はじめに
今回はStable Diffusion Modelを混ぜる方法を紹介します。
WebUIの用意
モデルを混ぜるにはWebUIが必要です。
これはPythonを使ったローカルの動作環境です。
導入方法はこちらをご覧ください。
⚠ブラウザで動くのでWebUIという名前です。
が、オンラインで公開されてる物ではないです。
自分で1からPythonとGitを使って入れる必要があります。Merge Modelsの導入
こちらのページにアクセス。
Code → Download ZIPを選択。
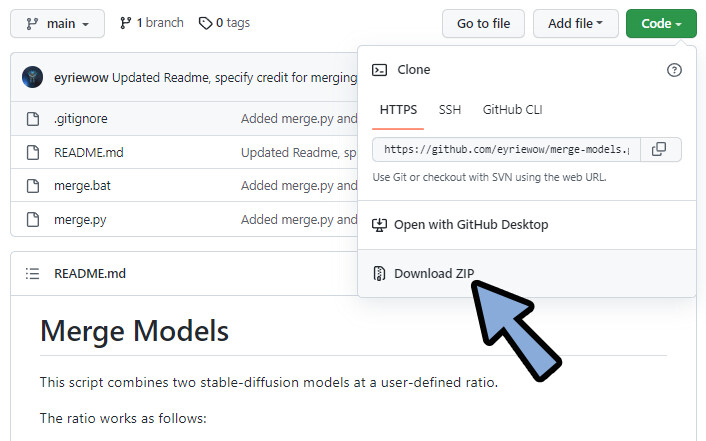
.zipを展開。
展開したファイルをWeb UIのファイルの中に入れます。(直下)
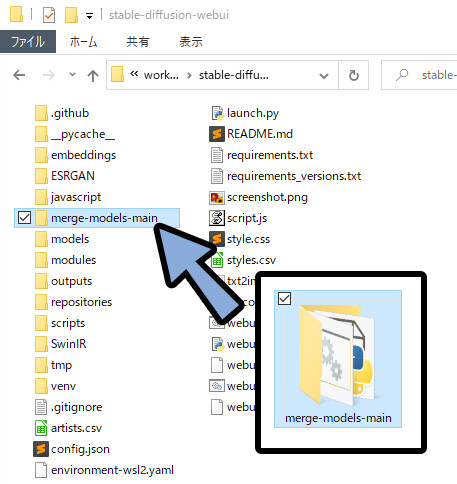
次に、先ほど入れたmerge-models-mainファイルに混ぜたいモデルをコピーで入れます。
何でも大丈夫です。
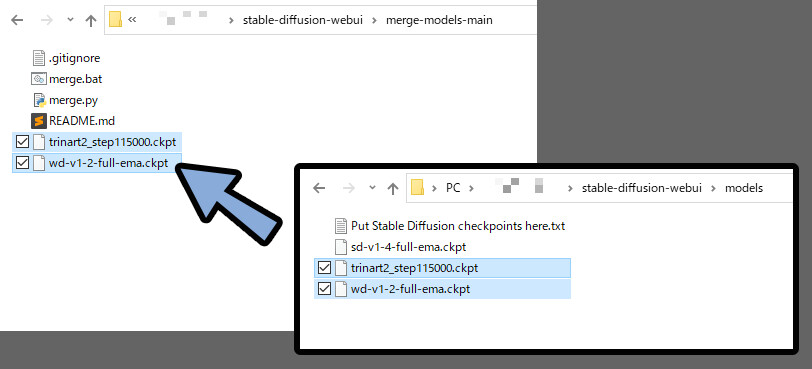
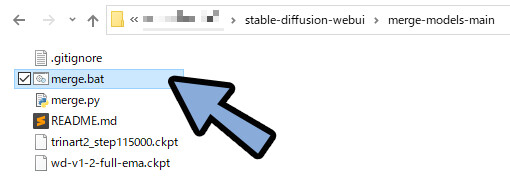
この状態でmerge.batを実行。
保護が出たら詳細情報を選択。
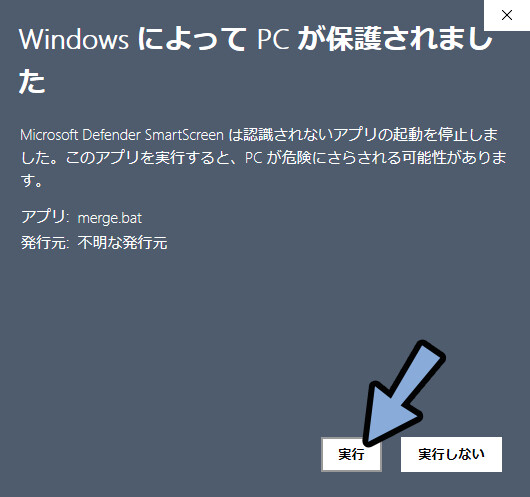
実行を選択。
黒い画面が出てきます。
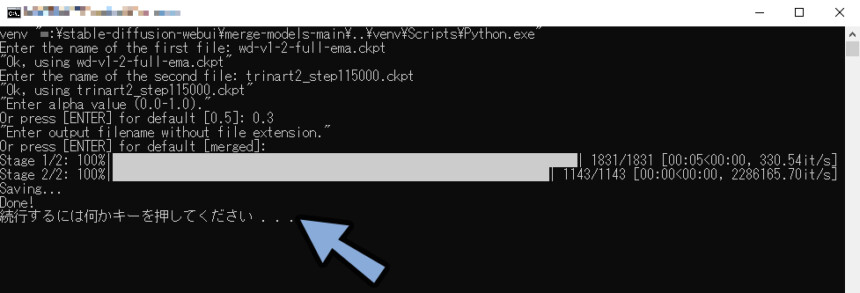
1つ目の混ぜたいモデルの名前を入れます。(”.ckpt”込み)
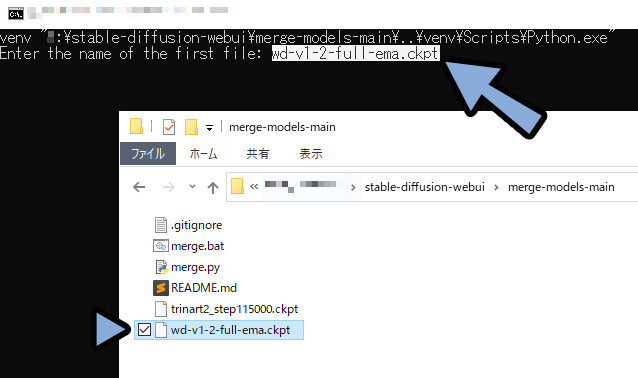
次に2つ目の混ぜたいモデル名を入れます。(”.ckpt”込み)
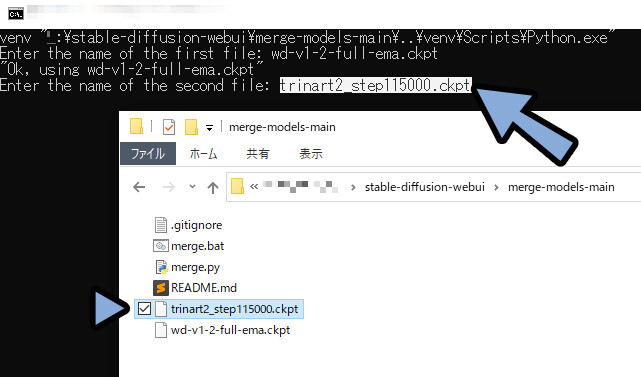
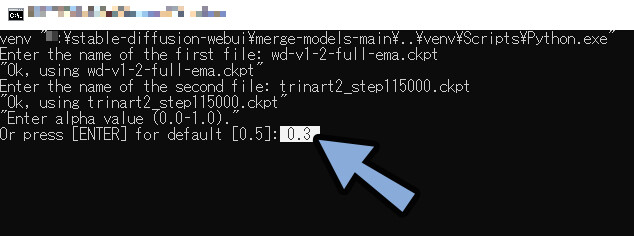
混ぜる割合を設定します。
0.3の場合、 1つ目のモデル:2つ目のモデル=7:3。
0.5より数字が小さいと、1番目のモデルの影響を多く受けます。
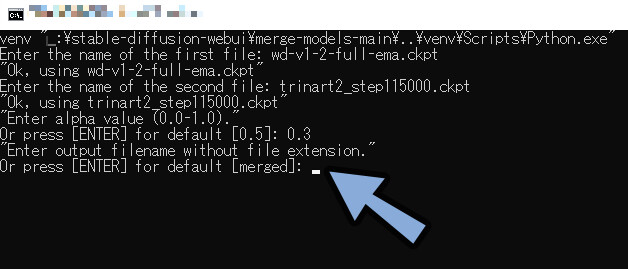
名前を設定するところです。
“空白のまま”ENTERキーを押して実行。
Done!が表示されれば成功です。
merge-modelsのファイルを確認。
するとmerged-**.ckptのファイルができてます。
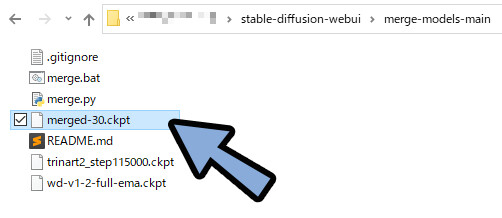
こちらを任意の名前に変更。
これで、モデルを合成が完了です。
混ぜたモデルを使う
使いたいツールに読み込みます。
※ここではNMDK GUIのData → modelsに読み込み。
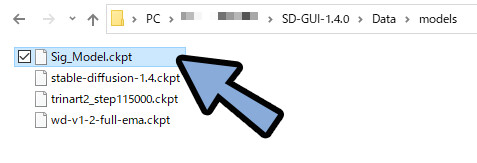
モデルを選択して実行。
キャラの顔生成に強いWaifu Diffusionを70%。

塗りに強いtrinartを30%。

これなら、形の崩れが少ない、綺麗な塗りが出るのでは…?!
と思い実行しましたが…正直微妙でした。
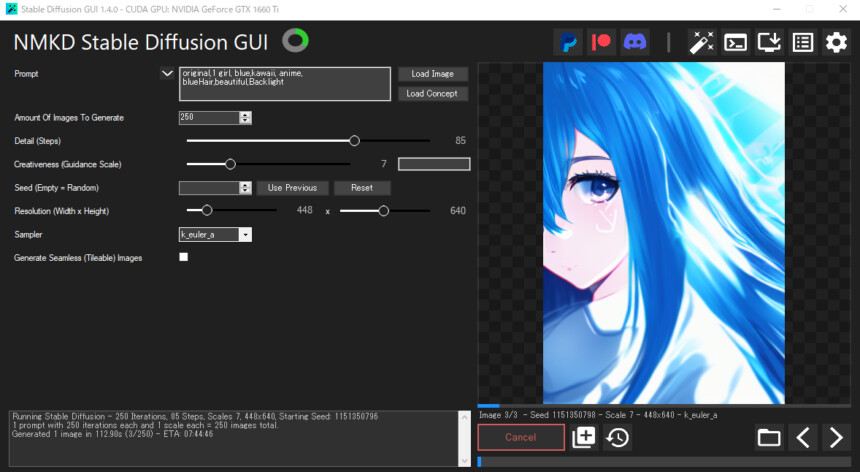
結果…どちらも中途半端に><
中途半端な塗りと、不気味さを越えれなかった形の崩れ。

これを化かしたのが「Concept」と「0.3以下のImage」使用。
そう、その表現。
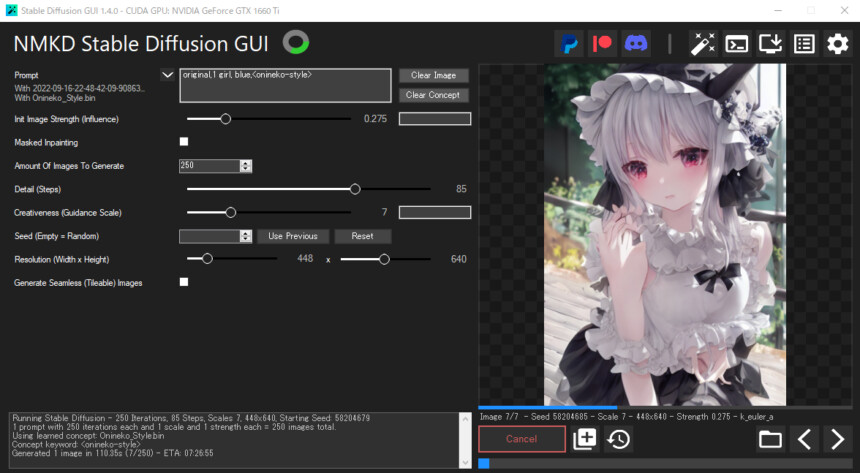
Conceptは任意の画像3~5枚を用意し「物」か「学風」を学習させる機能です。
私の好きなアーティストを学習させると、必要以上にロリが生成される問題が起こりました。

そこで、ロリじゃないイメージを0.3以下で入力。
するとかなり理想的な仕上がりになりました。
0.3以下のImage入力は、構図を残しながら原形を大きく変えてくれるので便利。

そう、ずっとこれを求めていた(他の生成例)
原因として考えられるのは
・Waifu Diffusionを70%+trinartを30%=形も塗りも中途半端。
・Conceptでこの中途半端さを補正。
・塗りが中途半端だからこそ、Conceptの塗り影響を大きく受けて綺麗になった
・形の中途半端さはConceptを入れたことで補正された
と思います。かなり奇跡です。
まとめ
今回はStable Diffusion Modelを混ぜる方法を紹介しました。
・Merge Modelsで混ぜることができる
・これを使うにはWebUIが必要
・Conceptとの併用が効果的
また、他にも人工知能の作画について解説してます。



ぜひ、こちらもご覧ください。

コメント
やっぱりload conceptの効果も実感できるほどなんですね。
同じキャラや同じ塗りスタイルの画像を100枚以上で学習して、作れば確実に目的のそのキャラ違和感を少なく出力できそうですよね。
そう考えるとstable diffussionのモデルの学習量を考えると、もはや学習枚数とスタイルの数が過剰すぎてごちゃごちゃになるのも納得ですね。
恐らく誰かが、簡単にconceptをローカルで作れるツールを近いうちに開発すると思いますが、その時が楽しみです。
指示テキストが少ない状態のconceptは強いですね…
逆に、細かく指示をしてしまうと弱まります。
私は現状でも満足してますが、今後の発展を考えると楽しみです。