押すと拡張表示を消した状態に戻せます。
そして、大まかな処理を紹介するとこちら。
① → キャリア信号の調整(3つ全体)
② → キャリア信号用の波形生成(2osc+Noise)
➂ → アウトプット関係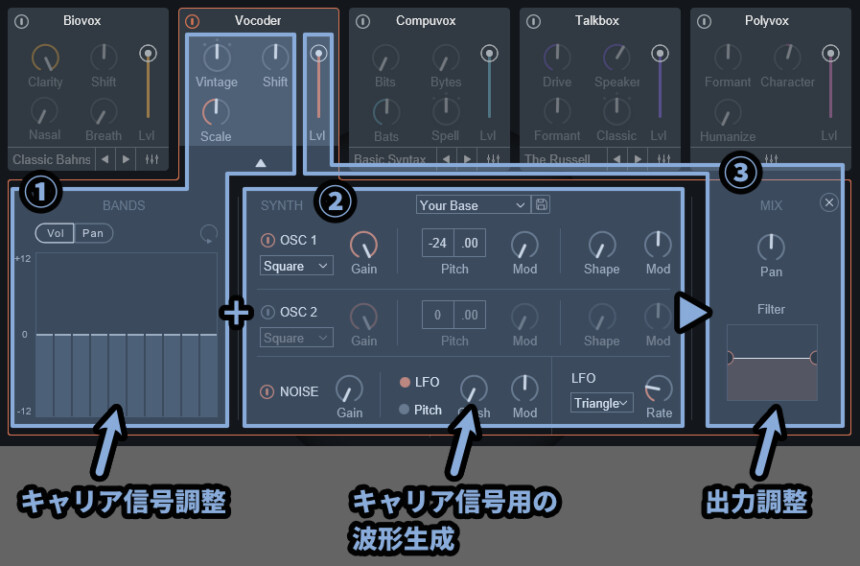
そしたら、最も簡単な出力の「➂」だけ先に解説します。
➂の全体の出力調整で使える項目は下記。
・Lvl → Biovox全体の音量
・Pan → 音を左右に動かす(L/R)
・Filter → 低音/高音をカットするフィルター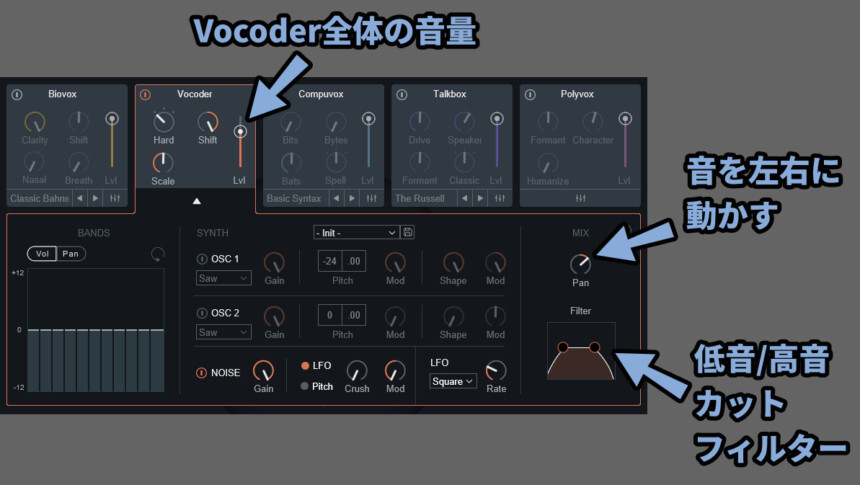
あと、Sidechain Modeで波形を入力した場合…
その入力した波形が “キャリア” になります。
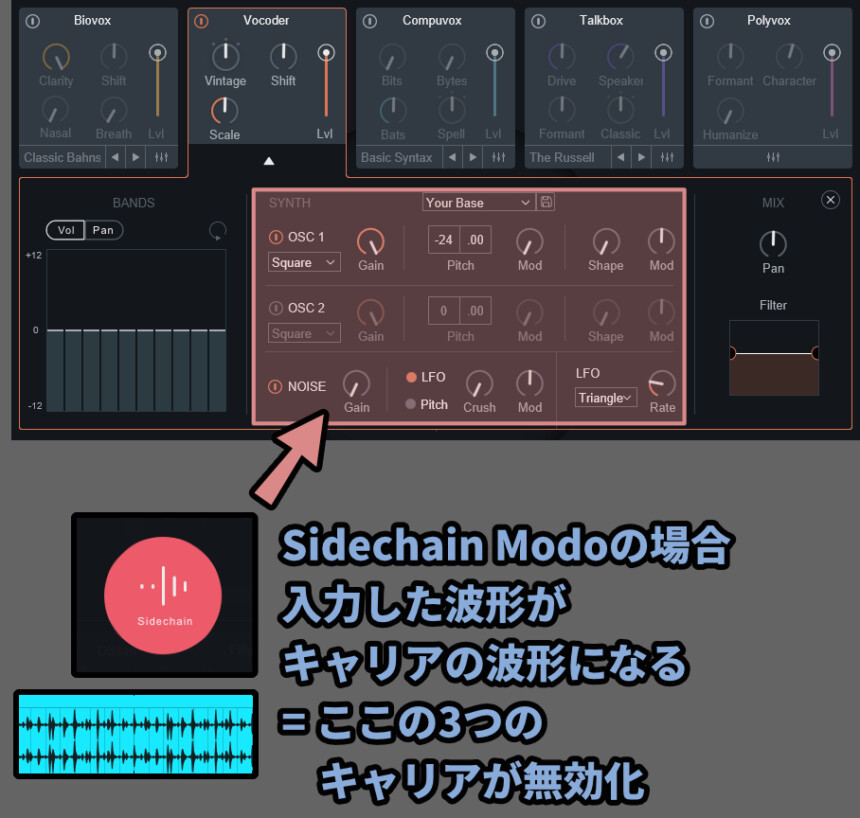
つまり、Vocoder画面で触れるのは “キャリア信号” だけです。
= 声道の部分では無いので、本質的な音変化はあまり起きません。
本質的な音の変化、モジュレーター信号を調整したい場合は…
エフェクトを入れた元の音源を操作してください。
Vocoderの①と②は “キャリアの調整” だけなので…
あまり、本質的な変化が起きません。
凄い大雑把に言うと…
このVocoderの設定項目は全て “音色調整” だと思っても大丈夫です。
操作すると、音的にはこんな感じになります。
この特徴を理解した上で、次以降の操作項目を見てください。
キャリア系の音色調整
キャリアの音色調整の要素は下記。
・Hard / Vintage / Smooth → 信号を分ける帯域の分割数による音色調整
・Shift → 音の明瞭度、明るさ的な変化(2つの信号の混ざり具合)
・Scale → 母音に対して変化を付ける(Shift的な操作)
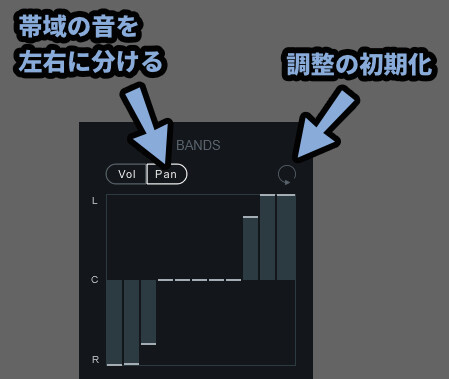
・BANDS → キャリア/モジュレーターを分けた分割プレビュー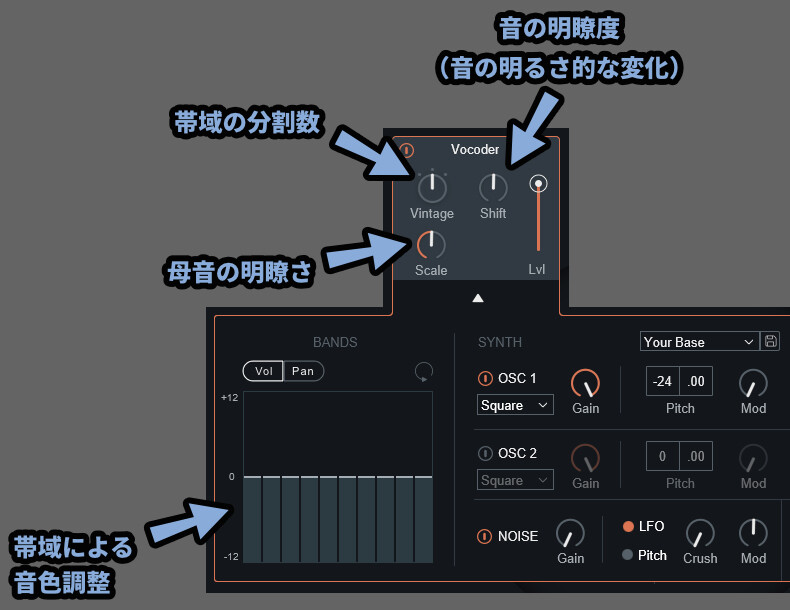
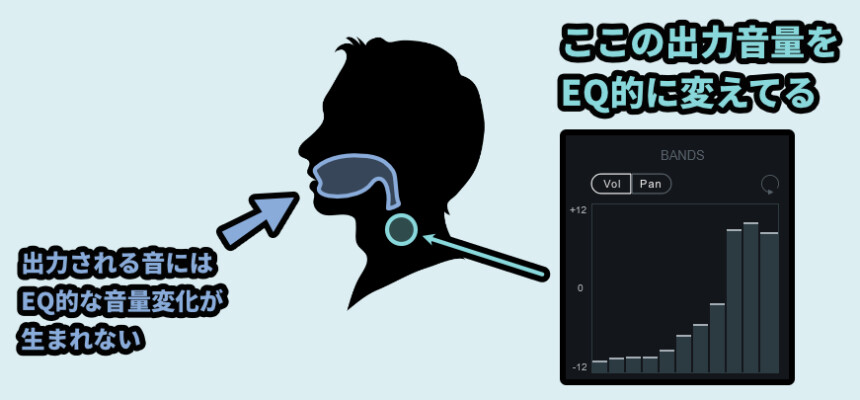
そして、BANDSは操作できます。
操作するとEQ的な感じで “キャリアの” 音に変化が生まれます。
→ 出力される音にEQ的な処理は入って無いので注意。
試しにBANDSを極端な形にして同じ音を鳴らしてみます。
すると、音色に変化は生じ、全体的な音程も少し変わりますが…
全体的に “決定的な” 変化が入って無い感じになります。
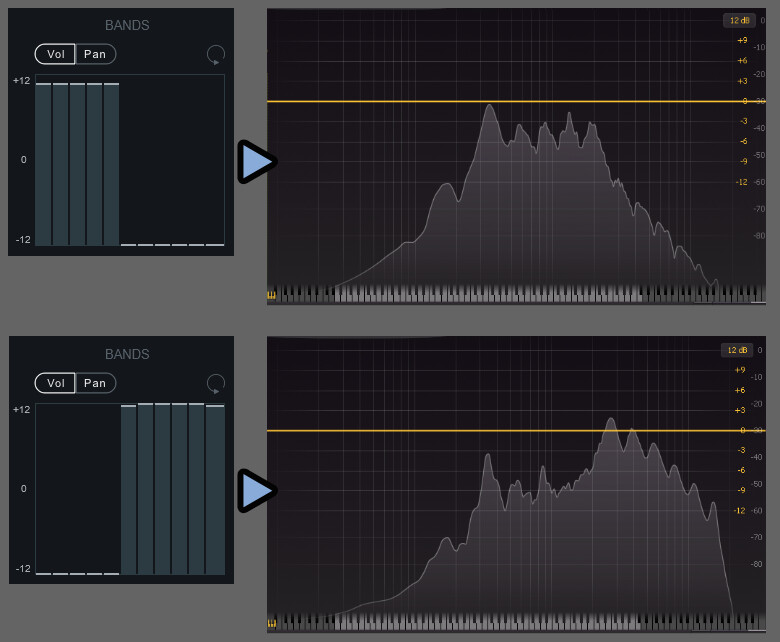
キャリアの信号はあくまで帯域ごとに分割された場所の “波形”(音の特徴)が参照されるだけなようで…
音程みたいな音の主要な聞こえ方に関する要素を決定する効果は弱めです。
あとBANDSはPanにすると、キャリアの音をL/Rに分けれます。
これを使えば低音や高音でどのような音が鳴ってるか少しわかりやすくなります。
以上が、キャリア系の音色調整です。
3つのキャリア波形生成機について
次は「②」の3つのキャリア波形生成機について見ていきます。
SYNTHの所です。
まず、左側部分は下記の通り。
・OSC1/2 → 出力のオン/オフ
・OSC下にある波形名 → 入力した音を元に、特定の波形に変換して出力(音色調整)
・Noise → ノイズ出力のオン/オフ
・Gain → 音量SYNTHは最大3つの波形を新たに作り出せます。
(OSC1/2 + Noise)

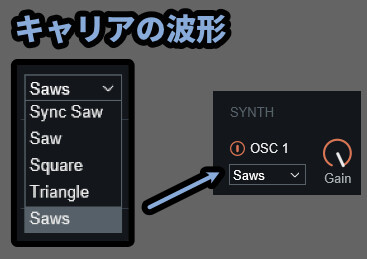
そして、キャリアの波形はクリックで5つのパターンから選べます。
OSC1/2の右側の項目は下記。
・Pitch左 → "キャリア"の半音単位で音程を操作(±24が上限(2オクターブ))
・Pitch右 → "キャリア"の半音以下の音程を操作(±50が上限)
・Pitch内のMod → PitchにLFOによる変化を与える度合い
・Shape → "キャリア"の音色調整(波形を操作)
・Shape右のMod → ShapeにLFOによる変化を与える度合い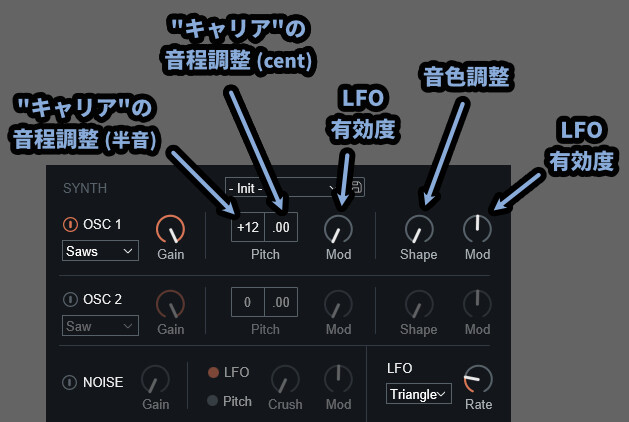
重要なのはPitchはキャリアの調整をしてる事です。
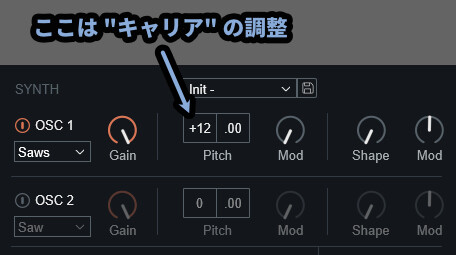
キャリアはあくまで “声帯” の部分であり…
音を形作る “声道” の部分ではありません。
なので「音程+0 & キャリアPitch+12」と「音程+12 & キャリアPitch+0」は別の音になります。
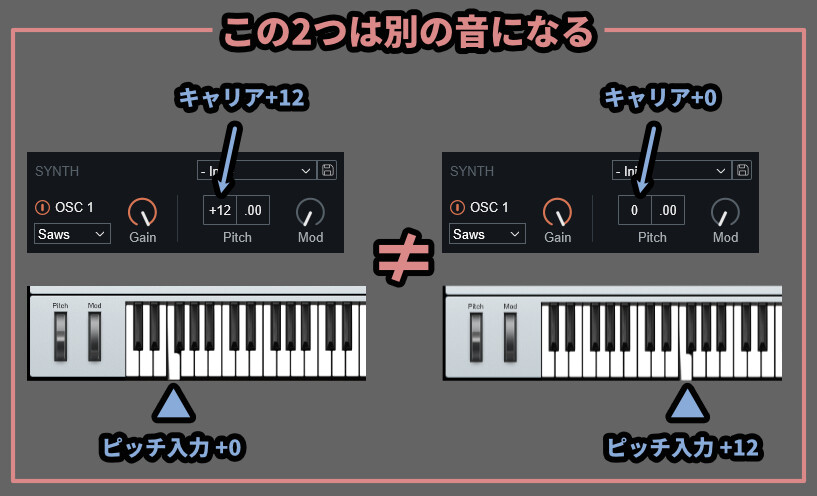
音的にはこんな感じです。
VocoderのPitchは結構、音に対して大きな影響を与えます。
VocoderのShapeを下げると、色んな音が混ざった感じの音になります。
Shapeを上げると一部の音以外が消えて、クリアではっきりした感じになります。
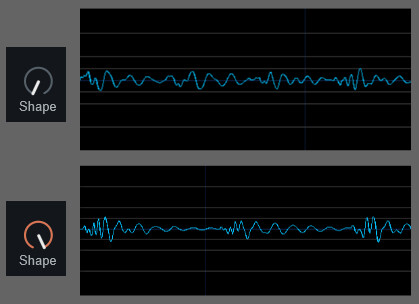
上げると波形の音量差が上がる
=小さな音が消えてる…? という感じの音になります。
ちょっとNoise Gateっぽい動きです。
そして、Modは右下のLFOの割り当て量です。
LFOは5波形から選べ、右側のRateで速さを調整できます。
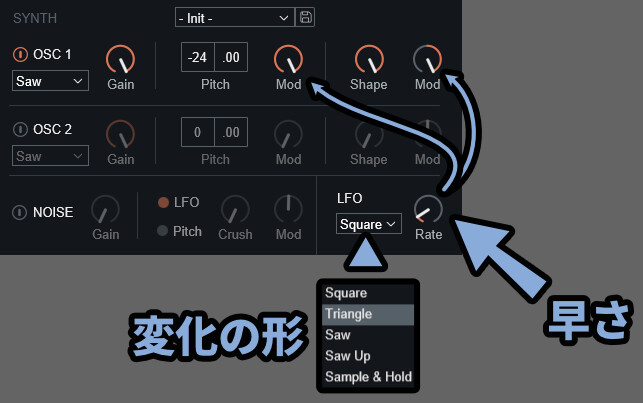
Sample&Holdはランダムで離散的な変化を作るモノと考えてください。
要するに「突然、適当な場所に」変わります。
そしたら、次は「Noise」です。
設定要素は下記。
・左側のボタン → Noiseのオン/オフ
・Gain → Noiseの音量
・LFO/Pitch → 変化のかけ方
・Crush → 音色調整(ホワイトノイズなど)
・Mod → LFO変化の影響度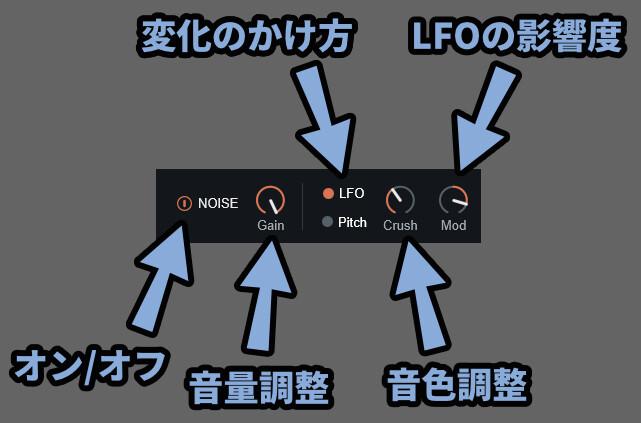
変化のかけ方がLFOの場合、右側のLFOの影響を受けてノイズ波形に変化が生まれます。
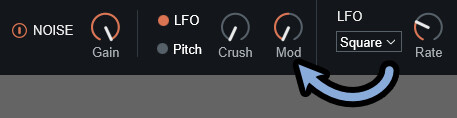
この、Modの値はマイナス値に設定できます。
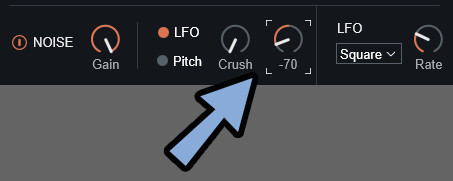
注意点は、変化量は「Crush」と「Mod」の2つの和によって決まることです。
つまり、足し算。
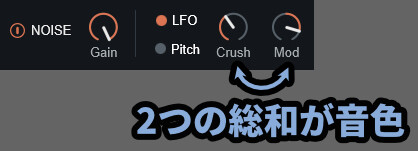
なので「Crush=0 / Mod=+100」と「Crush=100 / Mod=-100」はほぼ同じ波形になります。

あと変化のかけ方をPitchにすると…
入力した音程によって変化量が変わります。
以上が、Vocoderについての解説です。
Compuvox
Compuvoxは、線形予測符号化をベースにした音加工ができます。
まず、線形予測と線形予測符号化(LPC)の解説から始めます。
線形予測は過去の波形情報から次の波形を予測する処理。
別の言い方をするなら、既に鳴った音から次の音を予測する処理です。
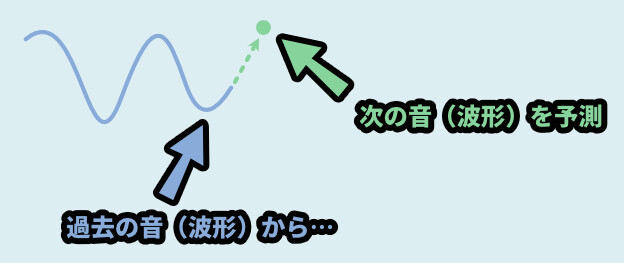
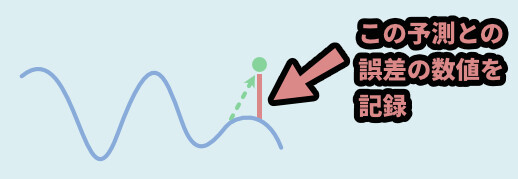
そして、線形予測符号化は線形予測を使用したデータの記録方法です。
この予測結果を元に “予測との差の値” を記録する処理になります。
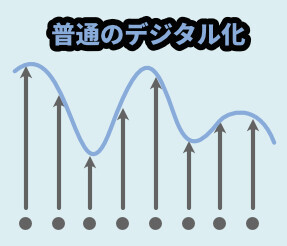
ちなみに「普通の符号化,デジタル化」と「線形予測符号」は別物になります。
違いは下記。
◆普通の符号化、デジタル化
→ アナログ信号をPCで扱えるようにすること
→ 一定間隔でデータを取り、その情報を記録する(サンプリング)
→ いろんなところで幅広く使われる
◆線形予測符号化(LPC)
→ 音声信号に特化した符号化
→ 線形予測符号化を行うデータは既に普通の符号化(サンプリング)がされてる
→ つまり入力した音はデジタル化されてる
→ その上で、過去の情報を参照して、次の変化量を予測+その誤差量を記録
→ その予測+誤差量を記録すると、データを効率的に圧縮できる
→ ただし、線形予測の処理が入るので処理の負荷は上がる普通のデジタル化は波形を一定間隔で切り、データを取ります。
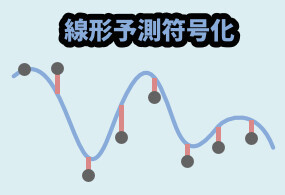
それに対して、線形予測符号化は…
デジタル化した波形を受け取り、常に前の音から次の音を予測する処理を実行。
そして、その “予測値との誤差値” を記録してデータを保存する処理になります。
なので、線形予測という処理の負荷が増えます。
が、データの総量、ファイルサイズ的には軽くなります。
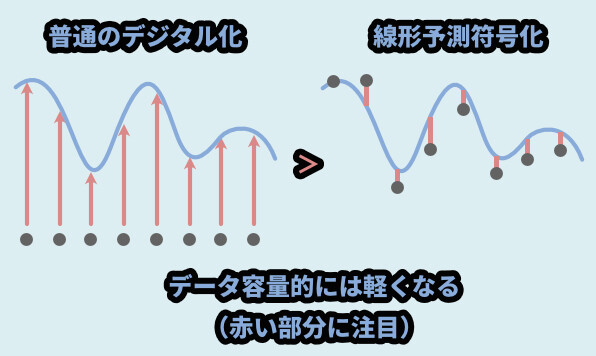
この “容量が軽くなる” という特徴から音声圧縮に使われたりします。
MP3形式などの圧縮は、この線形予測符号化が元ネタです。
(圧縮は人間の聞こえ方の特徴を考慮した、適応線形符号化が使われてます)
そして、Compuvoxは線形予測符号化を元に “声用の処理” を入れてます。
↓すべての処理をまとめて書くと下記。
【Compuvoxの処理】
・音声信号を2要素に分解
・2つの要素は「フォルマント」と「それ以外の音」
・フォルマント → 声の特徴的な部分
・それ以外 → 雑音や声帯の鳴りなどの要素
・この2つに線形予測処理を入れる
・さらに2つの要素に分けてエフェクトの処理を入れる
・そして、2つの波形を合成
・こうして出来上がった音に、SYNTHの波形を使って変化を加える(操作可能)ここ日本語の説明書、ちょっと説明が不足してるといいますか文章が不自然だったので…
この解釈が怪しい可能性があります。
…という大変、意味わかんねーという処理をしてます。
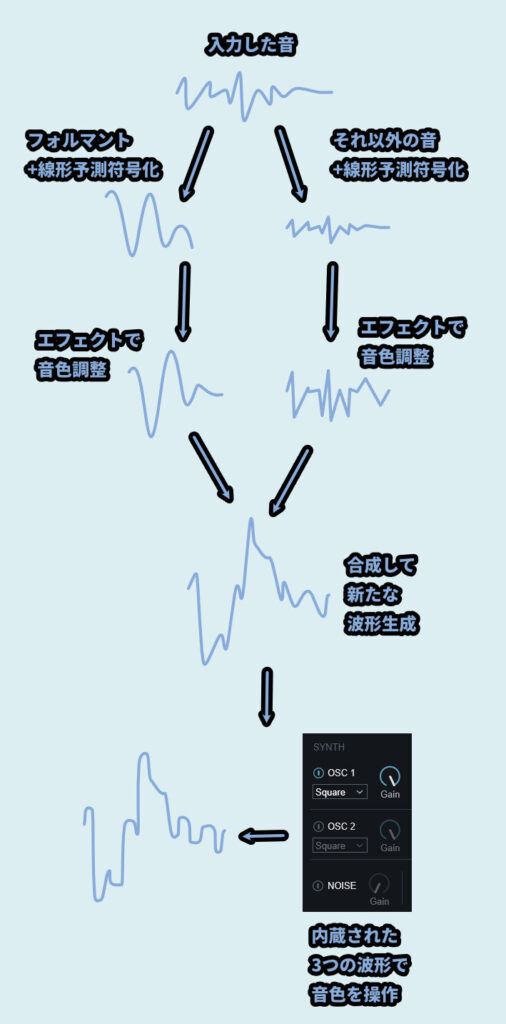
なぜ分けた…? と思うかもしれません。
これは多分「Bytes」などの母音を伸ばす処理などを使う関係で
分ける必要があったと考えられます。
ただ、操作項目としては簡単です。
操作できる場所が下記の3か所だけになります。
・エフェクトによる音色調整
・3つのモジュレーターについて
・全体の出力調整
Vocal Synth2のCompuvox画面で紹介すると、こちらの①,②,➂です。
そしたら、最も簡単な出力の「➂」だけ先に解説します。
➂の全体の出力調整で使える項目は下記。
・Lvl → Biovox全体の音量
・Pan → 音を左右に動かす(L/R)
・Filter → 低音/高音をカットするフィルターそしたら、他の項目を見ていきます。
もう、頭で考えても良く分からないので…
Compuvoxはヘビーメタルっぽい音を作るヤツ、
そして、上部の4つのツマミを回したらガチャ的に音が変わるという認識で良いかもしれません。
4つの音色調整エフェクト
4つの音色調整エフェクトは画面上部にあります。
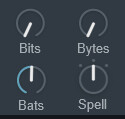
4つのツマミの効果は下記。
・Bits → 高音が目立つノイズを追加(デジタル・エイリアシングノイズ)
・Bytes → 音から母音部分を抽出し、その部分を引き延ばす処理
・Bats →ヘビーメタル的な、獣っぽい音を作る(ノイズとザラザラ感を追加)
・Read / Spell / Math → 音色調整(線形符号予測化のモデル変更)…これに関しては、音を聞いた方が早いと思います。
以上が、4つの音色調整エフェクトです。
3つのモジュレーターについて
次は「②」の3つのモジュレーターについて見ていきます。
※便宜上、FMシンセの名前を借りて「モジュレーター」と読んでますが…
Vocal Synth2の正式名称では無いので注意。
まず、左側部分は下記の通り。
・OSC1/2 → 出力のオン/オフ
・OSC下にある波形名 → 入力した音を元に、特定の波形に変換して出力(音色調整)
・Noise → ノイズ出力のオン/オフ
・Gain → 音量SYNTHは最大3つの波形を新たに作り出せます。
(OSC1/2 + Noise)
そして、SYNTH部分は調整された音を受け取って、この3つの波形で音に変化を加えてます。
FMシンセで言う「モジュレーター」的な事をやってます。
→ つまり「元の波形(加工済み)」と「新たに生成した波形」の2で音を加工してます。
そして、この波形は1つでも入れてないと音が出ません。
つまり、モジュレーター的な働きで音に変化を加えてるというよりは…
入力した音を元に、SYNTHの波形を合成して
新しく音を作り直してる感じの事をやってるようです。
なので、ここの「波形」を変えるだけでも音色が大きく変わります。
OSC1/2の右側の項目は下記。
・Pitch左 → 半音単位で音程を操作(±24が上限(2オクターブ))
・Pitch右 → 半音以下の音程を操作(±50が上限)
・Pitch内のMod → PitchにLFOによる変化を与える度合い
・Shape → 音色調整(波形を操作)
・Shape右のMod → ShapeにLFOによる変化を与える度合い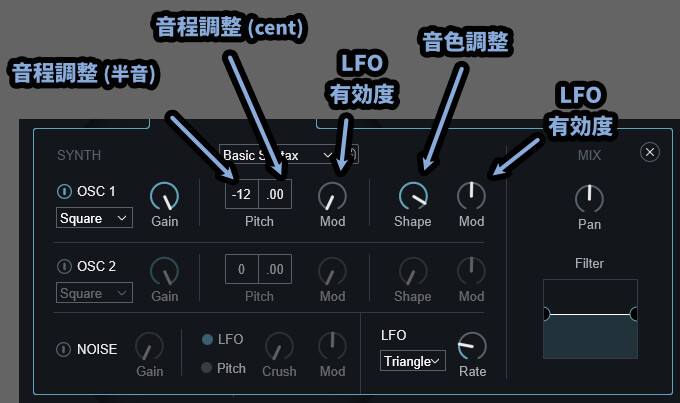
CompuvoxのShapeは、正直よくわかりません。
音色が変わりますとしか言えないです。
↓こちらは「Saw」波形のOSCで調整した様子
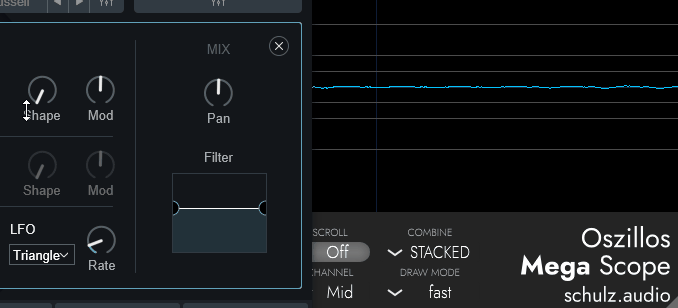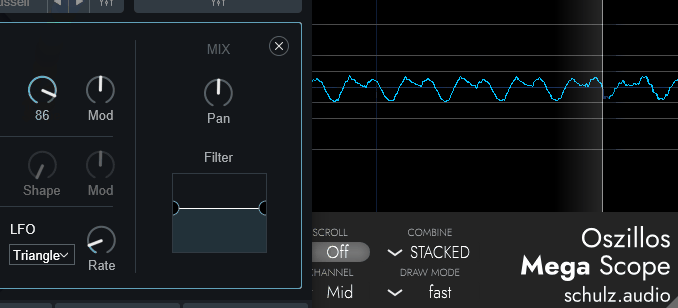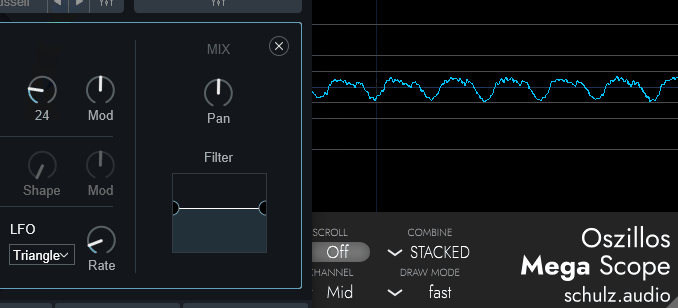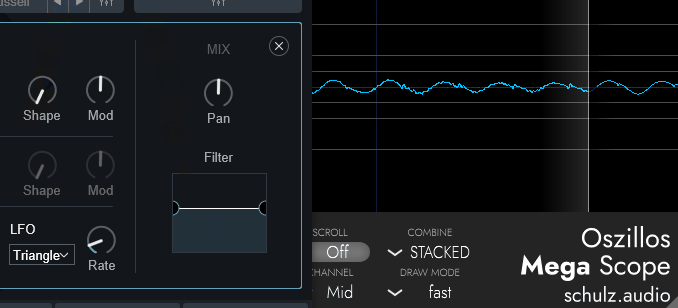
↓こちらは「Square」波形のOSCで調整した様子
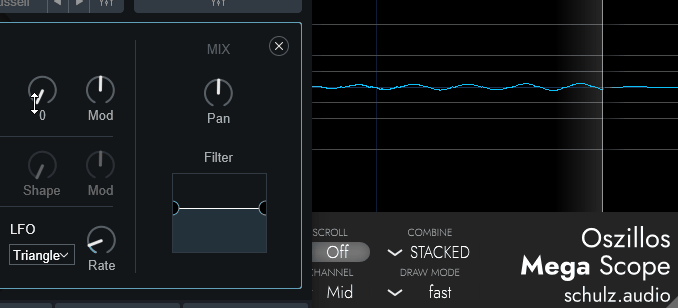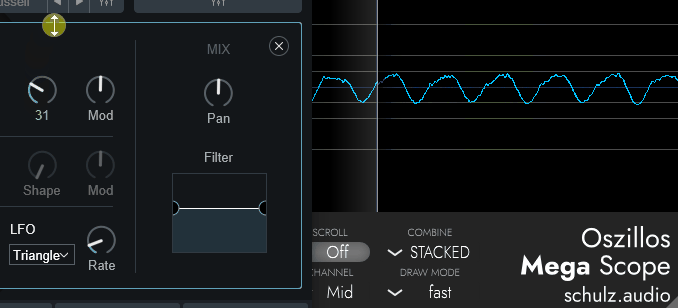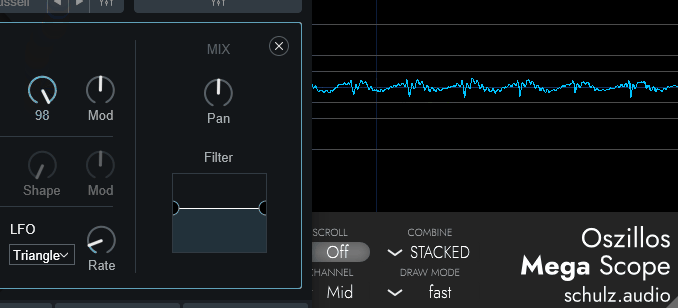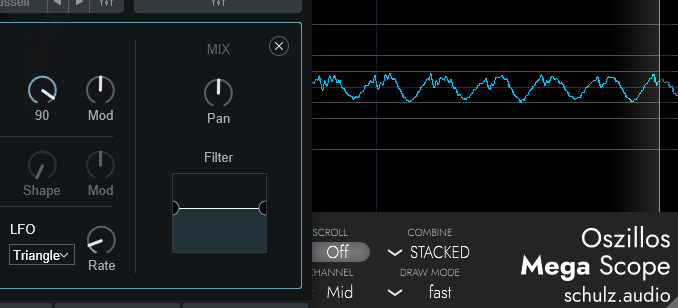
規則性はありそうな感じですが…
どんな規則で動いてるかは、謎です。
倍音が… 増えてる…?
右側のModはLFOの有効度です。
そしてLFOは右下の所で設定できます。
・LFO → 特定の波形を元にして音に変化を加える処理
・波形 → LFO左側の項目で操作
・Rate → LFO変化の速さ(波形の幅)だいたいは、他のシンセと同じなので分かると思います。
※分からなくても、触れば変化が分かります。
Sample&Holdはランダムで離散的な変化を作るモノと考えてください。
要するに「突然、適当な場所に」変わります。
そしたら、次は「Noise」です。
設定要素は下記。
・左側のボタン → Noiseのオン/オフ
・Gain → Noiseの音量
・LFO/Pitch → 変化のかけ方
・Crush → 音色調整(ホワイトノイズなど)
・Mod → LFO変化の影響度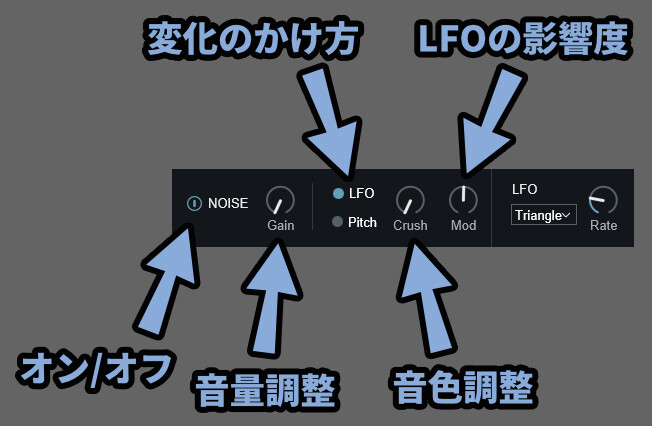
変化のかけ方がLFOの場合、右側のLFOの影響を受けてノイズ波形に変化が生まれます。
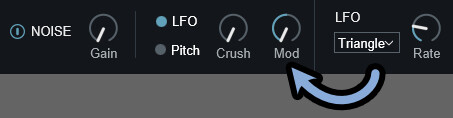
この、Modの値はマイナス値に設定できます。
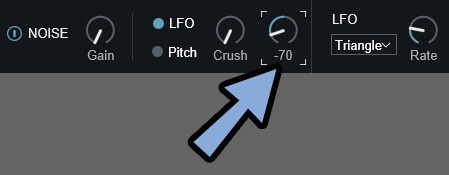
注意点は、変化量は「Crush」と「Mod」の2つの和によって決まることです。
つまり、足し算。
なので「Crush=0 / Mod=+100」と「Crush=100 / Mod=-100」はほぼ同じ波形になります。

あと変化のかけ方をPitchにすると…
入力した音程によって変化量が変わります。

以上が、Compuvoxについての解説です。
Talkbox
Talkboxは「トークボックス」というエフェクターを再現したモノです。
トークボックスは、ホースを咥えながら楽器を鳴らして歌うヤツです。
楽器の信号をホース経由で口に送り、口の中で共振させた音を変化させます。
始めて見た時は「…嘘やろ」と思いまいした。
しかし、本当にホースを加えながら歌ってます。
この一見ふざけてるような見た目反して…
「信じられないようなおしゃれな音」が出ます。
…そうはならんやろ
→ 「なっとるやろがい」
何が起こってるか、整理すると下記。
【トークボックス】
① 適当な楽器から音を鳴らす
② 鳴らした音にエフェクトを加えてホースに出力
(トークボックスエフェクター)
➂ ホースを咥えて、口の中に音を送る
④ 自分の口を動かして、音に変化を加える
➄ マイクなどで音を拾って使うちなみに、口の中に音が直接流れてくるため…
健康的な問題は無いとされてますが、頭痛や吐き気などが起こることがあるそうです。
なんでこんな原始的な方法で、こんなおしゃれな音が出るんだ…。
これを、再現したモノがVocal Synth2のTalkboxになります。
立ち位置的には “再現したモノ” なので、それっぽくなるだけです。
→ Talk Boxの再現度的には低めになります。
Vocal Synth2のCompuvox画面で紹介すると、こちらの①,②,➂です。
そしたら、最も簡単な出力の「➂」だけ先に解説します。
➂の全体の出力調整で使える項目は下記。
・Lvl → Biovox全体の音量
・Pan → 音を左右に動かす(L/R)
・Filter → 低音/高音をカットするフィルターそしたら、他の項目を見ていきます。
4つの音色調整エフェクト
4つの音色調整エフェクトは画面上部にあります。
4つのツマミの効果は下記。
・Drive → 音の歪みを追加 / 明瞭度調整(入力Gain値)
・Speaker → 音色調整(トークボックスのコンプレッション・ドライバー再現)
・Formant → 声部分を抽出し "声" の音色を調整する
・Dark / Classic / Bright → 音色調整(音を暗く / 明るくする)Driveは適度に上げると、ボーカルに倍音が増えて聞き取りやすくなるようです。
…これに関しては、音を聞いた方が早いと思います。
以上が、4つの音色調整エフェクトです。
3つのモジュレーターについて
次は「②」の3つのモジュレーターについて見ていきます。
※便宜上、FMシンセの名前を借りて「モジュレーター」と読んでますが…
Vocal Synth2の正式名称では無いので注意。
まず、左側部分は下記の通り。
・OSC1/2 → 出力のオン/オフ
・OSC下にある波形名 → 入力した音を元に、特定の波形に変換して出力(音色調整)
・Noise → ノイズ出力のオン/オフ
・Gain → 音量SYNTHは最大3つの波形を新たに作り出せます。(OSC1/2 + Noise)
そして、SYNTH部分は調整された音を受け取って、この3つの波形で音に変化を加えてます。
FMシンセで言う「モジュレーター」的な事をやってます。
→ つまり「元の波形(加工済み)」と「新たに生成した波形」の2で音を加工してます。
そして、この波形は1つでも入れてないと音が出ません。
つまり、モジュレーター的な働きで音に変化を加えてるというよりは…
入力した音を元に、SYNTHの波形を合成して
新しく音を作り直してる感じの事をやってるようです。
なので、ここの「波形」を変えるだけでも音色が大きく変わります。
OSC1/2の右側の項目は下記。
・Pitch左 → 半音単位で音程を操作(±24が上限(2オクターブ))
・Pitch右 → 半音以下の音程を操作(±50が上限)
・Pitch内のMod → PitchにLFOによる変化を与える度合い
・Shape → 音色調整(波形を操作)
・Shape右のMod → ShapeにLFOによる変化を与える度合い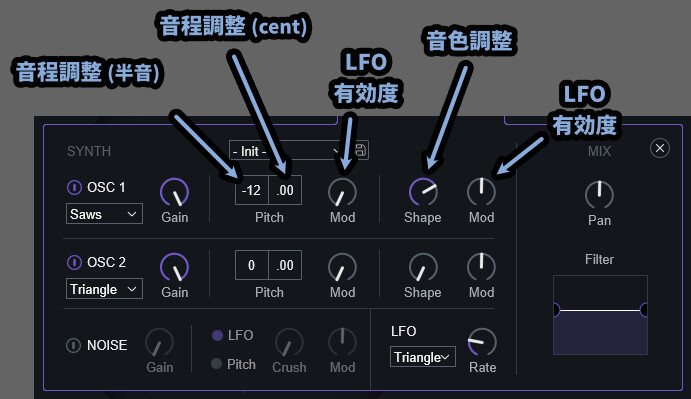
で、TalkBoxのShapeも… 正直よくわかりません。
音色が変わりますとしか言えないです。
規則性はありそうな感じですが、
どんな規則で動いてるかは、謎です。
右側のModはLFOの有効度です。
そしてLFOは右下の所で設定できます。
・LFO → 特定の波形を元にして音に変化を加える処理
・波形 → LFO左側の項目で操作
・Rate → LFO変化の速さ(波形の幅)だいたいは、他のシンセと同じなので分かると思います。
※分からなくても、触れば変化が分かります。
Sample&Holdはランダムで離散的な変化を作るモノと考えてください。
要するに「突然、適当な場所に」変わります。
そしたら、次は「Noise」です。
設定要素は下記。
・左側のボタン → Noiseのオン/オフ
・Gain → Noiseの音量
・LFO/Pitch → 変化のかけ方
・Crush → 音色調整(ホワイトノイズなど)
・Mod → LFO変化の影響度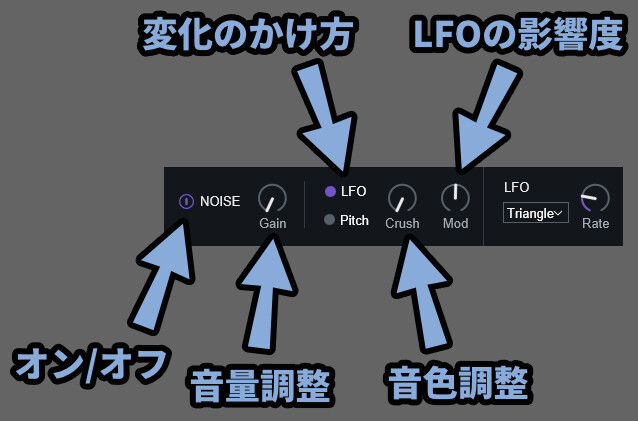
変化のかけ方がLFOの場合、右側のLFOの影響を受けてノイズ波形に変化が生まれます。
この、Modの値はマイナス値に設定できます。
注意点は、変化量は「Crush」と「Mod」の2つの和によって決まることです。
つまり、足し算。
なので「Crush=0 / Mod=+100」と「Crush=100 / Mod=-100」はほぼ同じ波形になります。

あと変化のかけ方をPitchにすると…
入力した音程によって変化量が変わります。
以上が、TalkBoxについての解説です。
Polyvox
Polyvoxは自動でハーモニーを生成する装置です。
・ハーモニー = 音程が違う音を重ねる(ハモリと呼ばれる事もある)
・ユニゾン = 同じ音程の音を重ねる(コーラスと呼ばれる事もある)コーラスは本来の意味では “合唱” で、メインの声を目立たせるための音ですが…
(ハーモニー + ユニゾンの音。ハモリと呼ばれる事もある)
エフェクト界隈では、ユニゾン的の処理を指す言葉になってるようです。
(同じ音程をわずかにズラして重ねる処理)
そして、Polyvoxは “音全体”の「音程」を直接操作できないようです。
フォルマントを操作することで “フォルマント(声的な特徴)” 部分の音程だけを操作します。
【Polyvoxの概要】
・入力した音を元にハーモニーを作る
・主な操作項目は「フォルマント」だけ
・あとはフォルマント操作によっておこった問題を解決するためのパラメーターこれを使うと元の音がほぼ聞こえなくなるので…
ハーモニーを作る装置というよりは、
ボイスチェンジャーを使ってる感覚の方が近いかもしれません。
そしてVocalSynth2で設定できる項目が、かなり少ないのも特徴です。
↓設定項目はこれだけ。
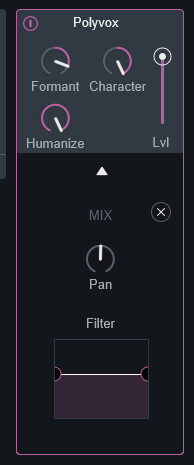
これまでと違い、3つのモジュレーターや音の外部入力機能はないようです。
なので「音色調整」と「出力調整」の2つだけになります。
機能が少ないので、まとめて紹介します。
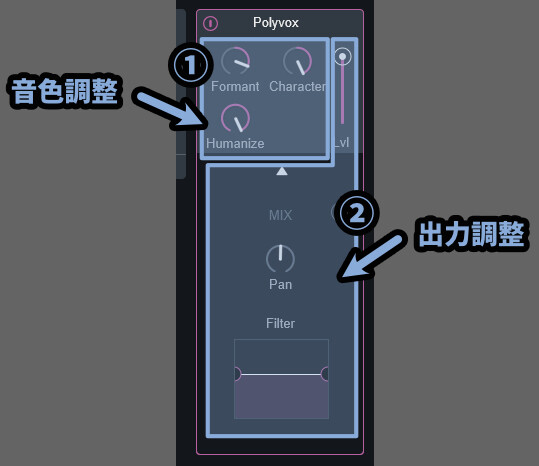
【音色調整系】
・Formant → フォルマント全体を動かす(分かりやすい、主要な音色調整)
・Charactaer → フォルマントを入力した音に近づける(分かりにくい)
・Humanaize → 位相をズラす処理を元にした音色調整
【出力調整系】
・Lvl → 出力音量調整
・Pan → 音を左右に動かす(L/R)
・Filter → ロー/ハイカットフィルター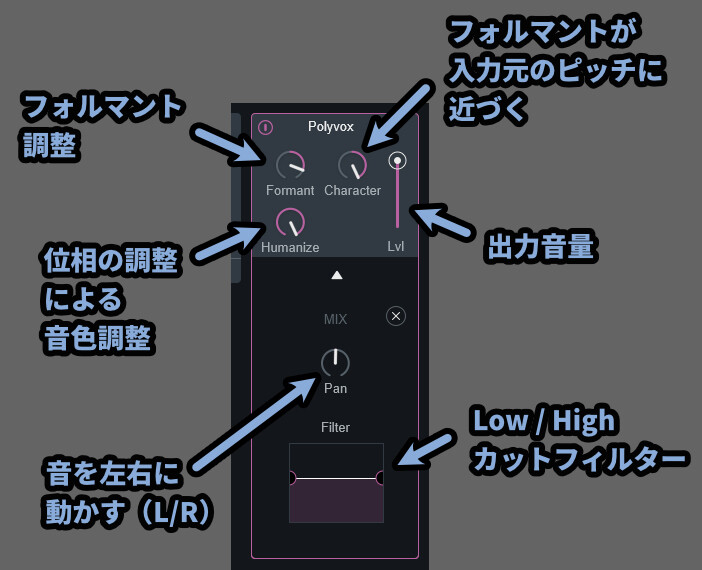
Polyvoxは「Formant」がメイン部分。
なので、とりあえず触るならFormant。
これを覚えておけば、何とかなると思います。
↓動かすとこんな感じになります。
Formantは音全体のフォルマントを動かしてるようです。
これの変化が一番わかりやすい。

というより、Polyvoxは「Formant」を触るだけみたいな所があります。
Characterは入力した音から音程を取る。
さらに、入力した音からフォルマントも取得。
そしてフォルマントを音程に近づける操作のようです。
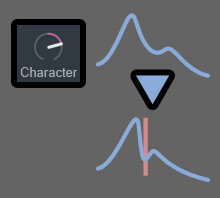
Characterは触っても違いがかなり分かりにくいです。
音源による所もありますが…。
ボーカル系で、ちょっといまいちだと思った際に
触るモノだと思ってください。
Humanizeは位相シフトのようです。
ハーモニーの波形をズラします。
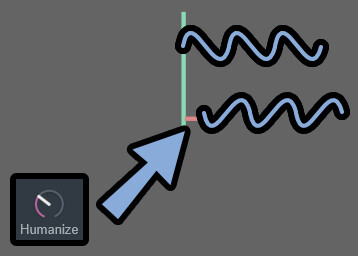
これは、本来は位相(ハーモニーの波形)を反転して衝突して音が消えるなど
特殊な事象が起こった際に使います。
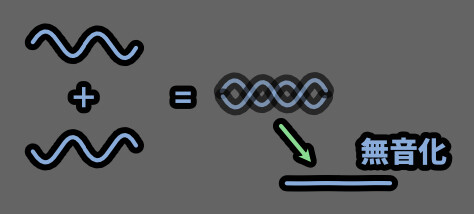
波形は足し算です。
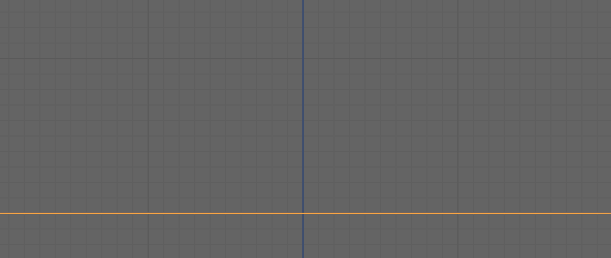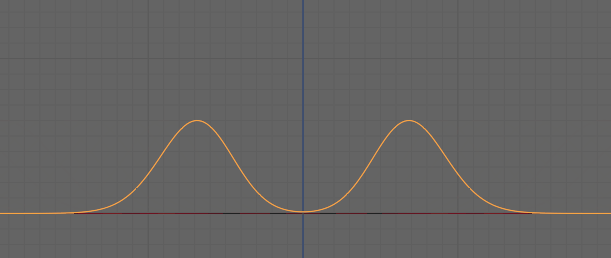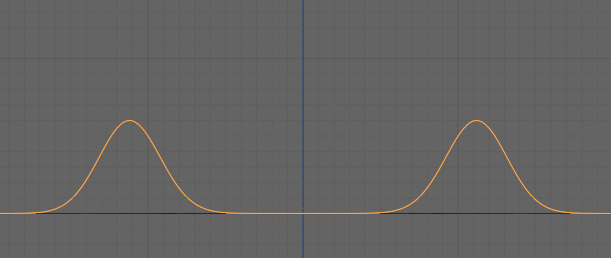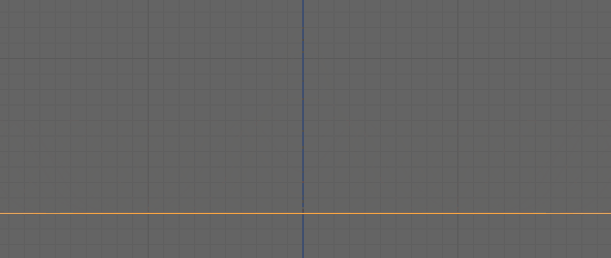
なので、同じ波形を重ねると波が大きくなり音量が上がります。
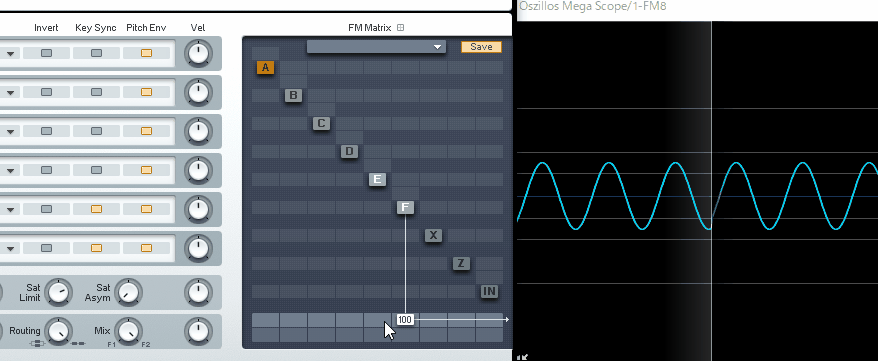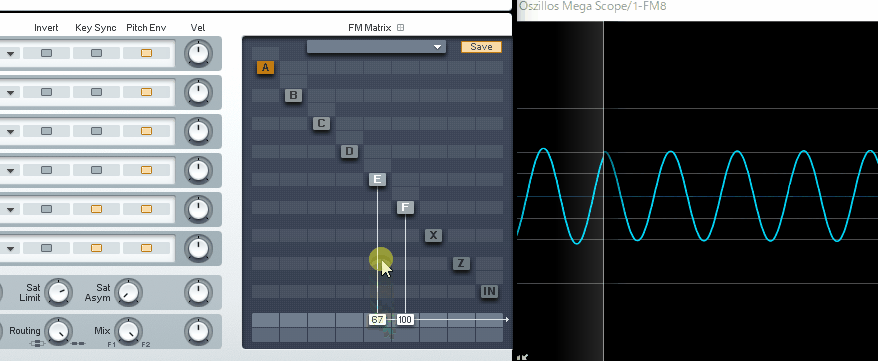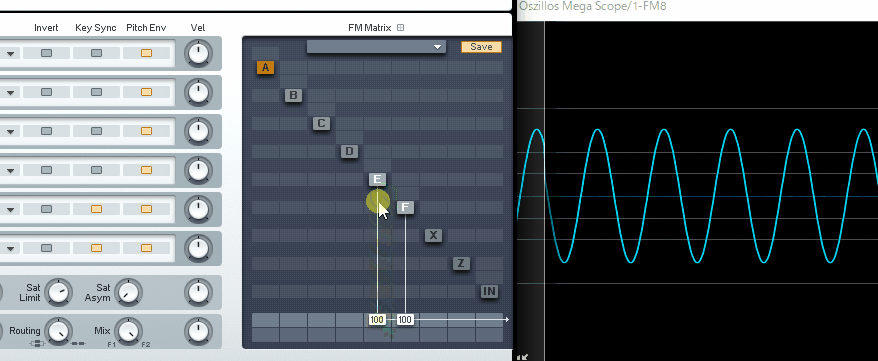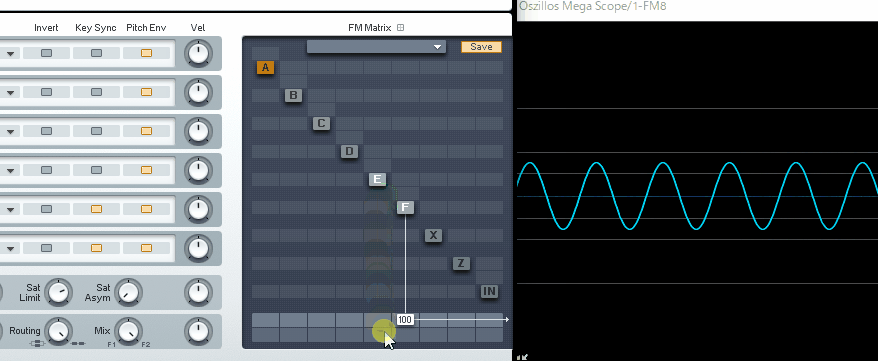
そして反転した同じ波形を当てると、音が消えます。
(↓この現象を、フェイズ・キャンセレー ションと呼びます)
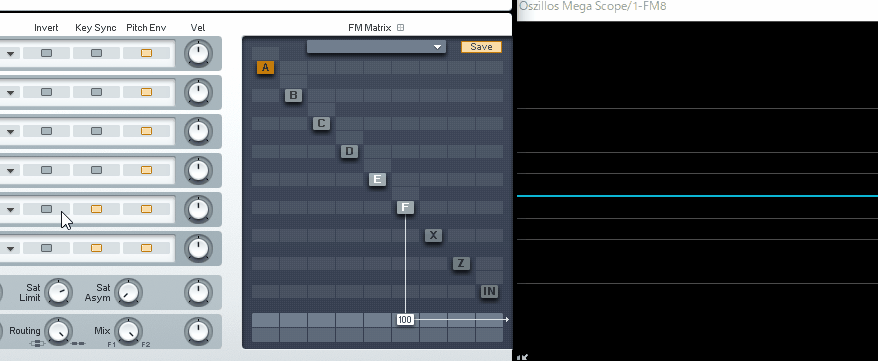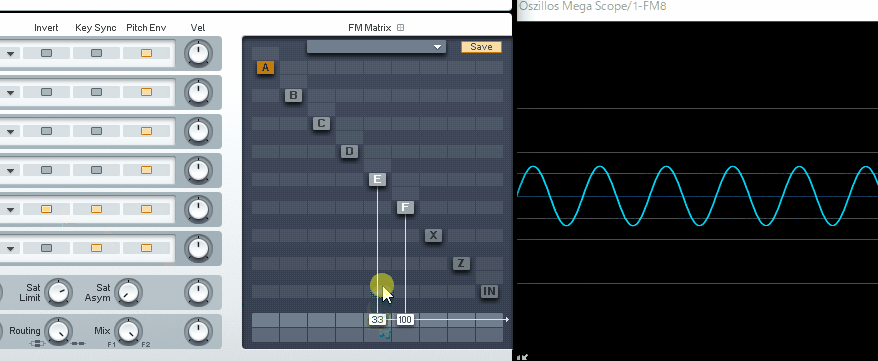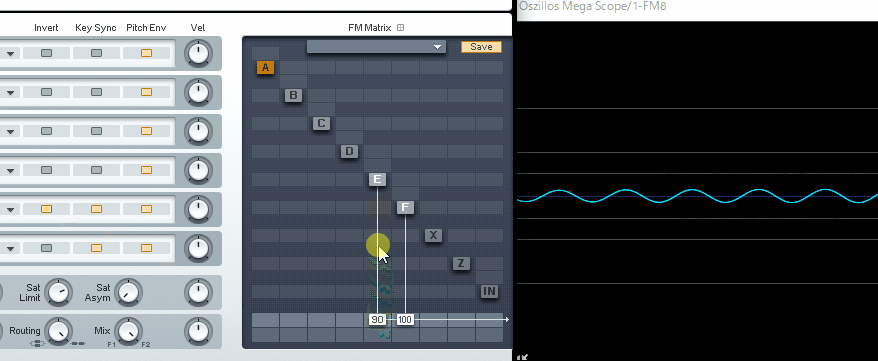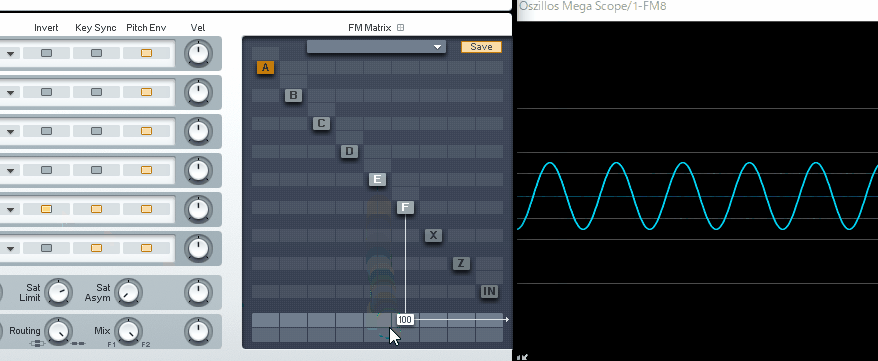
本来は、これを回避するために使われる機能ですが…。
Vocal Synth2のPolyvoxには波形を反転する機能がないようです。
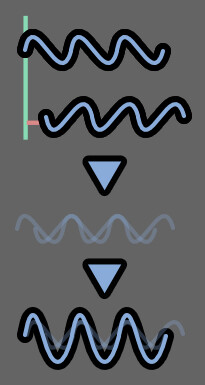
なので、位相シフトを使って…
音の重なり感を調整して音色を整えるモノになります。
公式的には「リアル感を加える」や「パワフルなデチューン効果」を出すモノ書かれてれてました。
特に「ユニゾン(同じ音程を重ねる)」が入った音を使うと効果が出るようです。
Vocal Synth2の中にあるエフェクトだと「Chorus」が一番ユニゾンに近いかなと思います。
以上が、Polyvoxについての解説です。
7つの標準エフェクトについて(下部)
Vocal Synth2の株には7つの標準的なエフェクトが搭載されてます。
これは、このプラグイン以外でも多くの場面で目にするモノです。
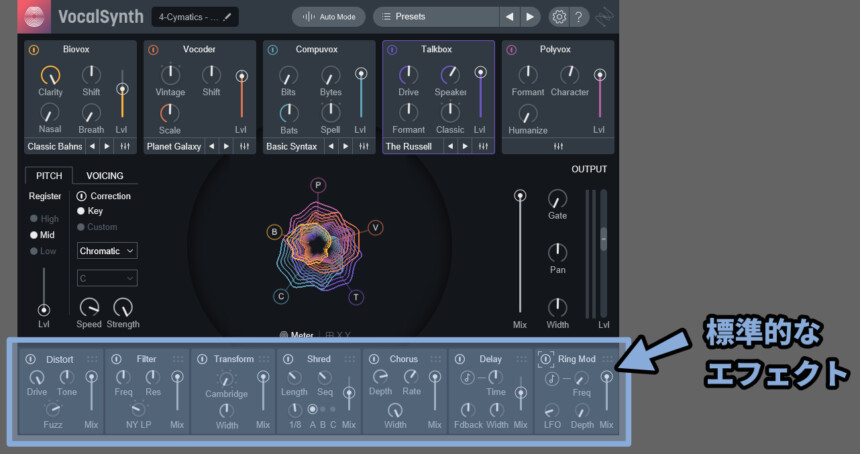
注意点は、この7つのエフェクトは単体でONにしても音が鳴らない事です。
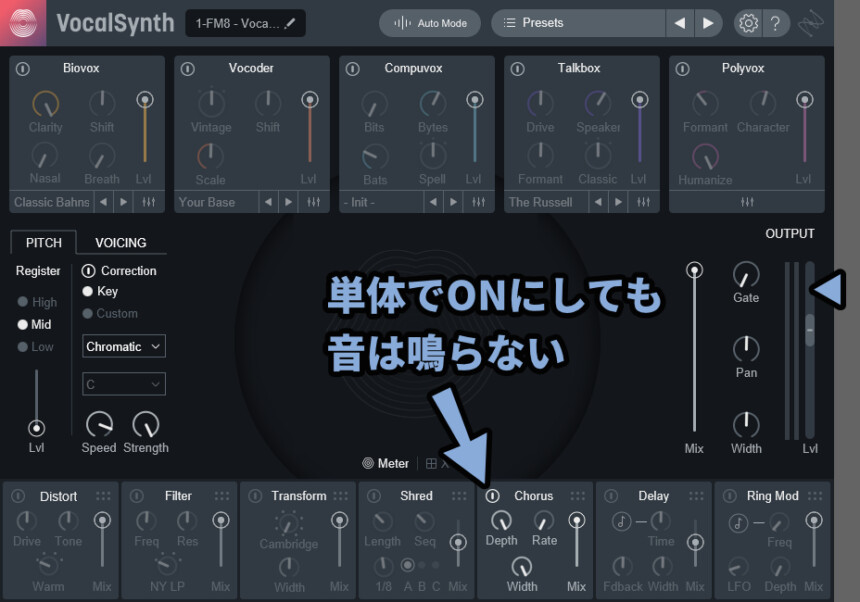
7つのエフェクトを通した音を聞くには「上部の固有エフェクト」か「ピッチ補正への入力音量」のいずれかが聞こえる状態にする必要があります。
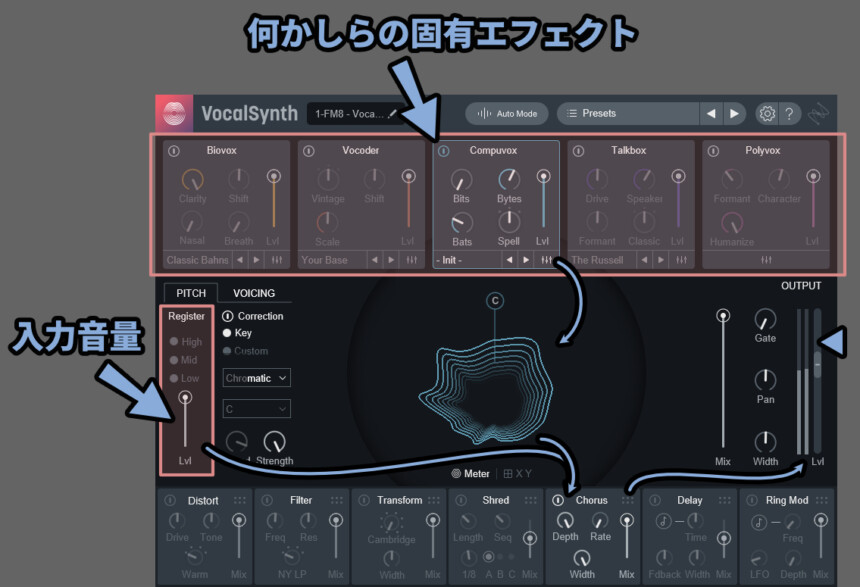
PITCHは入力した音の音程を調整するピッチ補正機能です。(詳細のちほど解説)
その中にある「Lvl」を上げるとピッチ補正への入力信号の音量を操作できます。
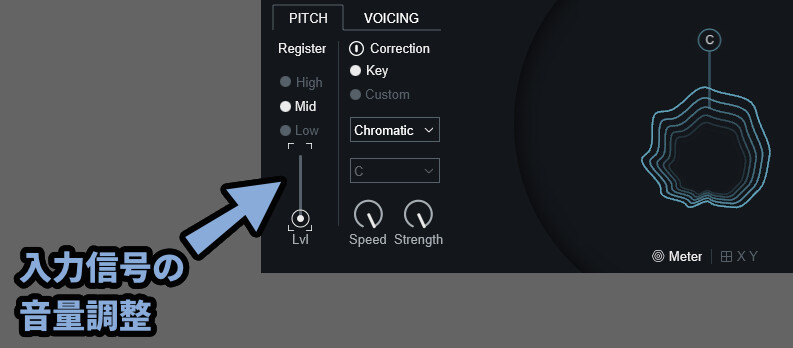
そして、PITCH内の「Correction」をオフにするとピッチ補正を無効化できます。
この状態で音を鳴らすと、少し劣化しますが元の音に近い音が鳴ります。
劣化してるというより「ステレオ感」が完全に消える形になります。
↓詳細はこちら。
なので、5つの固有エフェクト無しの状態で7つの標準エフェクトを使いたい場合は…
PITCHの「Lvl」を上げて、固有エフェクトをすべてオフにします。
これで “ステレオ感” は消えますが、
それ以外は原音に近い状態で7つの標準エフェクトをかけれます。
そしたら、エフェクトの内部を見ていきます。
7エフェクトの共通項目
7つのエフェクトには共通する項目があるので、そちらを先に紹介します。
(細かなパラメーターは、のちほど解説)
【7エフェクトすべてに共通する操作】
・左上の電源ボタン → オン/オフ切り替え
・右上の6つの点 → エフェクトの処理順変更
・Mix → エフェクトの有効度調整( Dry/Wet )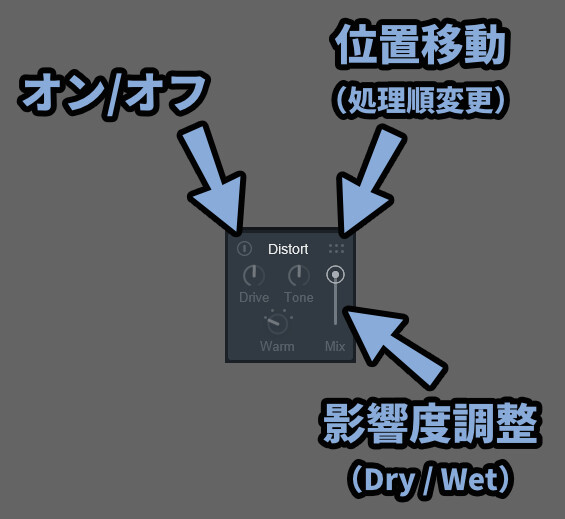
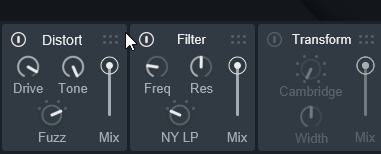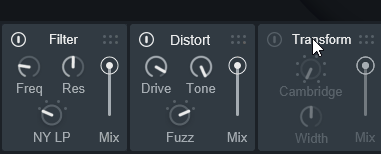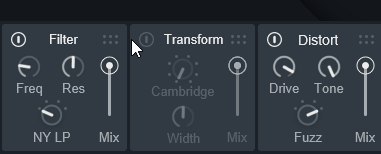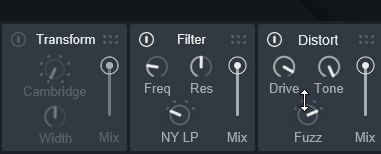
下部にある7つのエフェクトには、処理順という概念があります。
これは、左から右に進む流れです。

そして、この処理順は「右上の6つの点」をクリック。
そのままドラッグ&ドロップで変えれます。
Vocal Synth2の5つの固有エフェクトは、処理順設定は無いようです。
(中央のミキサーで混ぜる形なので、処理順は同列…?)
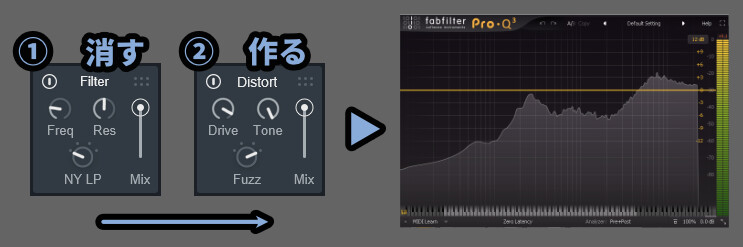
分かりやすいように下記の2つのエフェクトをピックアップ。
さらにつまみを操作し、この図の設定どおりにすると…

・「Filter」で高音域が消える
・「Distort」で高音域が生成される…という状態になります。
この設定で高音域が「消える/作られる」処理になってるので注意。
ツマミを回して他のパラメーター設定にすると、効果はまた別のモノになります。
【本来の意味と行った調整について】
・Filter
→ 周波数を指定して音をカットする処理
→ NY LP設定でFreqを下げることでハイカットフィルターに設定
→ 結果、Filterで高音が消えるようになっている
・Distort
→ 音の歪みを作る処理
→ Driveで影響度を調整
→ Driveを最大にしてDistortで作られた音を聞こえやすくする
→ Toneを操作でDistortで作られた音の音程を変える
→ Tone最大で高音がDistortで作られるようになる
→ 結果、Distortで高音が生成されるそしたら、並び順を調整。
「Filter」 → 「Distort」だと高音域が消えてから作られるので…
Distortで作られた高音の音が表示されます。
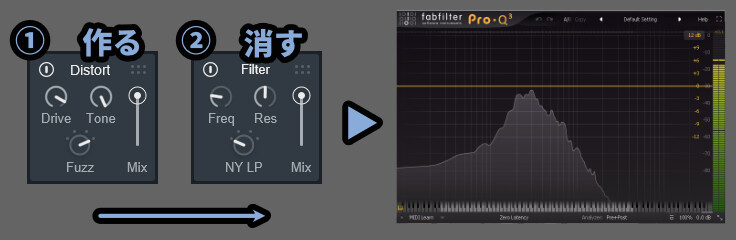
さらに、並び順を調整。
「Distort」 → 「Filter」だと高音域が作られてから消えるので…
高音が何もない状態になります。
↓動画版。
以上が、7つの標準エフェクトの共通項目です。
そしたら、7つのエフェクト詳細を1つ1つ見ていきます。
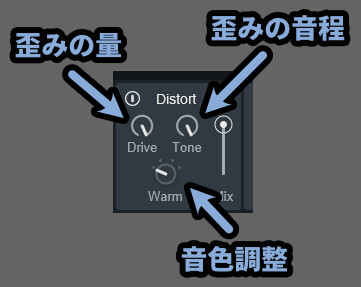
Distort(歪み)
Distortは音を歪ませます。
俗に言う、ディストーションです。
こんな感じの音になります。
パラメーターは下記の通り
【Distort】
→ 音を歪ませる処理
・Drive = 歪みの量(音量が変わるというより、効果時間が長くなる感じの変化)
・Tone = 歪ました音の "音程"
・Warm / Analog / Edgy / Fuzz = 音色調整以上が、Distortの解説です。
Filter
Filterは特定の周波数に対して音量を操作する処理です。
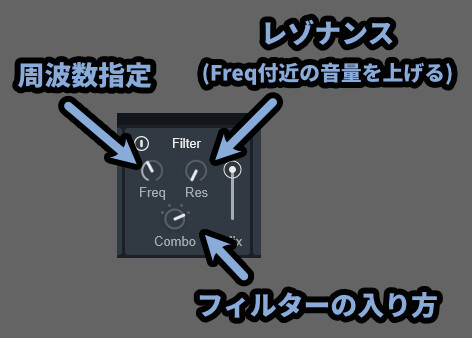
【Filter】
→ 周波数を指定して音をカットする処理
・Freq = 処理を入れる周波数の指定
・Res = 指定した周波数周りの音量を上げて強調する(レゾナンス)
・NY LP / NY HP / Scream / Combo = フィルターの入り方調整
【フィルターの入り方】
・NY LP → アナログモデリングのローパスフィルター
・NY HP → アナログモデリングのハイパスフィルター
・Scream → 指定した周波数の強調(レゾナンスを強める)
・Combo → Freqを下げるとローパスフィルターに、上げるとハイパスフィルターになるNY LP/HPの “NY” はアップステイト・ニューヨークを表します。
ここで1960年代に開発されたフィルターを再現したモノのようです。
(公式的には「音に温かみが入る」とのこと)
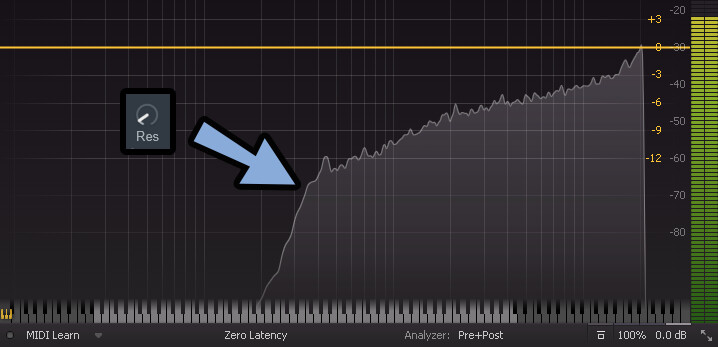
レゾナンスだけ分かりにくいと思うので解説します。
↓まず、普通に「NY HP」でFreqを設定するとこのような形になります。
そして、レゾナンスを上げると…
Freqで設定した周波数付近の音量が上がって強調されます。
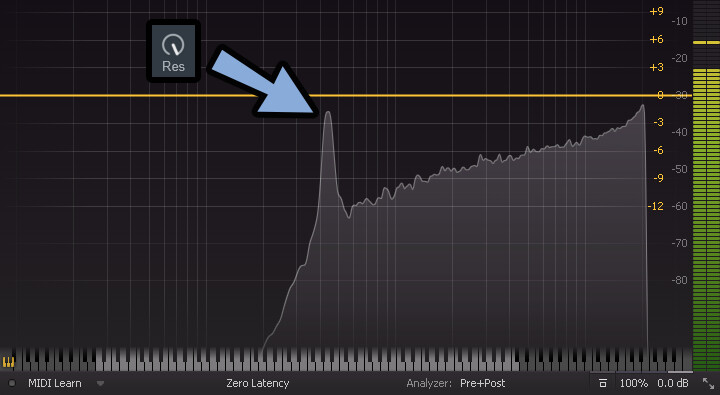
結果、レゾナンスを上げると “ミャーン” みたいな音が鳴ると言われてます。
以上が、Filterの解説です。
Transform
Transcormは音色調整です。
元は、スピーカー系機材を通した音の特性を再現しようとしたモノらしいですが…。
謎な進化をし過ぎており、もはや「音色調整」としか呼べないモノとなってます。
【Transform】
→ スピーカー系の機材を通して出た音を再現しようとしたモノ
→ 考え方が発展し、謎の環境も再現した音がある
→ 謎なモノが多すぎ過ぎるのでもう "音色調整" と覚えた方が良い
【Transformのパラメーター】
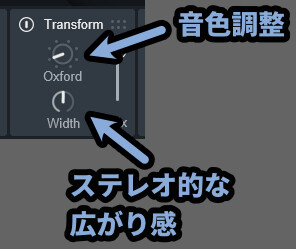
・Type(上側) = 音色調整
・Width = ステレオの広がり感調整
【Typeの中身】
・Hollow = 空の四角いカバンを叩いた時の特性を再現した音(ブリーフケース)
・Bright = エアポンプ、つまり空気入れの特性再現(明るく軽い音になる)
・Creep = iZotopeが何年も使ってる謎の特性(元ネタは忘却の彼方へ)
・Bass = 中音域をカットし、放送向きの音にする処理(もはや特性ですらない)
・Radio = 1960年代のラジオで鳴らしたような音
・Sterling = 小さなアンプを使った感じの音(低音をカット+3〜5 kHz付近を強調)
・Oxford = 2×10キャビネットの再現(700Hz〜3kHzを強調し+4kHz以上をカット)
・Cambridge = 別の2×10キャビネットの再現(中音を下げ、5kHz以上をゆるやかにカット)Witdthは直感的に分かると思いますが…
Typeに関しては、音を聞いて “ガチャ” を回す感覚で使った方が良いです。
ちなみに、Typeの特性はIR(インパルス・レスポンス)で取ってます。
これは一瞬だけ強い信号を送って、その後の状態を観察して解析する手法です。
OxfordとCambridgeに書いた「キャビネット」はこちらを意味します。
↓主にエレキギターなどで使われる、箱とセットになったスピーカーです。
そしてHollowのカバン、ブリーフケースはこちらの形のモノを指します。
(なぜか、良い音のになったらしい)
スピーカー系機材の再現は分かりますが…。
「空のカバン」や「空気入れ」の特性再現は謎。
以上が、Transformの解説です。
Shred
Shredは音を録音 → 再生する処理です。
録音や再生時間の長さを変えることで、複雑な変化を作ることができます。
これはまず、音を聞いた方がイメージがつかめると思います。
【Shred】
→ 音をサンプルして取得+指定した回数リピート再生する
→ 声をダブらせたりできる(やや複雑なディレイみたいな効果)
→ これに3つのステップシーケンサーが入ったもの(リズムパターンが8通り)
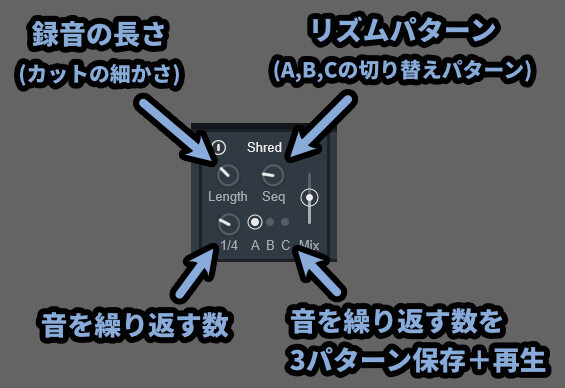
【Shredのパラメーター】
・Length = 取得するサンプルの長さ(カットの細かさ)
・Seq = リズムパターン(1~8通り)
・左下の数字 = 繰り返しの回数(1/n)表記
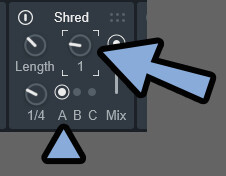
・A,B,C = 左下の数字を3つ格納できる(Seqを変えると「A,B,C」の再生パターンが変わる)Seqを「1」に設定すると、A,B,Cの所が「A」しか再生されなくなります。
まず、学習用にSeqを1に設定。
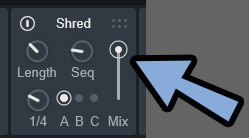
あと、初期状態ではMixが「50」になっており変化が分かりにくいです。
こちらも学習用に最大にします。
この状態で、Aをクリック。
「左下の値」と「Length」を同じに設定。
→ すると、ちょっと待てば普通に再生されます。
ちょっと待つ処理は…
音を1回鳴らしてサンプルを取る処理が行われるまでの時間によって生じてます。
これを理解するために、パラメーターをより詳しく見ていきます。
「Length」は再生された音を区切りって記録する “間隔” です。
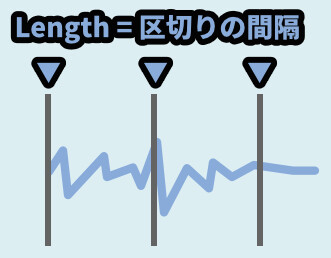
この処理が入る事で、録音データはこのような “カタマリ” に区切られます。
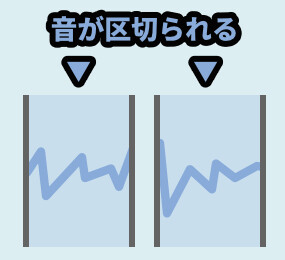
あと、記録される時間は音の “区切り幅” によって自動で決まります。
→ Lengthは音の記録時間を表してるとも解釈できます。
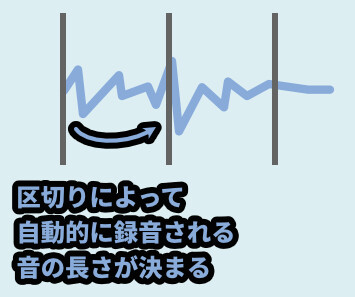
そして「左下の値」が再生する間隔です。
なので、Lengthより左下の値を早めると、音がダブって聞こえます。
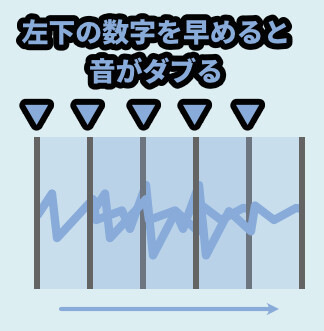
そして、Lengthより左下の値を遅めると、音が途切れます。
これは左下の値が長すぎて、Lengthで記録された音の情報が無くなるからです。
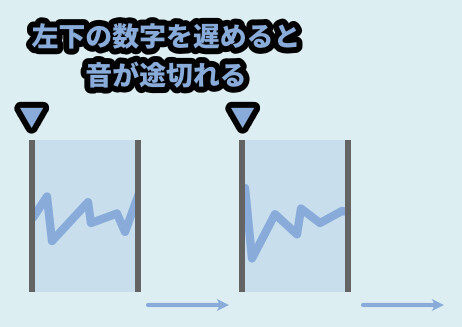
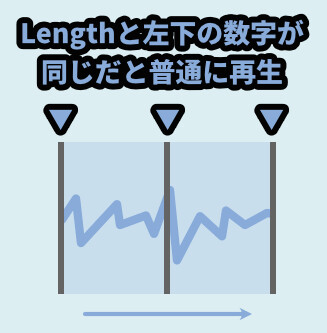
そしてLengthと左下の値が完全に同じだと、録音と再生の間隔が完全に一致します。
なので、しばらく待つと特に変化がない状態で普通に聞こえます。
さらに「Seq」の値を操作。
すると「A,B,C」の3要素がシーケンサー的に選択されるので…
リズムパターン、リピートのされ方が不規則になります。

このA,B,C切り替えの挙動はVocal Synth側が用意したパターンしか使えません。
→ シーケンサーを操作するというよりは、パターンを変えるモノになります。
ちなみに「A,B,C」の所をクリックすると、それぞれの要素で「左下の値」を変更できます。

なので「A,B,C」にある左下の値をすべて1/4に設定。
さらに「Length」を「1/4」にすると、
しばらく待てば “普通に” 再生されます。
以上が、Shredの解説です。
Chorus
Chorusは同じ音程のタイミングやピッチがズレた音を重ね音に厚みをつく処理です。
普通は凄く短い遅延を作って制作します。
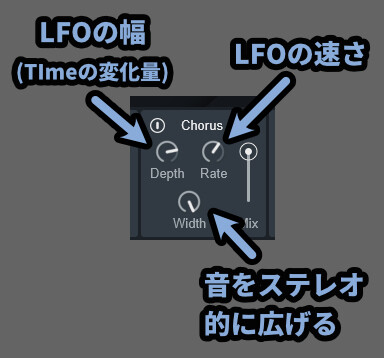
Voval Synth2はなぜか “遅延処理の時間” に対して強制的にLFOが入ります。
【Chorus】
→ 同じ音程の音を重ねる処理
→ タイミングやピッチのわずかなズレを作り、厚みを持たせる
→ 一般的には短いディレイ(遅延)処理で作る
→ VocalSynthのChorusは、なぜか遅延処理にLFOが入ってる(強制)
・Depth = LFOの幅(ディレイTimeの変化量に影響を与える)
・Rate = LFOの速さ
・Width = 音の広がり感(ステレオ的変化)LFOはオフにする設定が無いので、強制的に入ります
【Rateの操作で効果を変える方法】
Rateを早めれば、LFOの変化がとても速い状態になります。
その結果、ほぼLFOが入った事を認知できなくなり "音に厚み" が生まれます。
→ 普通の「Chorus」エフェクト的な使い方ができます。
//ーーーーー
Rateを遅めれば、LFOの変化が遅く状態になります。
その結果、LFOが入ってる事を知覚できる + LFOの影響で音程も少し変わるので…
一般的なピッチに対してLFOをかけたような音になります。
(公式的には「人工的なヴィブラート」と書いてました。)↓そして、こんな感じの音になります。
以上が、Chorusの解説です。
Delay
Delayは音の遅延を作る処理です。
ディレイの長さを変えることで3つの効果(エフェクト)を作れます。
【ディレイで作れる3つのエフェクト】
◆フランジャー/Flanger
→ 凄く短いディレイ(0.5〜5ミリ秒)
◆コーラス/Chorus
→ やや短いディレイ(15〜30ミリ秒)
→ 本来の"コーラス"はこの処理を遅らせるだけの処理を指すことが多い
→ 別名Doubler
◆ディレイ(狭義)
→ コーラスより長い遅延時間
→ 音がやまびこのように聞こえる効果Vocal Synth2のDelayは「0~1000ミリ秒」まで指定できます。
なので、理論上はすべてに対応できます。
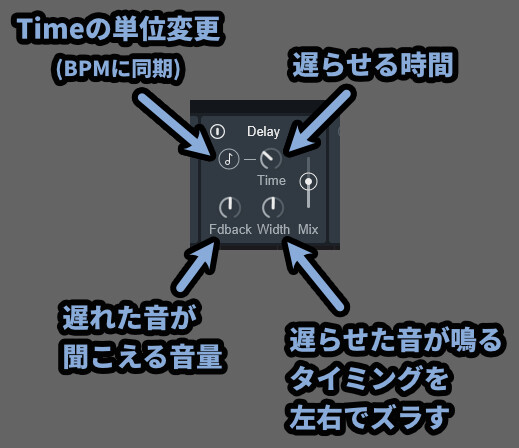
【Delay】
→ 音の遅延を作る処理
→ 遅延時間を変えると3つの効果が得られる
・音符マーク → Timeの時間単位をBPMに合わせる(1/n表記)
・Time → ディレイの音が鳴るまでの時間
・Fdback → ディレイによる音の音量(フィードバックの略)
・Width → 操作するとピンポンディレイになる(右/左で音がばらける)Vocal Synth2のディレイは初期状態で「ピンポンディレイ」になってます。
なので、音が左右に分散して聞こえます。
→ 1000ミリ秒(1秒)を入力した場合、左は1秒、右は2秒後に聞こえる。
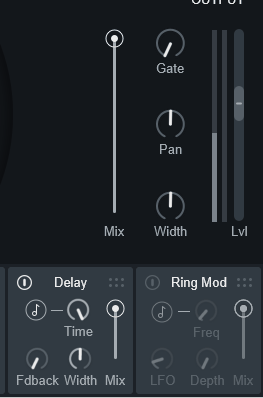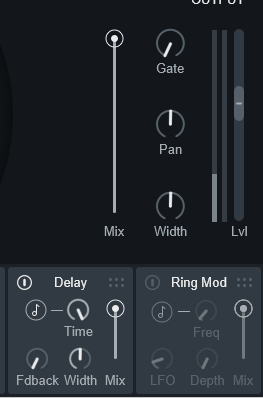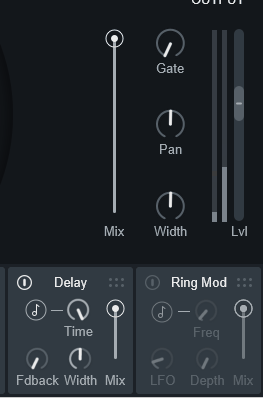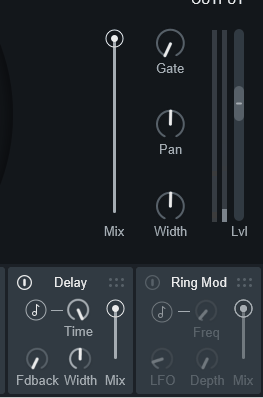
この処理が入ったままだと「フランジャー」や「コーラス」 “らしい” 音の再現は難しいです。
なので、まず学習段階ではWidthを0にすることをおすすめします。
Widthを0にすると、音の左右分散が消える
=ピンポンディレイを解除できます。
ちなみに、Widthを最大にすると1週回って完全なピンポンディレイじゃなくなります。
これは… 正直、謎な挙動です。
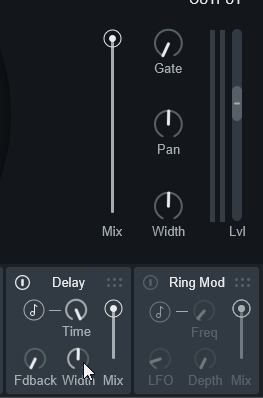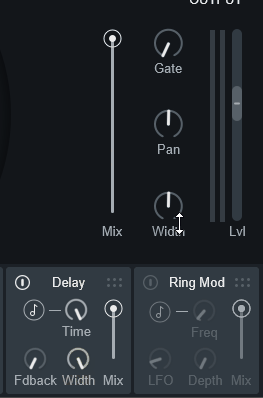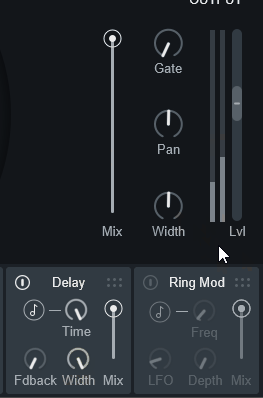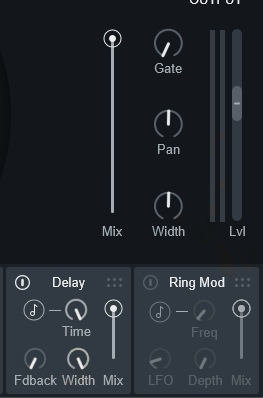
Widthを0にさえすれば、後はよくあるディレイと同じです。
TimeとFdbackを操作して音を作るだけになります。
あと、音符マークを使えば早さの単位がBPM表記になります。
以上が、Delayの解説です。
Ring Mod
次はRing Modを見ていきます。
これを理解するために、まずRing Modことリングモジュレーターについて解説します。
【リングモジュレーターについて】
・リングモジュレーターは2つの音を合成する処理
・通常の音合成とは違う、出力結果を返す
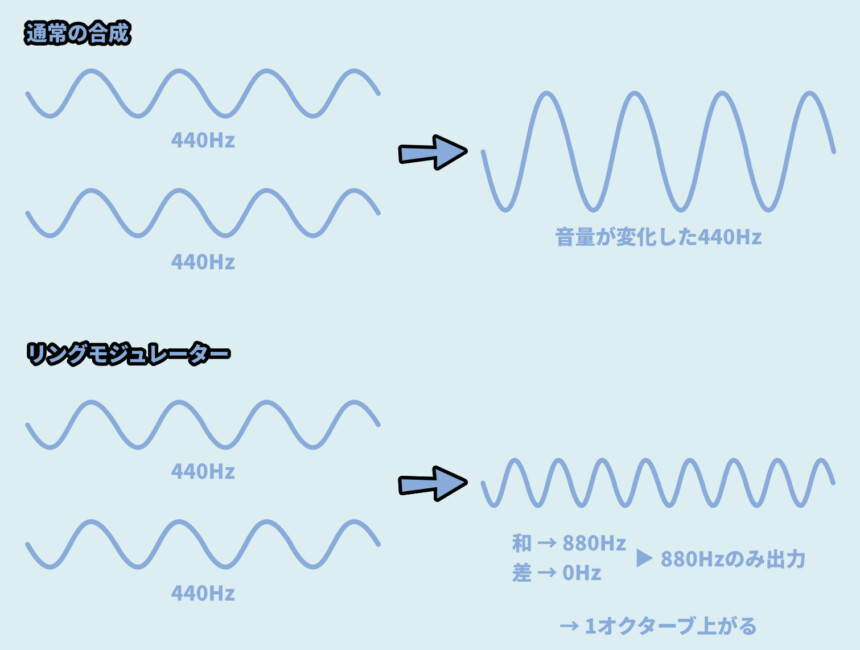
・通常の合成
→ 440HzのSin波を2つ入力した場合… 音量に変化が生じる
→ 音量が2倍になる
・リングモジュレーター
→ リングモジュレーターは2つの音から周波数の「和」と「差」を混ぜて出力する
→ 440HzSin波を2つ入力した場合… 和=880Hz、差=0Hz
→ 880Hz、つまり1オクターブ上がった音 "だけ" が出力されるまとめると、下図のような挙動になります。
次は2つの波形の周波数が違う場合の挙動を見ます。
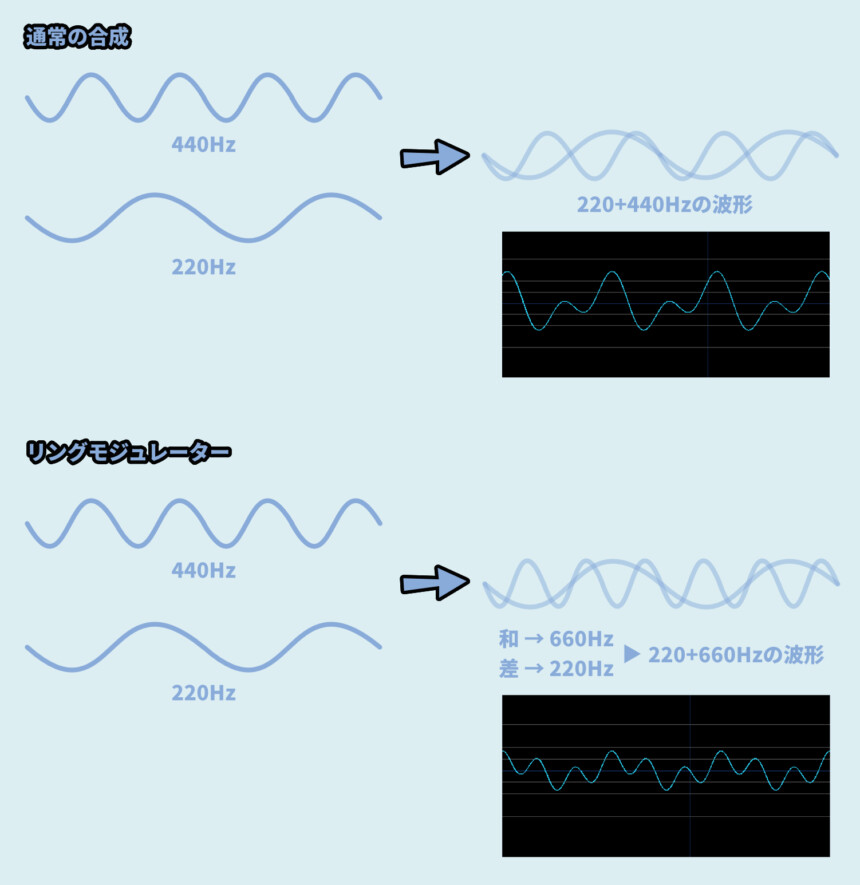
「440Hz」と「220Hz」を入力した時の挙動は下記。
・通常の合成
→ 440Hz+220Hzを合成した場合…
→ 2つの波形が足し算で混ざった音になる
→ 440Hzと220Hzの音が同時に聞こえる(和音)
・リングモジュレーター
→ リングモジュレーターは2つの音から周波数の「和」と「差」を混ぜて出力する
→ 440Hz+220Hzを入力した場合… 和=660Hz、差=220Hz
→ 660Hzと220Hzの音が同時に聞こえる(和音)つまり、リングモジュレーターを使った方が波形が複雑になります。
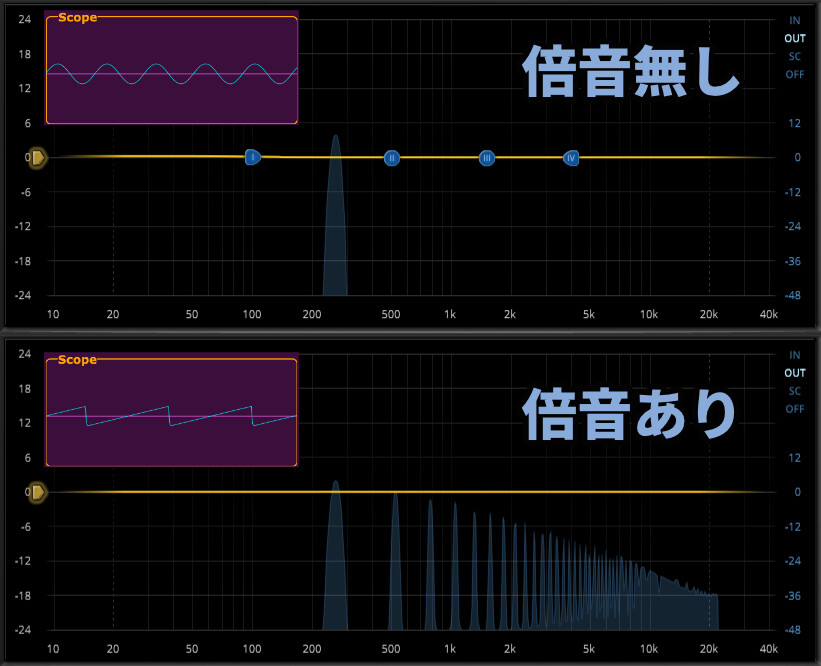
ただ波形はSin波でないことが多く、Sin波以外の波形は倍音が入ってます。
そして、倍音もすべてリングモジュレーター処理(和と差の出力)が行われます。
なので、実際には頭で考えて制御するのは困難なモノとなってます。
この波形が複雑になる点を要約して
「金属っぽい音を作る処理」と認識で大丈夫です。
これが主に使われるのはシンセサイザーです。
↓CA 2600のリングモジュレーターを使うとこんな感じの音になります。
そして、これを元ネタにしたらしきモノがVocal Synth 2に入ってます。
ただVocal Synth2のRing Modは謎な処理が入りまくっててるので…
別モノと考えた方が良いです
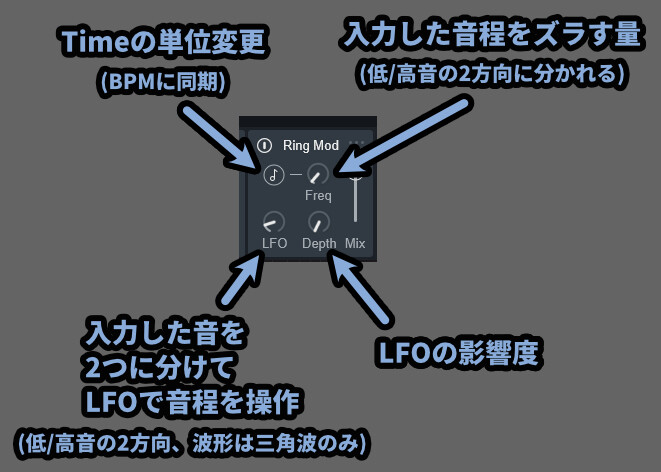
【Vocal Synth2のRing Modについて】
・入力で使えるのが "1波形" のみ
・LFOを使って「和」と「差」を再現した処理が起こる
・波形が1つしかないのFreqで周波数のズレを設定し「和」と「差」を同時に決める
・さらに、ピッチLFOが入って訳が分からない事になってる(LFOは三角派のみ)ようするに、本来のRing Mod処理を行ってない。
→ Ring Modを再現したっぽい音を作るだけの処理。
なので、Freqを下げると「トモレロ」になるという謎の不具合?が発生する。
(音が消えたり現れたりする効果)
Freqを上げることで、はじめて「Rign Mod」っぽい音になる。
みたいな、謎な処理になったようです。
パラメーターの解説はこちら。
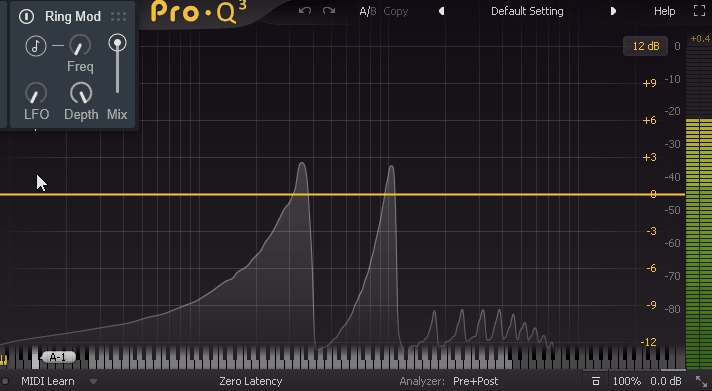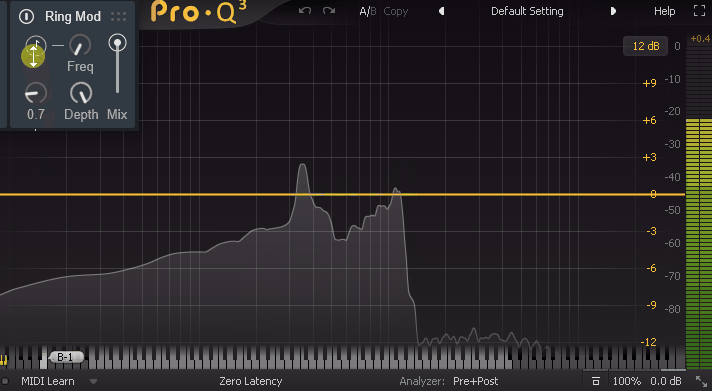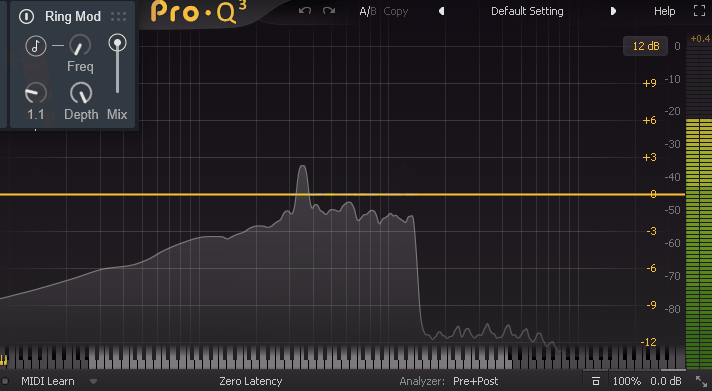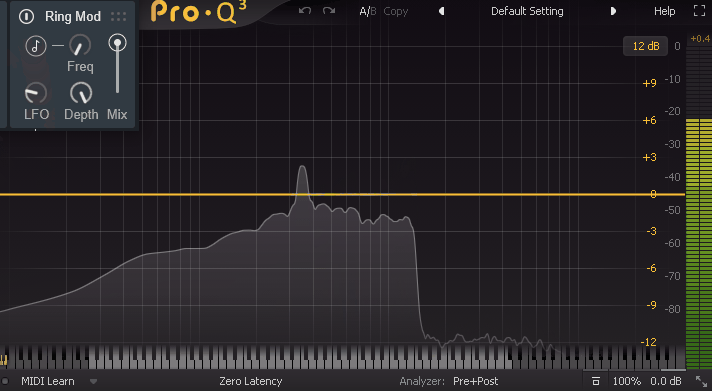
・音符マーク = Freqの値がBPMに同期(表記が1/nになる)
・Freq = たぶん、誤差量。音の周波数を左右に分ける(高音/低音)
・LFO = 音程を操作するLFOの速さ(波形は三角派のみ)
・Depth = LFOの影響度(0でLFOを無効化できる)音符マークを有効化するとBPMに同期します。
そして「LFO」と「Depth」が操作できなくなります。
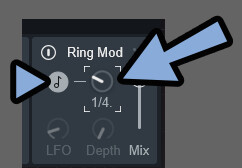
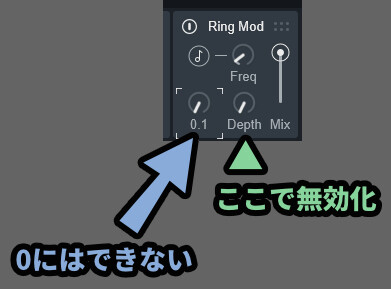
音符マークが無効の場合、LFOの “動き” 自体は無効化できないです。
なので「Depth」を操作してLFOの変化量を0にして無効化する形になります。
そしたら次は「Freq」を見ていきます。
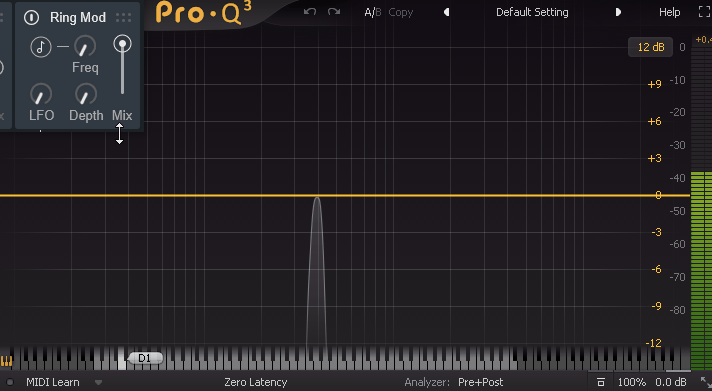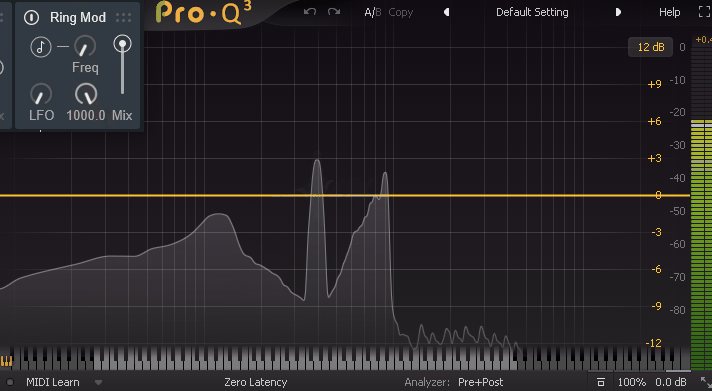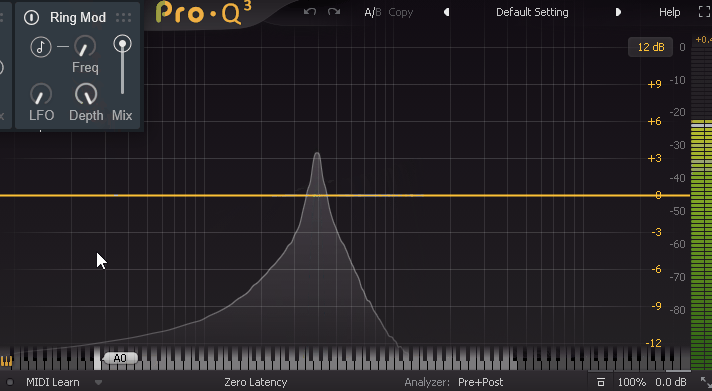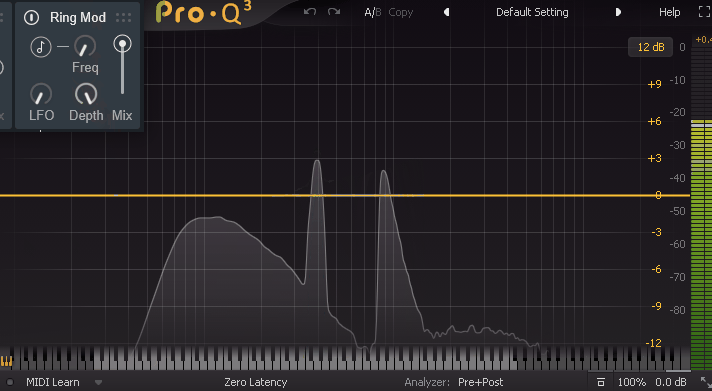
Sin波を使い、実際にFreqを操作した様子がこちら。
↓非常に直感に反しますが、周波数が左右に分かれていきます。
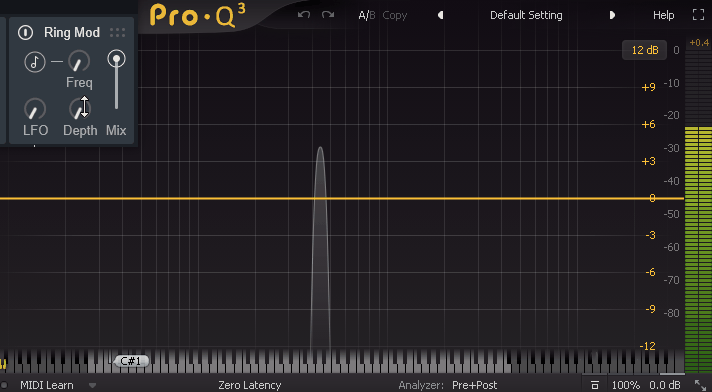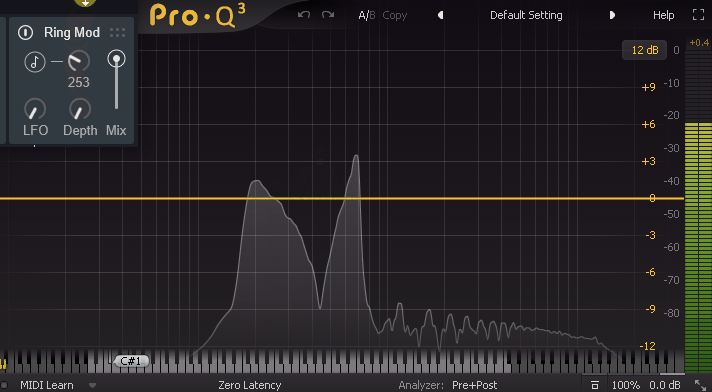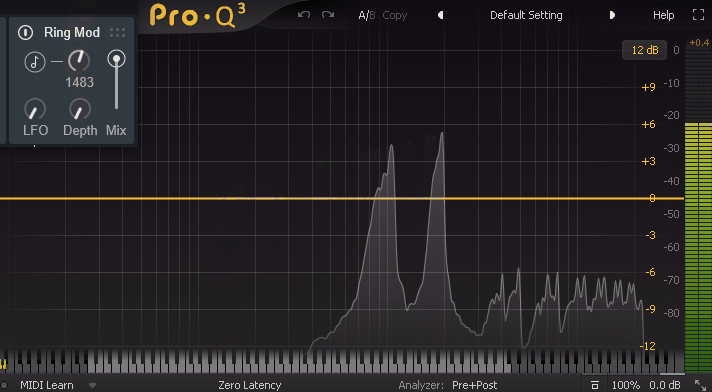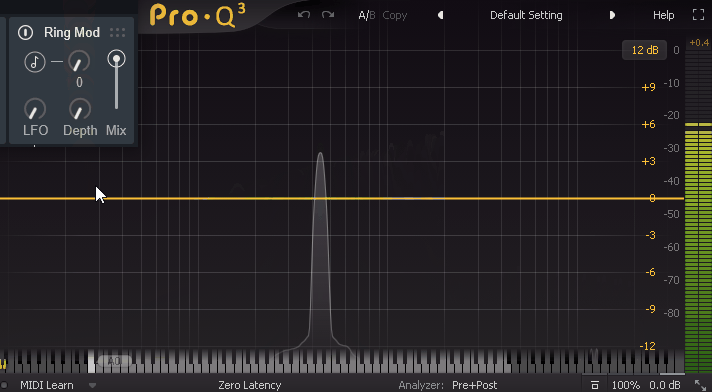
たぶん、この2方向に分かれるという特徴が「Ring Mod」を元ネタにしたポイントだと思います。
ある程度の段階で倍音が増えるのは、周波数が左か右端に行って
それ以上、波形を動かせなくなったのが原因と考えられます。
三角波を使い、実際にFreqを操作した様子がこちら。
↓さらに直感に反しますが、倍音ごとに周波数が左右に分けれていきます。
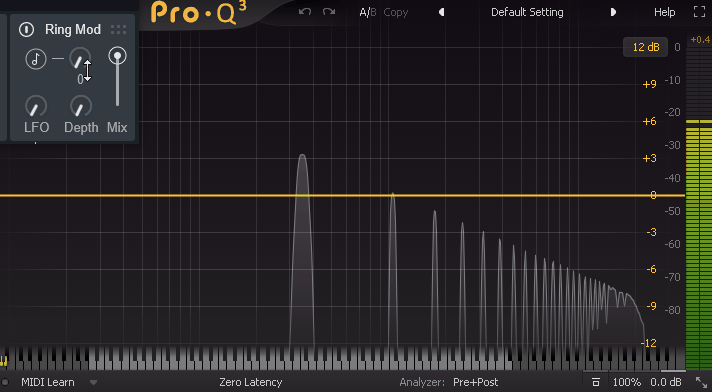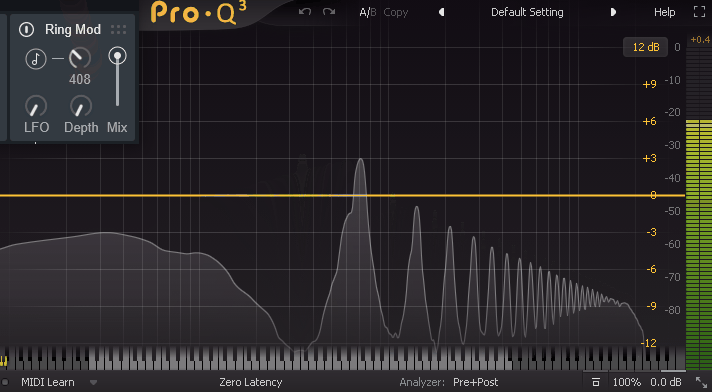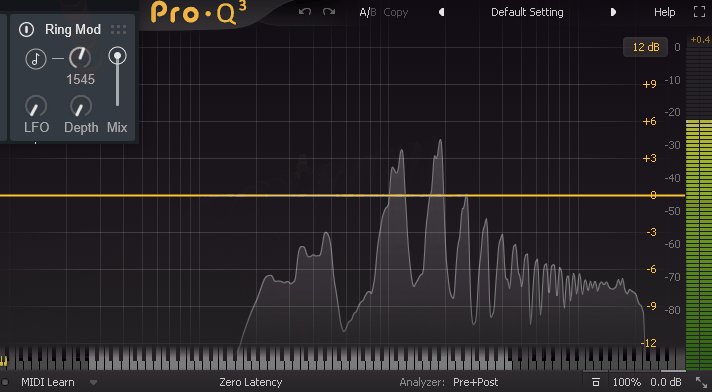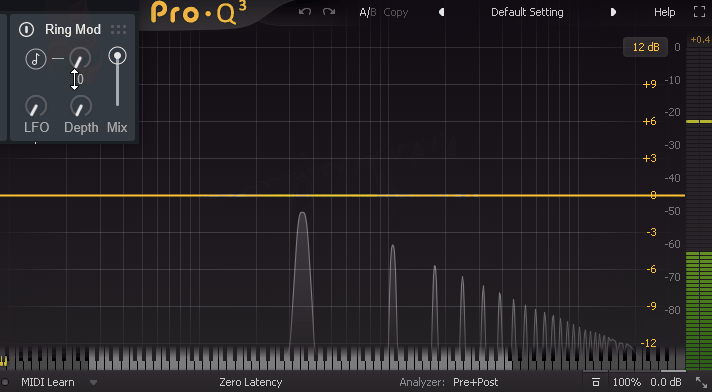
たぶん、これは入力した音を2つ保存。
そして、それぞれにFreqの値だけピッチを上げる/下げる処理を入れてる。
…と考えられます。
では、Freqを「0」にすると何も変化が起こらないと思われますが…。
三角波のまま、実際に操作した様子がこちら。
↓この処理だと、何故か周期的音が消えます。これが謎です。

公式には、Freq = 0で周期的に音を消す(トモレロ)を再現できると書かれてました。
ただ、なぜこうなるかの仕組みは本当に謎。
たぶん、音を入力する → その音を2つに分ける
→ 指定したFreqの値だけ音程を「上げる」と「下げる」
この2つの処理を合成してるっぽいですが…
それだと、Freq「0」のときにトモレロが起こる理由が謎なんですよね。
音を反転させてるなら、Freq = 0の時点で対になって消えるはず。
なので、もしFreq = 0ならば、2つの波形のうち片方を周期的に位相反転させるみたいな…
謎の処理をしてるのかなと思いましたが…謎です。
(いや、プログラム的に面倒すぎでしょ…)
これは色々やりましたが正直、分からなかったです。
Sin波でも同様に、実際にFreqを「0」にすると「トモレロ」になります。
正直、意味が分からない挙動をしてます。

なのでFreq=0でトモレロ。
それ以外はRing Mod “っぽい” 音が作れるモノという認識で大丈夫と思います。
たぶん、音を入力する → その音を2つに分ける
→ 指定したFreqの値だけ音程を「上げる」と「下げる」
この2つの処理を合成してるっぽいですが…
それだと、Freq「0」のときにトモレロが起こる理由が謎なんですよね。
音を反転させてるなら、
もしFreq = 0ならば、2つの波形のうち片方を周期的に位相反転させるみたいな…
謎の処理をしてる…?(いや、プログラム的に面倒すぎでしょ…)
これは色々やりましたが正直、分からなかったです。
あとDepthを上げると、LFOの効果でこちらも音程が左右に分かれます。
元となった音程の山はFreqを少し上げると消えます。
こちらも謎です。
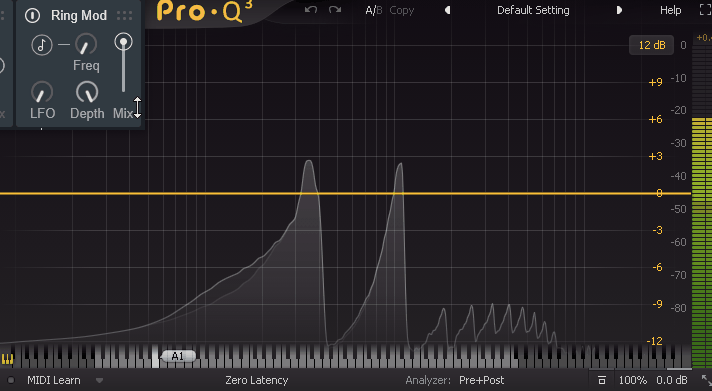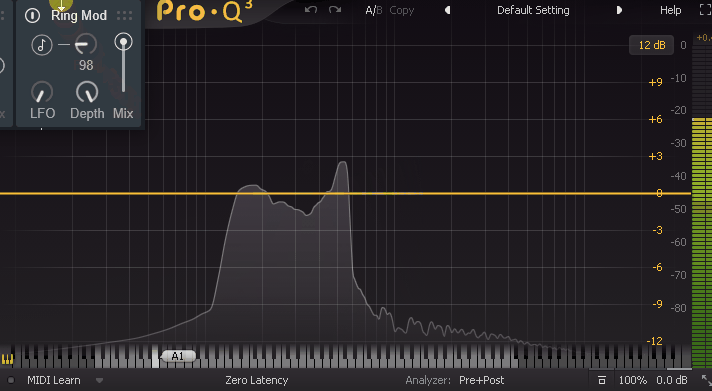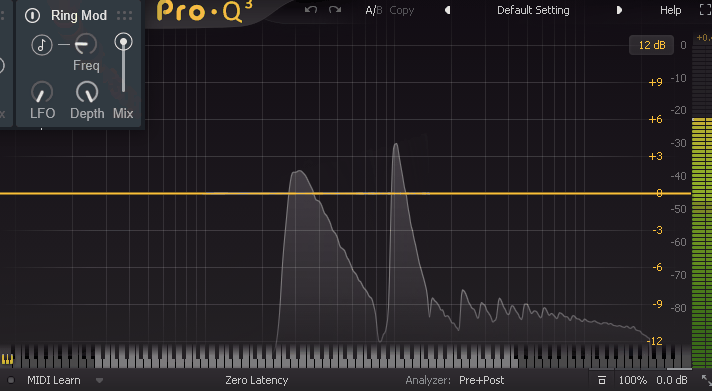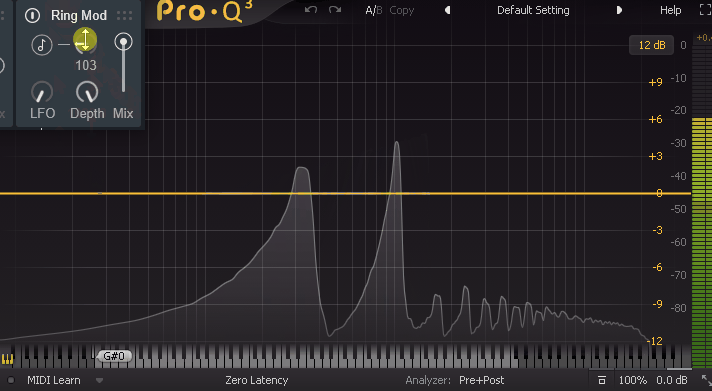
そして、LFOの値を上げると動きが早くなります。
↓その結果、このような音が作られます。
最初の方は意味の分からないエフェクト感が凄いですが…
値の誤差を抑えめにして、音のオクターブを高めにすれば
確かにRing Modっぽい音にはなります。
以上が、Ring Modの解説です。
X/Yパッドについて
中央下部の「X/Y」を押すと、2つの要素の音量などを制御することも可能です。
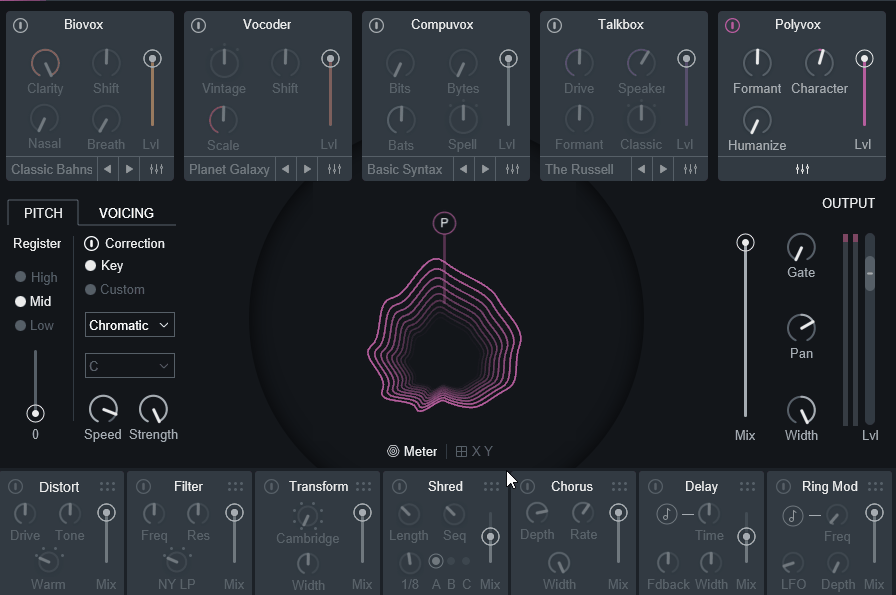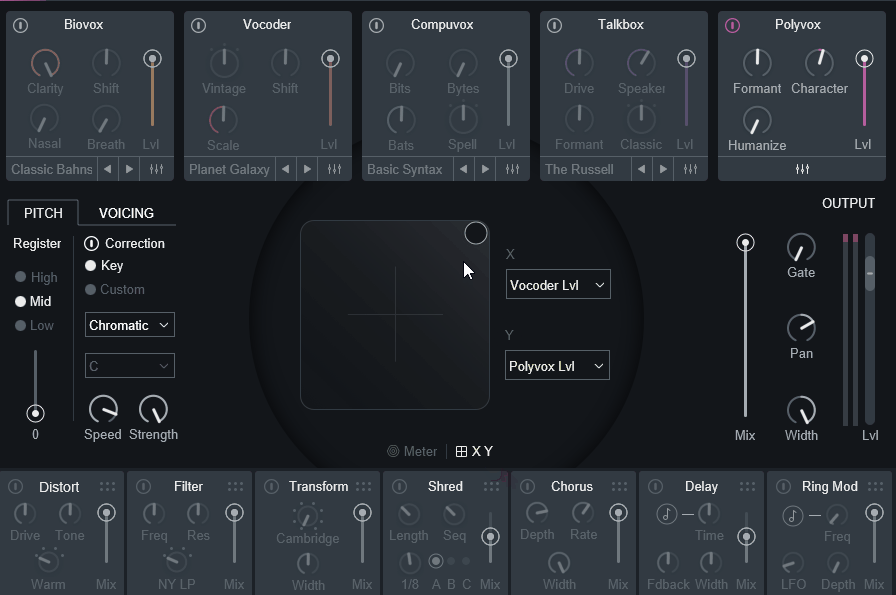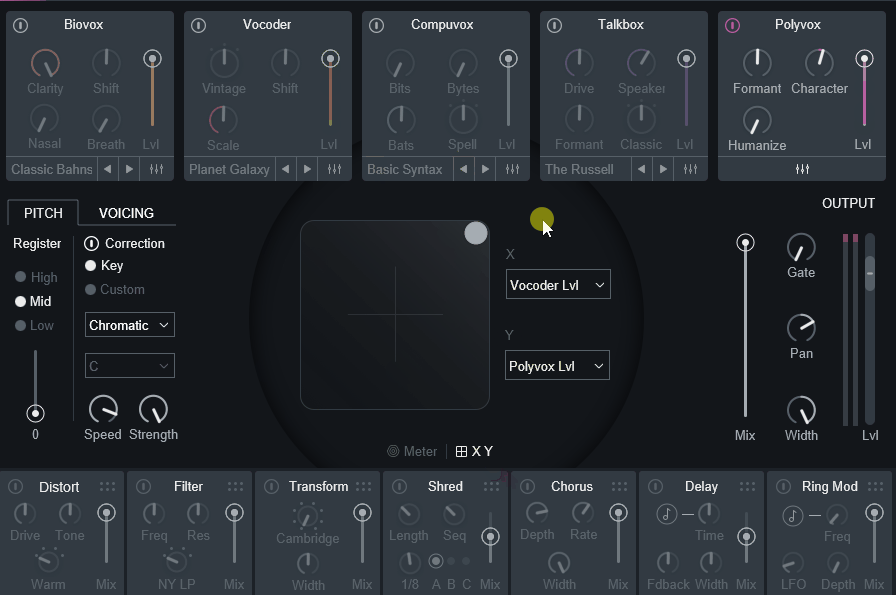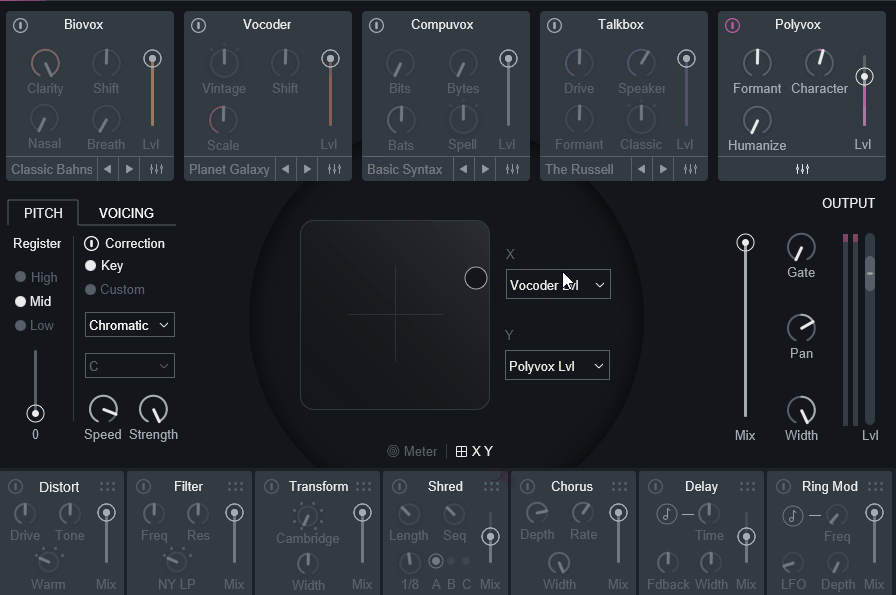
XとYの所で制御する要素を変更できます。
ここで設定すれば、ボリューム以外の要素を制御できます。
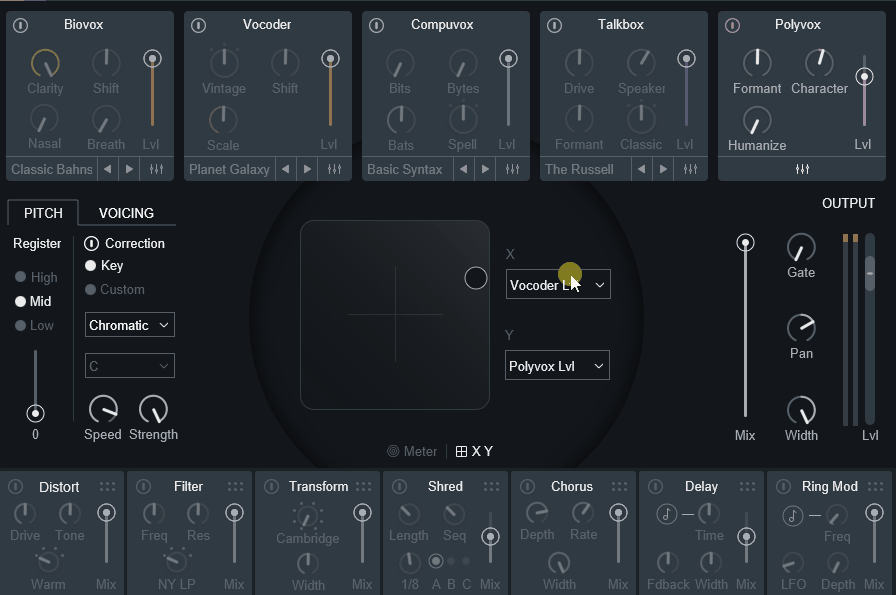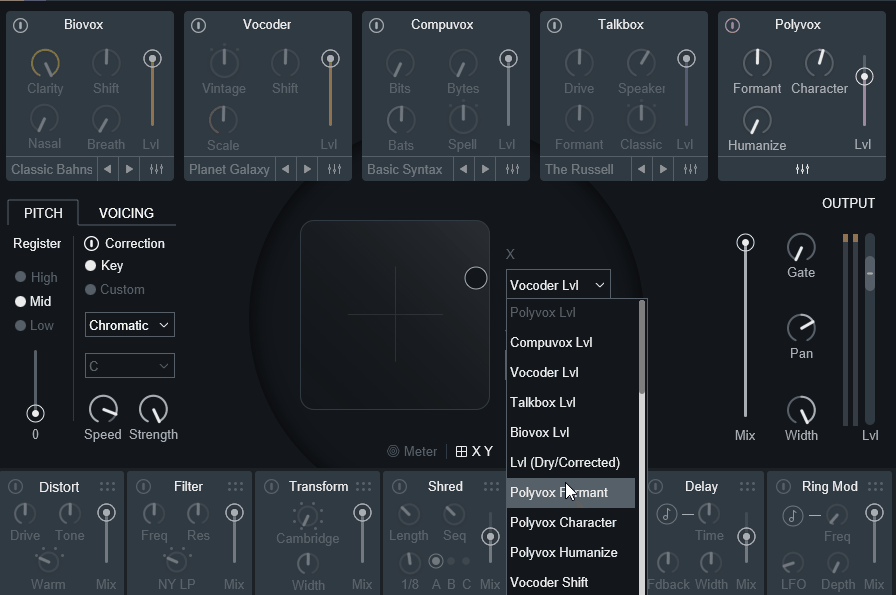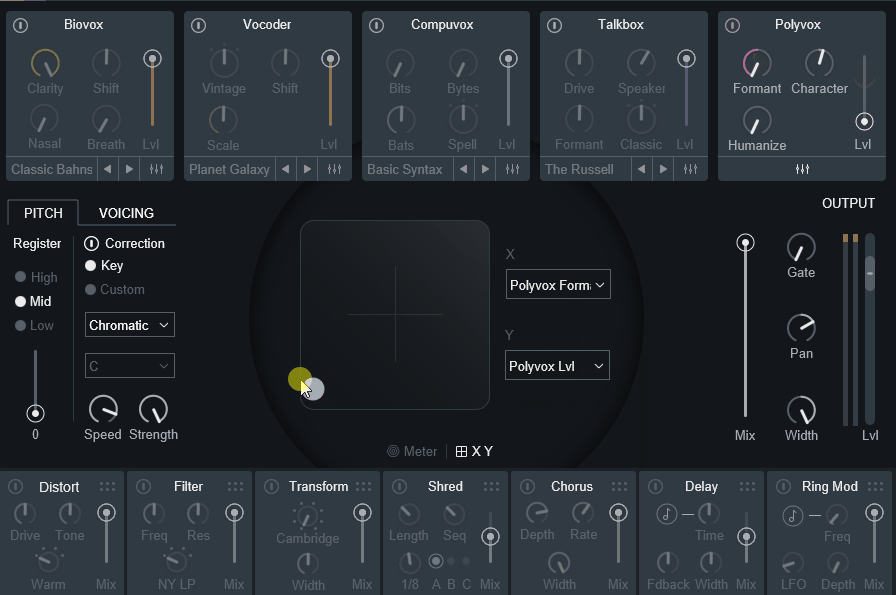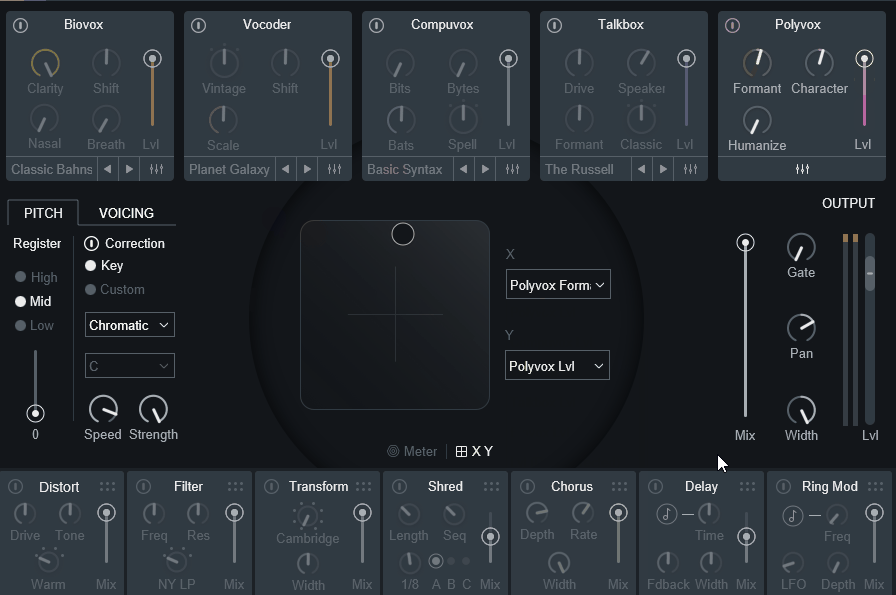
またX/Yでは下にある標準エフェクトのパラメーターも操作可能です。
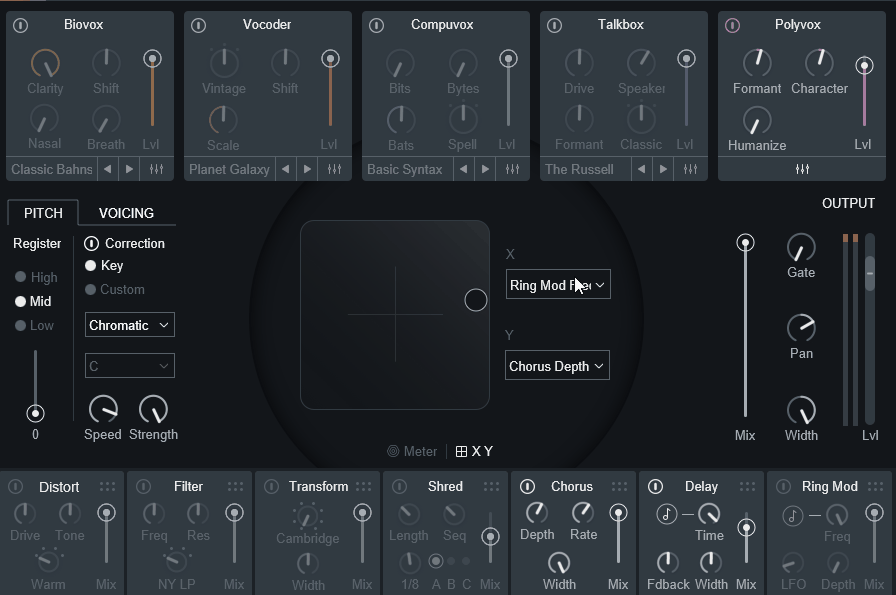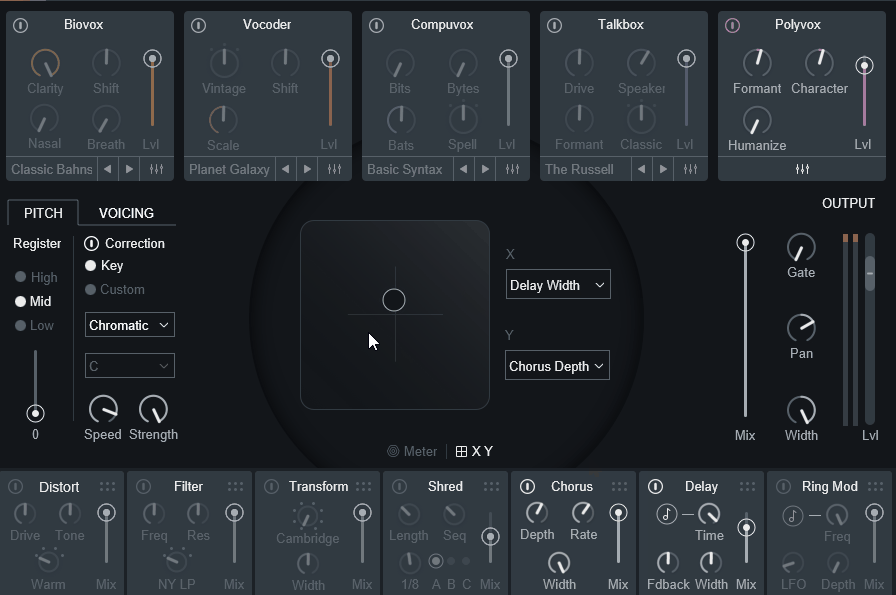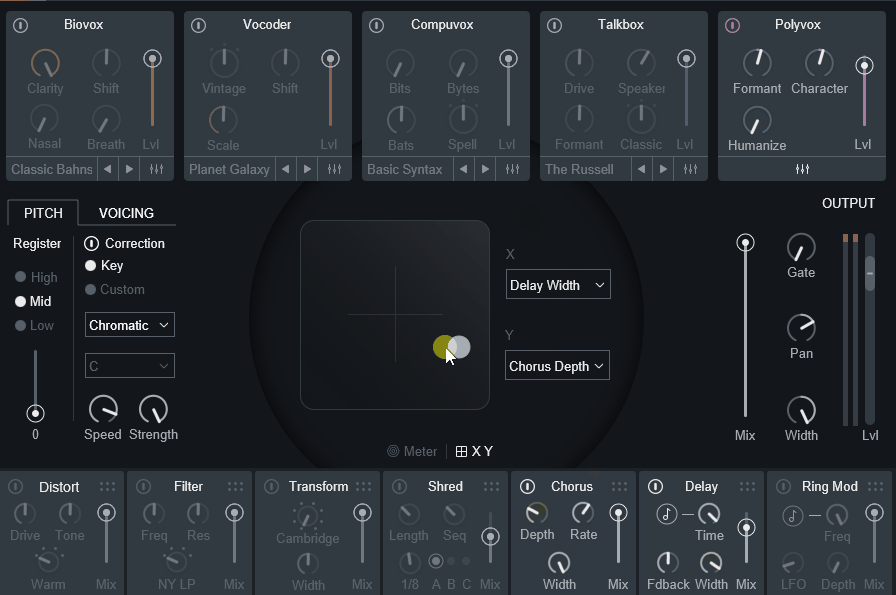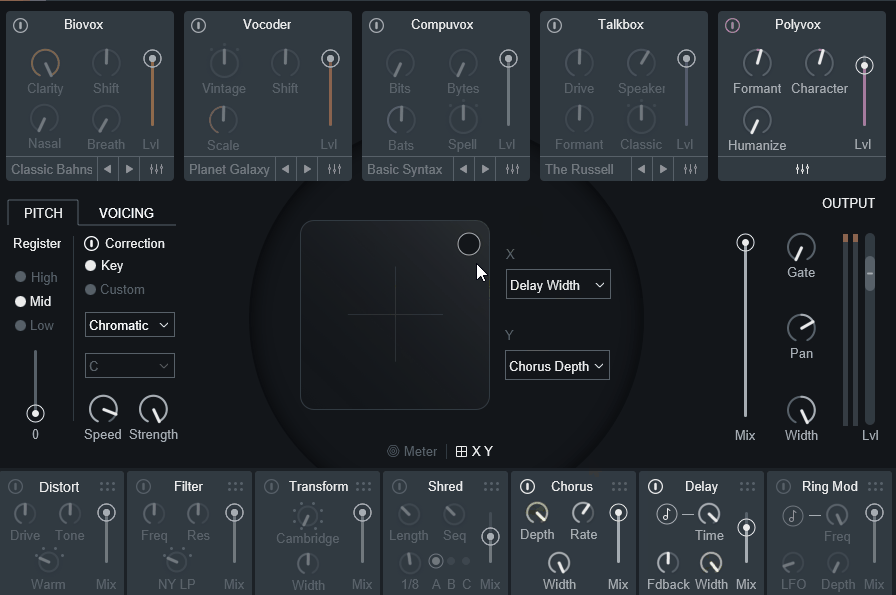
ただ普通につまみを操作すれば良いので
あまり使わないかなと思います。
その他の機能
左上の所でVocal Synth上の表示名を変更できます。
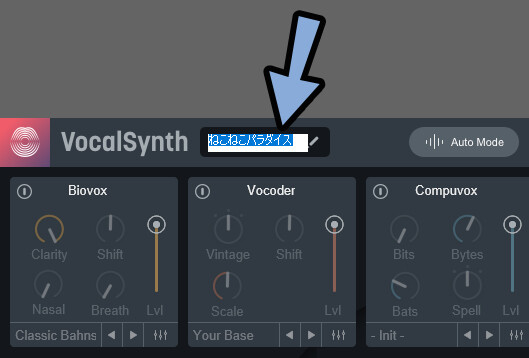
変更させるのはVocal Synth上の表示だけです。
DAWなどの表示には影響を与えません。
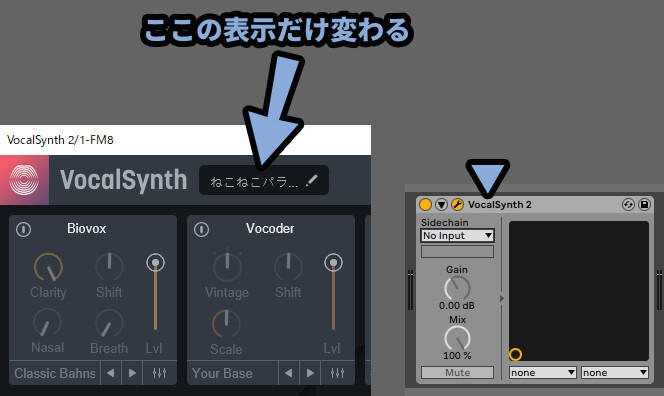
右上の歯車ボタンを押すと、より細かな設定が表示されます。
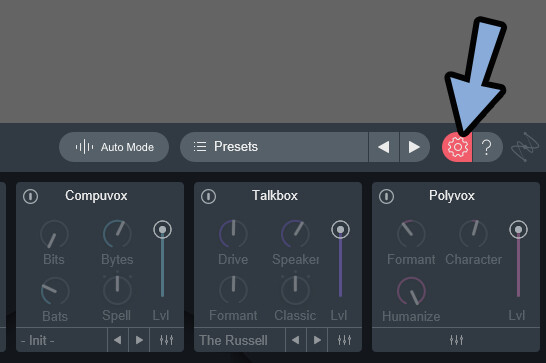
歯車ボタンを押すと、このような画面が出てきます。
まず、上の2つから解説していきます。
・Enable true bypass
→ 動作が軽くなるが、音の切り替わり時にノイズが出る
・Low latency Talkbox
→ Talkboxの動作プログラム変更
→ 精度を取るか、軽さ取るかの問題
→ オンだと精度が上がるが、動作負荷が上がる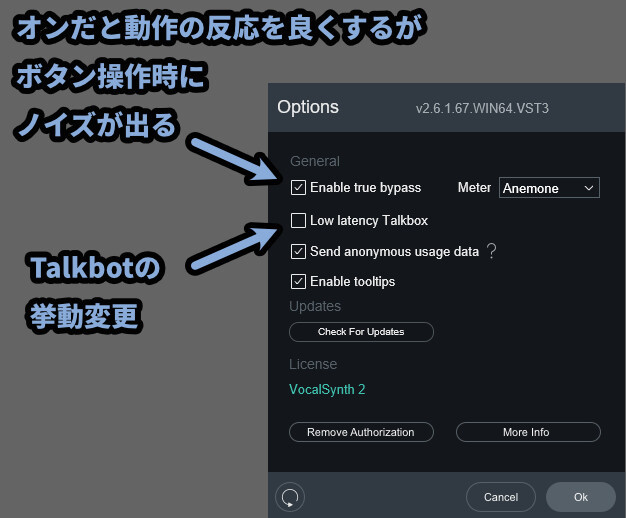
Enable true bypassはレイテンシーを減らします。
なので、CPU使用率にはあまり影響を与えません。
レイテンシーは、特定のパラメーター操作を行った際に処理が反映されるまでの遅延時間です。
処理的な話をすると、Enable true bypassがオンだと常時、信号の入力待ち状態にするようなので、たぶんオンの方が負荷は高いです。(ただCPU使用率に目立った変化は生まれません)
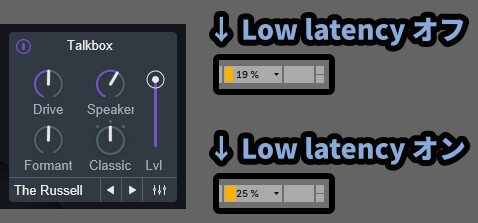
Low latency Talkboxは、Talkboxのプログラム処理を切り替えます。
◆Low latency Talkboxオフ
→ フォルマントなどの入力した音の解析精度が高い
→ 処理の負荷が上がる
→ パラメーター操作時の遅延が増える(レンテンシー)
◆Low latency Talkboxオン
→ フォルマントなどの入力した音の解析精度が低い
→ 処理の負荷が下がる
→ パラメーター操作時の遅延が減る(レンテンシー)これは、目に見えてCPU使用率が変わります。
↓は適当な音にTalkboxだけを有効化して、違いを検証したモノです。
そしたら、次に進みます。
・Send anonymous usage data
→ 製品改善用のデータを匿名で送る
→ 主にクラッシュと使用状況のデータが送られる(詳細)
→ 個人情報や音源データなどは収集してない
・Enable tooptips
→ ボタン上にマウスを置くと説明が出る(英語のみ)
・Meter
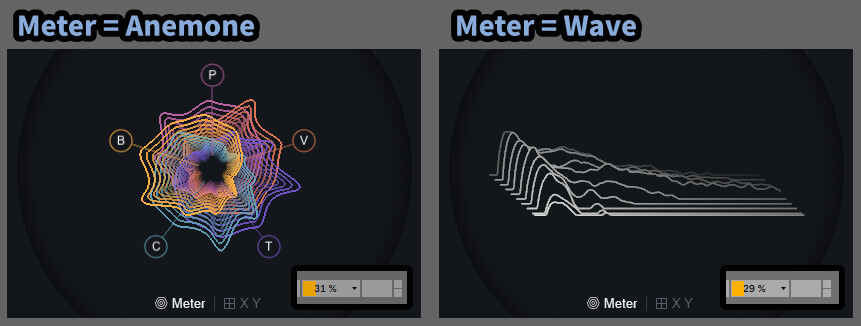
→ 中央部分のプレビュー変更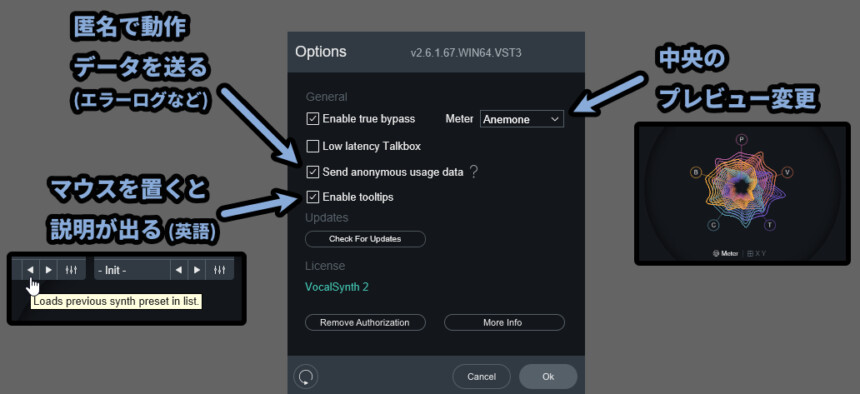
Meterの表示パターンは「Anemone」と「Wave」の2通りあります。
Waveの方が気持ち、若干CPU使用率が低いです。(誤差の範囲)
そしたら、次に進みます。
・Check For Updates
→ iZotopeポータルを起動する
→ iZotopeポータルでアップデートを確認
・Licenseより下の表示
→ ライセンス認証関係なので、基本触らない
・Remove Authorization
→ ライセンス認証を無効化する
(押さない事をおすすめします)
・More Info
→ ライセンスに関するヘルプに飛べる(こちらのページ)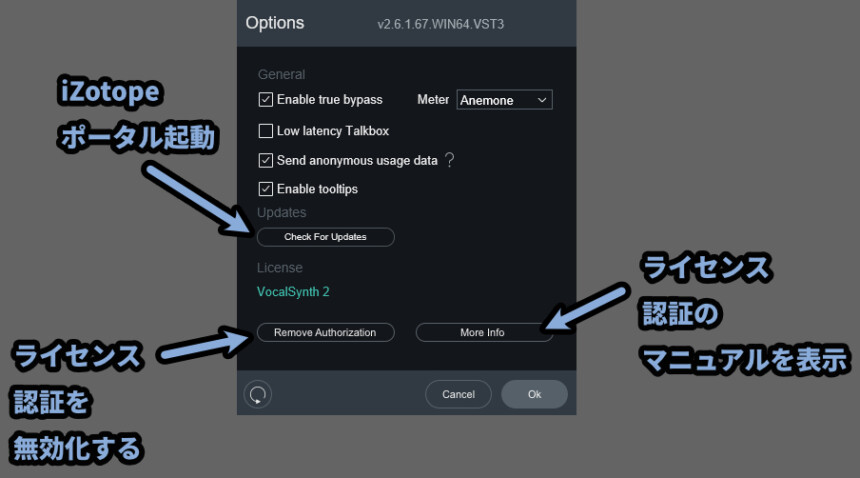
最後に下部分。
ここは「General」の状態に関する操作を行う場所です。
・更新マーク(左下)
→ Enable tooltips以外のGeneralの状態を初期化する
→ General部分の上3つが有効化される
・Cancel(右下)
→ Generalの変更を破棄
→ Options画面を開いた時の設定に戻す
→ Options画面が閉じられるので注意
・Ok(右下)
→ Generalの変更を保存する
→ Options画面が閉じられるので注意
→ 右上の「×」ボタンでも代用可能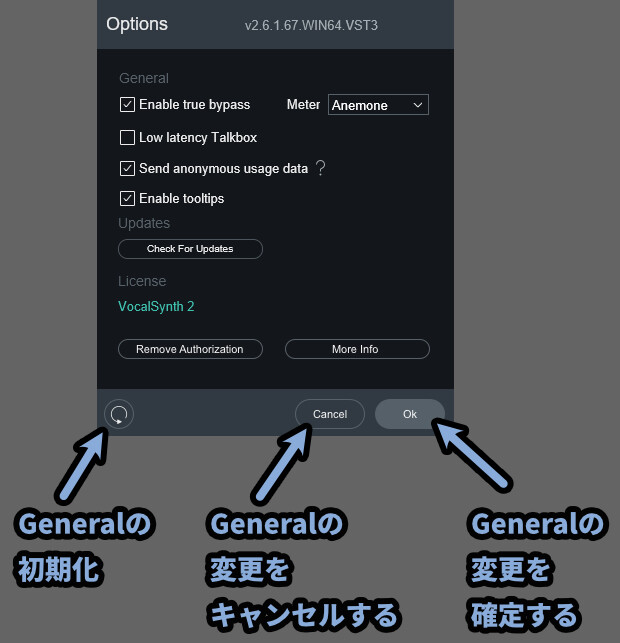
右上の「×」ボタンは「Ok」にしてます。
つまり、Generalの状態が保存されます。
そしたら、元のVocal Synth2画面に戻ります。
ボタンをクリック後、Shiftキーを押すと白い枠表示できます。
(主にブログなどを作る人向け機能?)
白い枠の表示は、何もない所をクリックで消せます。
そして、枠を表示した状態で、他のボタンを操作すると標示バグが起こります。
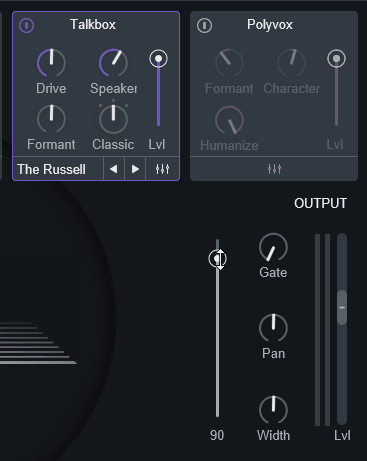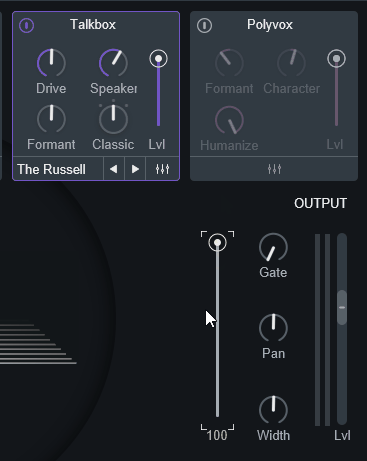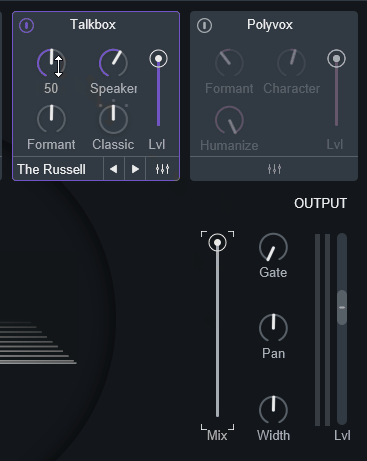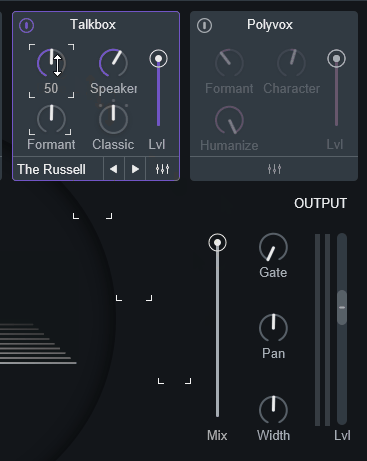
こんな感じの枠の残像みたいなものが残ります。
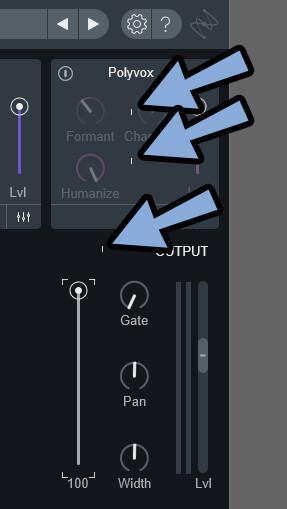
この表示バグは何らかの方法で表示分を更新すれば治ります。
たとえばPolyvox上のバグは、電源ボタンを押すと枠全体の表示が更新されるので消えます。
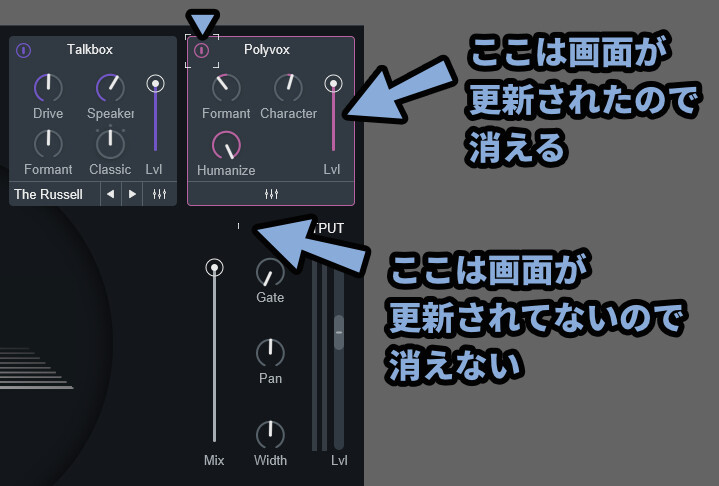
場所によっては表示更新できないところもあります。
このような場所は一度、Vocal Synth 2を閉じて非表示化。
→ 再表示で治してください。
以上が、その他の機能の解説です。
まとめ
今回は、Vocal Synth2の使い方を紹介しました。
・Vocal Synth2は、iZotope社が出してるいろんなエフェクト刺しまくりプラグイン
・5つのボーカルに特化した固有のエフェクトがあるのが特徴
・ボーカルなどのメインとなる音源に入れると良い感じの音になる
・さらに、画面下部には7つの標準的なエフェクトが入っている
・処理負荷が高めなので注意
また、他にも音楽やDTMについて解説してます。



ぜひ、こちらもご覧ください。

コメント